初学爬虫2: 正则表达式一些知识点+京东商城物品排名+名称+价格的爬取 (re+bs4+requests)
我的爬虫入门看的是中国慕课上 北京理工大学的一个关于python爬虫入门的国家精品课,在这里安利一哈,然后本文出现的一部分截图也是截取视频里面的内容。
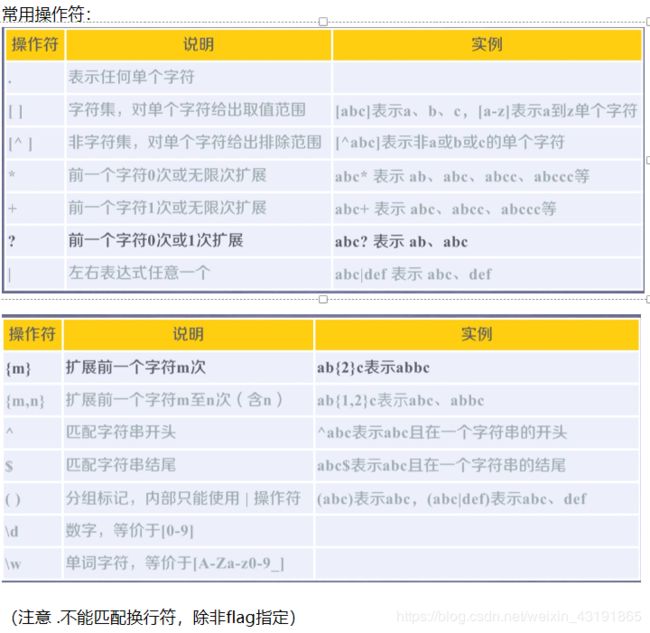
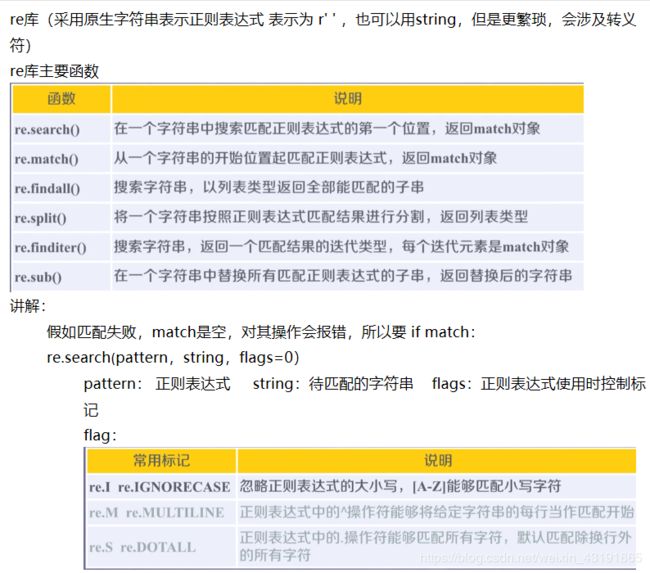
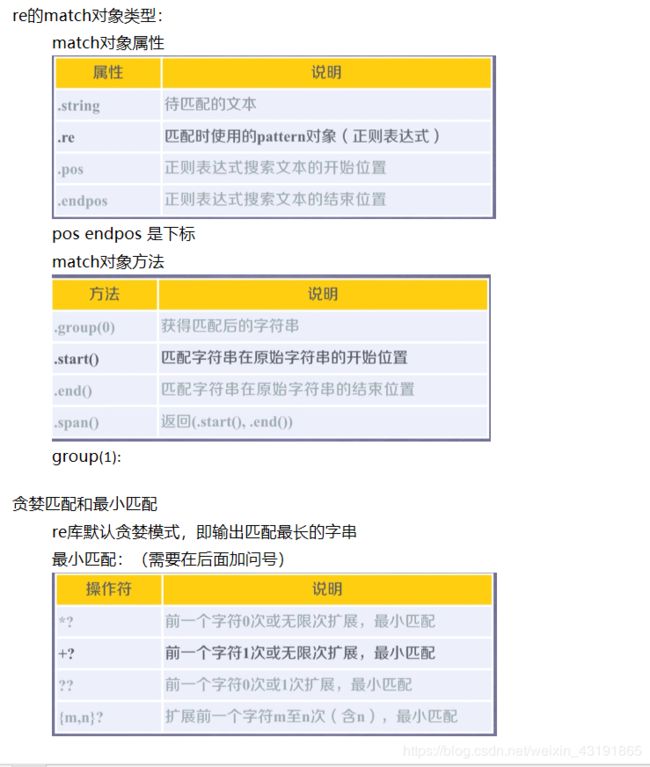
正则表达式一些知识点:
正则表达式(regular experssion / regex / re) 在文本处理中很常用,可以用于表达文本特征(病毒文件),查找,替换字符串等
下面是我做的的笔记的截图

实战: 爬取京东商品 排名+名称+价格
备注:本来课程的实战是爬取淘宝的,但是淘宝似乎升级了系统,用现在我知道的知识没办法爬取了,所以我选择京东,淘宝的话以后再爬(确信)
首先进入京东查看关于搜索关键词是否是附加到url的形式发送,我选择关键词:鼠标,发现确实是这样:
第一页:![]()
keyword那里就是,然鹅好像后面带有很多奇奇怪怪的东西,因此多翻找规律,发现确实是有规律(省略)
然后分析网页原代码,定位商品的位置(右键--检查--![]() ) 我用的是谷歌浏览器
) 我用的是谷歌浏览器
选中想看的地方,观察源代码
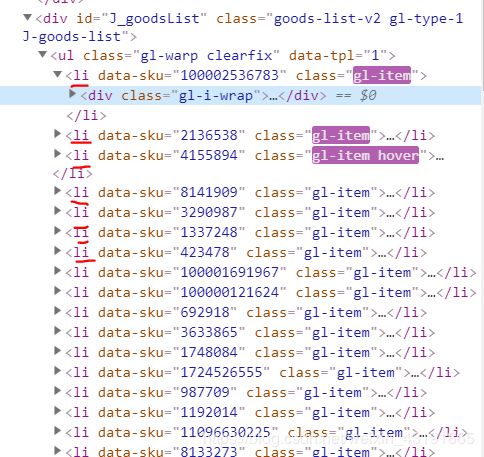
可以看到一块块商品就再li标签里面,这个时候查看网页原代码,观察到其父节点 id=J_goodsList 通过ctrl+f 的查找功能定位到id= j_goodsList这个地方

太好了,我们可以通过id定位到这个地方,因此初定使用bs4 定位到这个地方
然后在li标签里面找商品名字,价格
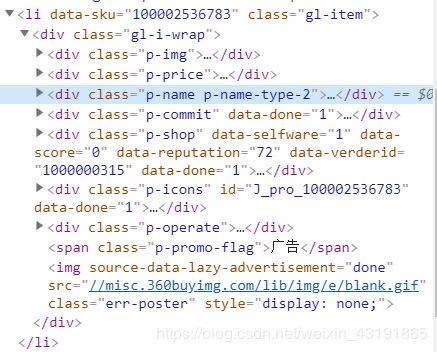

其实人家的class名字已经起的很直白了,价钱就藏在p—price里面,名字就在 p-name p-name-type-2 里面
这个时候检查其他的li模块,发现高度一致,因此我们可以
使用bs4 找到 j_goodsList 然后找其子节点,将li节点遍历出来,分别找其class= p—price class= p-name p-name-type-2 这两个,然后再使用正则表达式将具体内容抠出来
我们对bs4找出来的东西进行进一步观察
我们先将需要使用正则表达式的地方找出来
价格:
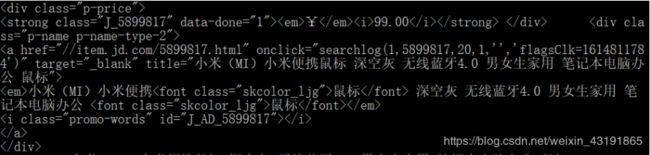
看到那个99.00了吗,观察其左右,我们可以使用(.*?) 的正则表达式,此时一定不能使用贪心模式,假如不使用贪心模式当两个 嵌套一起的时候,比如:
abcde
结果就是: abcde
名字:

看到这个title了吗,往后接的是不是名字呢?我们可以先当它是,那么就很简单了,因为title 只在这里出现,我们可以以他为标准使用正则表达式: title="(.*?)"
只可惜这里并不是真的答案
学过网页编程的应该知道,这个a标签的意思是:将鼠标移到它上面的时候显示的东西,并不是实际显示的内容,假如这两者不一样的话,比如:

其实商品名称不在这里,我们需要找其他的地方。


其实是在下面em标签里面断断续续拼装而成,那怎么提取呢,我们对比不同的几个商品,看看能不能找到什么共同的规律
![]()
![]()
这几个对比起来发现: 长短不一,关键字夹杂在font标签里面和标签之间,这种情况下我认为使用正则表达式找出夹在> < 之间的汉字然后拼起来即可

就像这样,search_name就是拼起来的结果
代码:
import re
import requests
import bs4
cnt=1
def get_html(url):
try:
h={'user-agent':'Mozilla/5.0'}
html=requests.get(url,headers=h)
html.encoding=html.apparent_encoding
html.raise_for_status()
return html.text
except:
return "wrong"
def solve(html,lis_pri,lis_nam):
soup=bs4.BeautifulSoup(html,'html.parser')
all=soup.find(id="J_goodsList").contents
all=all[0]
mix=all.children
#print(type(all))
for i in mix:
if(isinstance(i,bs4.element.Tag)):
price=i.find(class_='p-price')
name=i.find(class_='p-name p-name-type-2')
name=name.find(name='em') #price 不需要 加这句
sto_name=re.findall('>.*?<',str(name))
search_name=""
for i in sto_name:
search_name+=i[1:-1]
search_pri=re.search('(.*?)',str(price))
if( search_pri and search_name):
lis_pri.append(search_pri.group(1))
lis_nam.append(search_name)
output(lis_pri,lis_nam)
def output(lis_pri,lis_nam):
flag=range(0,len(lis_pri))
global cnt #!!
with open("res.txt",'a',encoding='utf-8') as f:
for i in flag:
f.write("{:^10}{:^150}{:^50}\n".format(cnt+i,lis_nam[i],lis_pri[i],chr(12288)))
f.close()
cnt+=len(lis_pri)
Q=input("input your q: ")
page=input("输入你想要获取多少页的数据: ")
page=int(page)+1
for i in range(1,page):
insert=i*2
insert=str(insert)
url="https://search.jd.com/Search?keyword="+Q+"&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page="+insert+"&s=58&click=0"
#html=get_html("https://search.jd.com/Search?keyword=%E9%BC%A0%E6%A0%87&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E9%BC%A0%E6%A0%87&page=1&s=1&click=0")
html=get_html(url)
if(html=='wrong'):
print("出现错误")
else:
lis_pri=[]
lis_nam=[]
solve(html,lis_pri,lis_nam)