python3爬虫系列之使用requests爬取LOL英雄图片
我们最终目的就是要把抓取到的图片保存到本地,所以先写一个保存图片的方法(可以保存任何二进制文件)。注意在windows下文件命名包含/ | ?可能会发生错误,有的英雄皮肤名称确实包含/,所以这里使用正则表达式替换下。方法包含文件路径,文件名称,文件内容,简单粗暴一些。
def save_image(image_dir,image_name,image_content):
if not os.path.exists(image_dir):
os.makedirs(image_dir)
try:
hero_image_path = os.path.join(image_dir,re.sub(r'[/|?]','',image_name))
with open(hero_image_path, 'wb') as image:
image.write(image_content)
except Exception as e:
print('{}保存失败,错误原因:{}'.format(hero_image_path,e))
爬取数据就是模拟浏览器请求,经过查看英雄联盟英雄资料页面,都是get请求,这里把使用requests请求写到一个函数里,减少些重复代码。这里把headers放到self里,奔着面向对象的思路。
def send_get(self,url):
try:
resp = requests.get(url,headers = self.headers)
assert resp.status_code == 200,'{}请求失败'.format(url)
return resp
except Exception as e:
print(e)
return None
下面F12再分析一下英雄联盟英雄资料页面数据,我们的思路是先在英雄列表得到所有的英雄信息,然后依次循环爬取单个英雄的信息,得到单个英雄的所有皮肤。
如果直接爬取英雄列表页面地址url,会发现是获取不到英雄列表数据的,因为页面是异步加载的,也可以看作是前端和后台数据分离的,你爬或不爬,页面就在那里,英雄列表数据是动态请求的。
仔细看F12里的网络请求,可以看到有一个js请求(前端页面请求后台数据通常都是触发js事件),地址如下:
https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js
看一下这个请求的响应信息,可以看到就是页面的英雄列表信息,所以我们向这个地址发起请求获取所有英雄的列表。大概就是酱紫:

随手截了一个图,最后一个英雄也是我的最爱,曙光女神(日女),再看下单个英雄的页面,需要找到单个英雄的地址,然后逐个去请求获取数据。女神的页面数据是酱紫的:
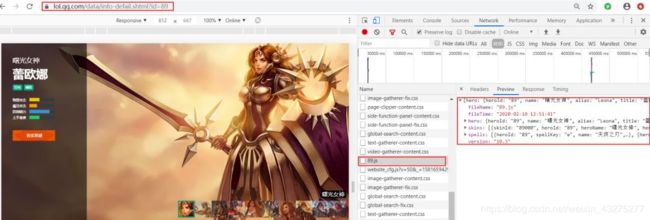
单个英雄的地址如下:
https://game.gtimg.cn/images/lol/act/img/js/hero/89.js
#等待动态拼接
https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js
英雄列表数据有了,单个英雄的请求地址也找到了,下面就可以大胆地发起请求了,可以看到英雄列表和单个英雄信息返回的都是json格式的数据,就是python中的字典类型。
最后在单个英雄的返回数据中找到皮肤的图片地址,发起请求获取图片内容即可,然后调用之前写好的保存图片的方法即可。
def process_hero(self,**hero_info_dict):
hero = hero_info_dict['hero']
skins = hero_info_dict['skins']
for skin in skins:
# 获取图片内容
if skin['mainImg']:
skin_content = self.send_get(skin['mainImg']).content
hero_image_name = '{}.jpg'.format(skin['name'])
hero_image_dir = os.path.join(self.base_path, hero['name'] + hero['title'])
self.save_image(hero_image_dir,hero_image_name,skin_content)
print('hero:{},skins:{}张,处理完成'.format(hero['name'],len(skins)))
time.sleep(1)
完整代码已经扔到小编的github上了,欢迎来搞,一起开撸。
https://github.com/maidepiao/xiaomai_python3_little_by/blob/master/爬虫/英雄联盟图片爬取.py
英雄联盟所有英雄数据就这样轻轻松松爬取好了,这里以角色英雄名称为文件夹保存英雄皮肤,结果如图所示:
