Pytorch识别手写体数字的简单实现
前言
一般机器学习框架都使用MNIST作为入门。就像"Hello World"对于任何一门编程语言一样,要想入门机器学习,就先要掌握MNIST。

MNIST 数据集可在MNIST官网 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
安装Pytorch Anaconda 与Cuda
PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络,这是很多主流深度学习框架比如Tensorflow等都不支持的。Pytorch官网:https://pytorch.org/
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。 因为包含了大量的科学包,Anaconda 的下载文件比较大(约 531 MB),如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)Anaconda官网https://www.anaconda.com/
Cuda(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 Cuda可以为我们在pytorch上面写的代码进行加速运算,提高神经网络运行速率。Cuda官网https://developer.nvidia.com/cuda-downloads
可视化作图
既然我们是学人工智能的,那么干瘪瘪的数字也许让你提不起兴趣,对于数据的可视化就显得尤为重要,他们可以将无数的数字转换成有着对应关系的函数图。而众所周知的科学作图库首当其冲的就是matplotlib同学了,当然你要用Echarts也不是不行,根据个人喜爱吧。安装库的方法我之前有很多博客有所提到,萌新同学可以去瞧一瞧。Of course,如果你安装好了Anaconda,这一切都不是小事,因为它已经帮你把python中大部分热度很高的库都安装好了。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import torch
from matplotlib import pyplot as plt
def plot_curve(data):#画曲线
fig = plt.figure()
plt.plot(range(len(data)), data, color='blue')
plt.legend(['value'],loc='upper right')
plt.xlabel('step')
plt.ylabel('value')
plt.show()画完这个梯度损失关系曲线图之后还有你识别的图片
def plot_image(img,label,name):#画图片
fig=plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(img[i][0]*0.3081+0.1307,cmap='gray',interpolation='none')
plt.title('{}:{}'.format(name,label[i].item()))
plt.xticks([])
plt.yticks([])
plt.show()def one_hot(label,depth=10):
out = torch.zeros(label.size(0),depth)
idx = torch.LongTensor(label).view(-1,1)
out.scatter_(dim=1,index=idx,value=1)
return out神经网络搭建
导入基本库
torch.nnModule:创建一个可调用的对象,其行为类似于一个函数,但也可以包含状态(例如神经网络层权重)。 它知道它包含哪些参数,并且可以将所有梯度归零,循环遍历它们更新权重等。Parameter:tensor的包装器(wrapper),它告诉Module它具有在反向传播期间需要更新的权重。 只更新具有requires_grad属性的tensor。functional:一个模块(通常按惯例我们存入到F命名空间中),它包含激活函数,损失函数等,以及非状态(non-stateful)版本的层,For example卷积层(Convolutional layer)和线性层(Linear Layer)。
torch.optim是一个实现了各种优化算法的库。大部分常用的方法得到支持,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法。
torch.optim:包含SGD等优化器,可在后向传播步骤中更新Parameter的权重。Dataset:带有__len__和__getitem__的对象的抽象接口,包括PyTorch提供的类,如TensorDataset。DataLoader:获取任何Dataset并创建一个返回批量数据的迭代器
torchvision主要包括一下几个包:
- vision.datasets : 几个常用视觉数据集,可以下载和加载,这里主要的高级用法就是可以看源码如何自己写自己的Dataset的子类
- vision.models : 流行的模型,例如 AlexNet, VGG, ResNet 和 Densenet 以及 与训练好的参数。
- vision.transforms : 常用的图像操作,例如:随机切割,旋转,数据类型转换,图像到tensor ,numpy 数组到tensor , tensor 到 图像等。
- vision.utils : 用于把形似 (3 x H x W) 的张量保存到硬盘中,给一个mini-batch的图像可以产生一个图像格网。
import torch
from torch import nn
from torch.nn import functional as F
from torch import optim
import torchvision
from matplotlib import pyplot as plt
from draw import plot_curve,plot_image,one_hot载入MNIST数据集
具体事宜写在代码注释中
batch_size = 512#一次处理多少张图片
#加载数据集,利用torchvision
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data',train=True,download=True,#train是设置为训练数据集,ownload的意思是如果自己家里没有mnist数据集就从网上下
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),#将下载的文件转换为Tenser格式
torchvision.transforms.Normalize(#正则化,提高性能
(0.137,),(0.3081,))#减去0.137,除以0.3081,使其可以在0附近均匀分布
])),
batch_size=batch_size,shuffle=True)#shuffle高速系统是否对数据打散
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/',train=False,download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,),(0.3081,))
])),
batch_size=batch_size,shuffle=False)
x,y = next(iter(train_loader))
print(x.shape,y.shape,x.min(),x.max())
plot_image(x,y,'img sample')构建网络
MNIST数据集中全部都是28*28的像素图片,所以我们输入曾就设置fc1,隐藏层中再把256的像素转换为64,因为数字是0~9,所以输出层设置为10
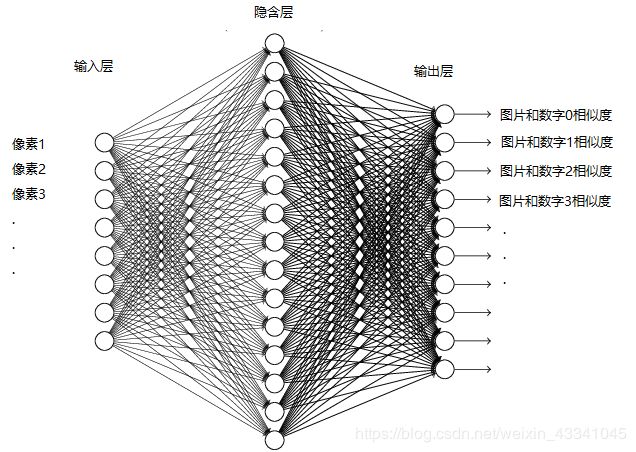
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.fc1 = nn.Linear(28*28, 256)
self.fc2 = nn.Linear(256,64)
self.fc3 = nn.Linear(64,10)
def forward(self, x) :
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
optimizer = optim.SGD(net.parameters(),lr=0.01,momentum=0.9)在这里我们选择了随机梯度下降也就是SGD优化器。由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。随机梯度下降法(Stochastic Gradient Descent)正是为了解决批量梯度下降法这一弊端而提出的。
优点:训练速度快;
缺点:准确度下降,并不是全局最优;不易于并行实现。
函数写为如下形式:
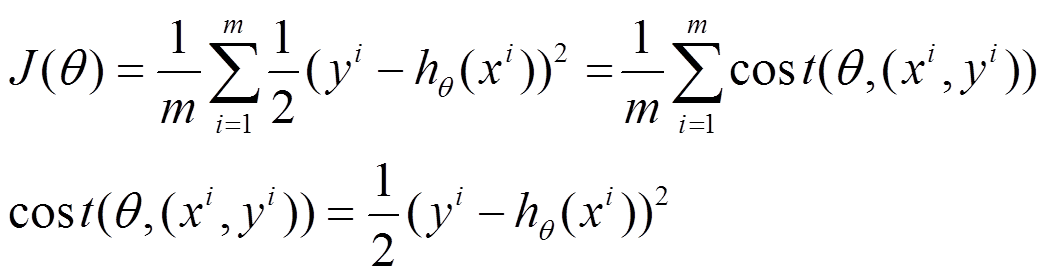
利用每个样本的损失函数对θ求偏导得到对应的梯度,来更新θ
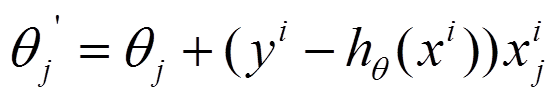
在机器学习、深度学习中使用的优化算法除了常见的梯度下降,还有Adadelta,Adagrad,RMSProp 等几种优化器。对于优化算法,优化的目标是网络模型中的参数θ(是一个集合,θ1、θ2、θ3 ......)目标函数为损失函数L = 1/N ∑ Li (每个样本损失函数的叠加求均值)。这个损失函数L变量就是θ,其中L中的参数是整个训练集,换句话说,目标函数(损失函数)是通过整个训练集来确定的,训练集全集不同,则损失函数的图像也不同。那么为何在mini-batch中如果遇到鞍点/局部最小值点就无法进行优化了呢?因为在这些点上,L对于θ的梯度为零,换句话说,对θ每个分量求偏导数,带入训练集全集,导数为零。
对于SGD/MBGD而言,每次使用的损失函数只是通过这一个小批量的数据确定的,其函数图像与真实全集损失函数有所不同,所以其求解的梯度也含有一定的随机性,在鞍点或者局部最小值点的时候,震荡跳动,因为在此点处,如果是训练集全集带入即BGD,则优化会停止不动,如果是mini-batch或者SGD,每次找到的梯度都是不同的,就会发生震荡,来回跳动。
迭代训练
train_loss=[]
for epoch in range(3):#迭代3遍
for batch_size,(x,y) in enumerate(train_loader):#所有数据集迭代
x = x.view(x.size(0),28*28)
out = net(x)
y_onehot = one_hot(y)
loss = F.mse_loss(out, y_onehot)#均方差
optimizer.zero_grad()#清零梯度
loss.backward()#计算梯度
optimizer.step()#更新梯度
train_loss.append(loss.item())#把tensor数据类型取出转换正常numpy类型
if batch_size % 10 ==0:
print(epoch,batch_size,loss.item())
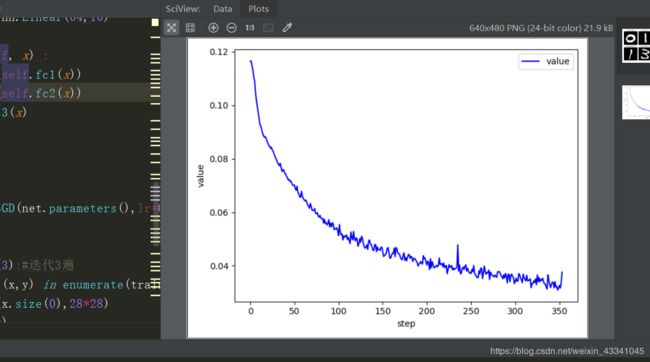
plot_curve(train_loss)#打印训练到最后对于图像的识别结果还是很不错的
画出来的损失函数图像
后序
本博客于第一天学习pytorch之后所写,也是萌新一位,文中有诸多瑕疵还望各位海涵,曾粗笔写过利用Numpy编写BackPropagation神经网络https://blog.csdn.net/weixin_43341045/article/details/105243732那也是我第一次接触神经网络相关知识,若有兴趣或高深见解欢迎前来指教一二。
鄙人仅为一名普普通通大二学生,才学浅出,来此各地高人聚集处书写浅见,还望各位前辈高人多多指点海涵。我们诚邀各地有志之士加入我们的代码学习群交流:871352155(无论你会C/C++还是Java,Python还是PHP......有兴趣我们都欢迎你的加入,不过还请各位认真填写加群信息。群内目前多为大学生,打广告的先生女士就请不要步足了。我们希望有远见卓识的前辈能为即将步入社会的初犊提出建议指引方向。)谢谢。