基于Python语言的PUBG游戏数据可视化分析系统
[success]写于2019年大作业[/success]
博客链接:https://www.iamzlt.com/?p=299
代码链接请到博客链接内查看。
摘要
随着网络技术的兴起和普及,网络游戏产业异军突起,成为全球重要的文化产业之一。本文以PUBG游戏为例,基于Python语言通过爬取直播平台和论坛数据,实现对其流量和评价的抓取与分析,并通过大数据对局内数据进行统计与分析,探究PUBG游戏的玩法与攻略。系统基于Python语言,使用requests、pandas、matplotlib、worldcloud库进行实现。系统分为游戏分析模块,局内数据分析模块和直播平台数据分析模块,本文将从需求分析、系统设计、系统实现等多方面对该系统进行介绍。系统开发背景
- 游戏开发者角度
- 玩家角度
- 直播平台角度
Python在爬虫、数据分析和交互、探索性计算以及数据可视化等方面都有非常成熟的库和活跃的社区,使python成为数据处理任务重要解决方案。同时Python具有低成本、高效率、高可靠性的优点。因此针对以上问题,以PUBG游戏(图1.1)为例,设计了基于Python语言通过爬取直播平台和论坛数据,实现对其流量和评价的抓取与分析,并通过大数据对局内数据进行统计与分析,探究游戏的玩法与攻略的系统,并有效的解决了上述及其他众多问题。

系统相关技术介绍
系统基于Python语言,使用requests、pandas、matplotlib、worldcloud库进行实现,下面将对其进行详细介绍。2.1 Python语言
1.Python拥有一个巨大而活跃的科学计算社区Python在数据分析和交互、探索性计算以及数据可视化等方面都有非常成熟的库和活跃的社区,使python成为数据处理任务重要解决方案。在科学计算方面,python拥有numpy、pandas、matplotlib、scikit-learn、ipython等等一系列非常优秀的库和工具,特别是pandas在处理中型数据方面可以说有着无与伦比的优势,正在成为各行业数据处理任务的首选库
2.python拥有强大的通用编程能力
不同于R或者matlab,python不仅在数据分析方面能力强大,在爬虫、web、自动化运维甚至游戏等等很多领域都有广泛的应用。这就使用一种技术完成全部服务成为可能。
2.2 requests库
Requests 是用 Python语言编写,基于urllib,采用Apache2 Licensed 开源协议的 HTTP 库。下面对HTTP和requests库进行分别介绍:1.HTTP协议
HTTP,超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法,HTTP是一种基于"请求与响应"模式的、无状态的应用层协议。HTTP协议采用URL作为定位网络资源的的标识符。
2.requests库
requests库6个主要方法如表2.1所示。对于requests库的使用,通常使用 heeaders作为HTTP定制头部信息,隐藏爬虫信息,模拟浏览器的头部信息。通过get方法获取相应网页,并用re库中的方法进行解析,将内容传入到字典中。
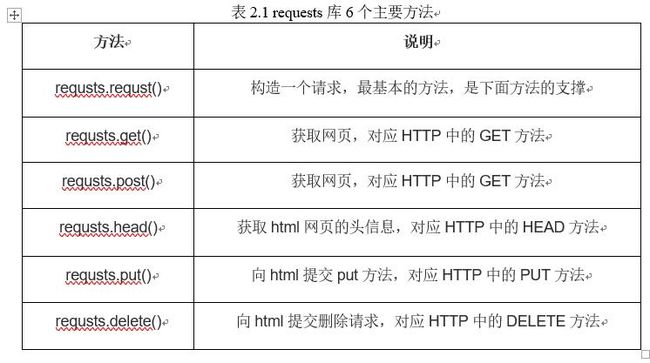
2.3正则表达式库re
re库是python的标准库,采用raw string类型表示正则表达式,表示为:r’test’。原生字符串(raw string)不包含转义符的字符串。
re`模块提供了一系列功能强大的正则表达式 (regular expression) 工具,起主要函数如表2.2所示,它们允许你快速检查给定字符串是否与给定的模式匹配 (使用 match 函数),或者包含这个模式 (使用 search 函数)正则表达式是以紧凑的语法写出的字符串模式。
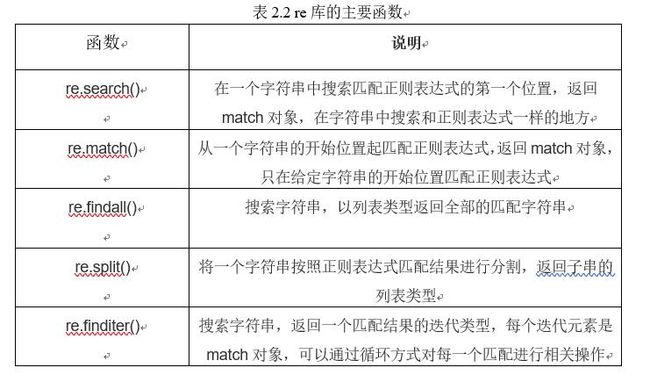
re模块中的常用语法如图2.1所示
2.4 Matplotlib库
Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形 .通过 Matplotlib,开发者可以仅需要几行代码,便可以生成绘图,直方图,功率谱,条形图,错误图,散点图等。
其中matplotlib.pyplot是绘制各类可视化图形的命令子库,相当于快捷方式。其常用函数如表2.3所示。导入方式如下:
import matplotlib.pyplot as plt
2.5 NumPy库
NumPy库使用Python进行科学计算,尤其是数据分析时,所用到的一个基础库。它是大量Python数学和科学计算包的基础。pandas库专门用于数据分析,充分借鉴了Python标准库NumPy的相关概念。1.NumPy库的核心
整个NumPy库的基础是ndarray(即N维数组)对象。它是一种由同质元素组成的多维数组 ,元素数量是事先指定好的。同质指的是几乎所有元素的类型和大小都相同。事实上,数据类型由另外一个叫做dtype的NumPy对象来指定;每个ndarray只有一种dtype类型。数组的维数和元素数量由数组的型来确定,数组的型由N个正整数组成的元组来指定,元组的每个元素对应每一维的大小。数组的维统称为轴,轴的数量被称为秩。
Numpy数组的另一个特点是大小固定,也就是说,创建数组时一旦指定好大小,就不会再发生改变。这与Python的列表有所不同,列表的大小是可以改变的。定义ndarray最简单的方式是使用array( )函数,以python列表作为参数,列表的元素即是ndarray的元素。
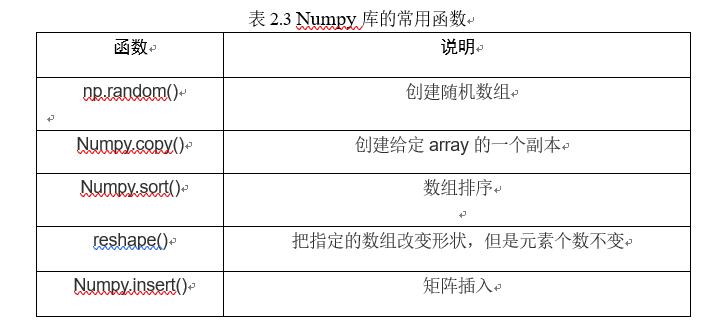
2.NumPy库的常用函数
NumPy库中常用函数如表2.3所示。
2.6 Pandas库
1.Pandas库的简介Pandas是Python第三方库,提供高性能易用数据类型和分析工具。导入方式如下:
import pandas as pdPython Data Analysis Library或pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
Pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
2.Pandas库常用函数与方法
Pandas库中常用函数如表2.4所示。

系统分析与设计
3.1系统功能模块组成
本系统主要由游戏评价分析模块,局内数据分析模块和直播平台数据分析模块等模块组成,具体的功能模块组成如图3.1所示。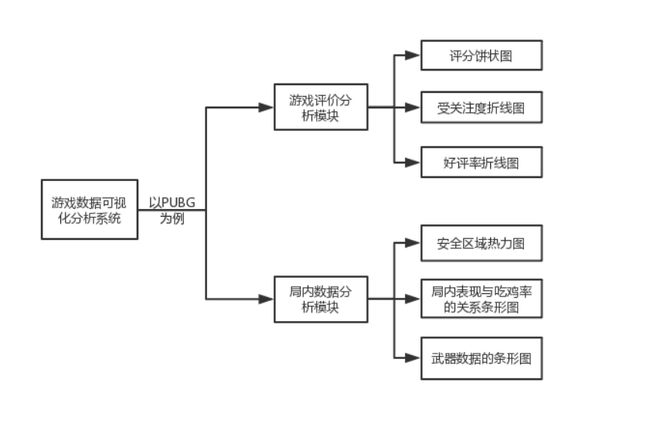
3.2 游戏评价分析模块需求和设计
系统功能分析是在系统开发的总体任务的基础之上完成的。游戏评价分析模块主要有以下功能: 对网络中用户对PUBG游戏的评分和评价进行爬取、解析并写入到文件,通过分析数据,制作统计图和词云进行可视化展示。这些方面对于游戏开发者而言具有重大意义。- 头文件伪装
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
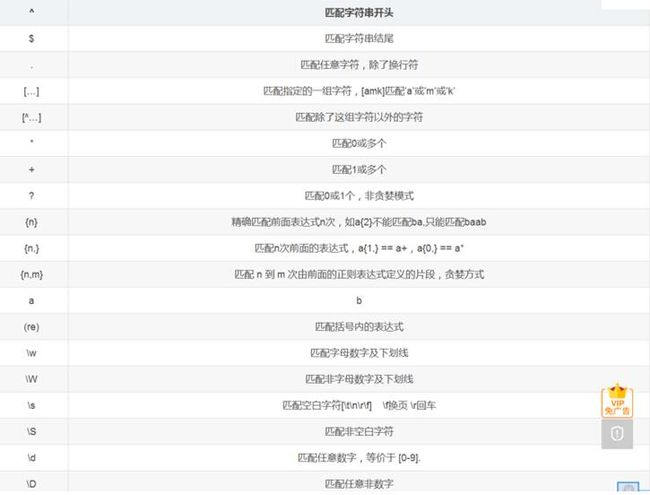
- 正则表达式的提取

此外正则表达式的常用语法如图2.1所示。
- 数据的爬取与写入文件
try:
url = "https://www.douban.com/game/27005453/{}".format(offset)
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.text
return None
except:
return None
- 可视化分析与展现
3.3 局内数据分析模块需求和设计
玩家玩游戏时,除了娱乐放松之外,如何获得游戏的胜利也是玩家关注的问题之一。系统针对此问题,该模块将对本地文件中的局内对战数据进行提取,进行分析,并可视化展示。- 游戏局内数据的获取
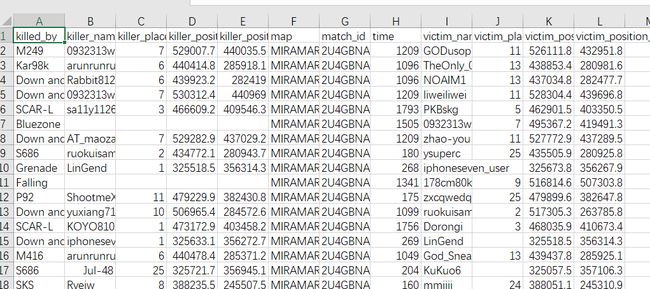
下载的文件中具有超过1亿个PUBG匹配数据,数据主要分为两部分。一个是比赛中玩家的统计数据,另一个是玩家被杀的数据。部分数据如图3.5所示。
- 数据的提取和处理
for file in range(1,2):
death_1 = pd.read_csv(r'deaths\kill_match_stats_final_{}.csv'.format(file), nrows=5000000)
death = death_0.merge(death_1, how='outer')
last_seconds_erg=death.loc[(death[‘map’]==‘ERANGEL’)&(death[‘killer_placement’]==1), :].dropna()
- 可视化分析与展现
4系统实现
4.1 游戏评价分析模块实现
本模块将对网络中用户对PUBG游戏的评分和评价进行爬取、解析并写入到文件,通过分析数据,制作统计图和词云进行可视化展示。该模块流程如图4.1所示。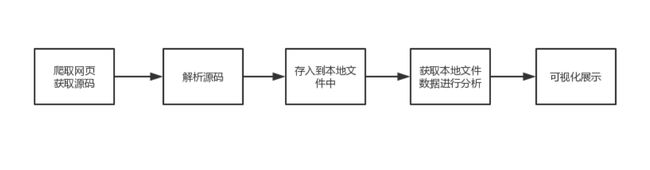
4.1.1 模块实现界面
在该模块运行后,系统首先会对豆瓣网进行爬取,对玩家对PUBG的评分和评价进行收集并写入文件。在系统爬取的过程中会显示爬取的进度(如图4.2所示)。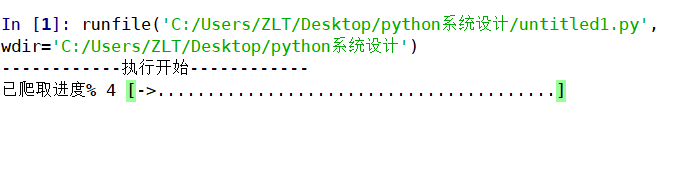
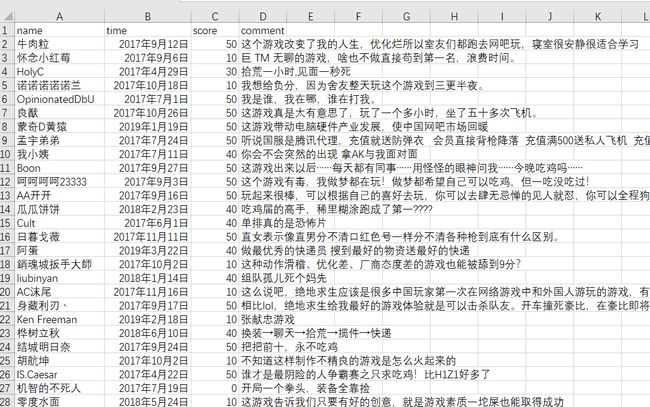
在系统爬取完成后,会将爬去的数据写入Comments.csv文件中(如图4.3所示)。其保存的数据如图4.4所示,分为‘name’、‘time’、‘score’和‘comment’四列,代表用户名、评论时间、评分和评分内容。
在系统完成上述功能后,系统会对文件中的数据进行分析,探究玩家对PUBG的评价和喜好。例如对用户评分数据的分析,如图4.5所示,可以通过饼状图的方式可视化展现。
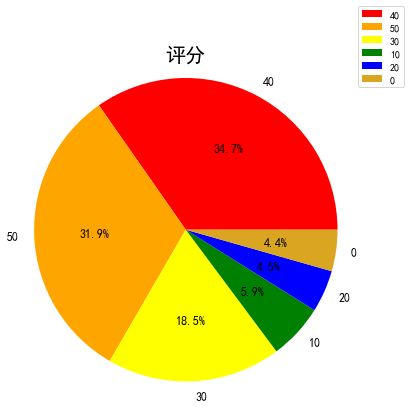
通过饼状图可以看到,玩家五星评分的占比为31.9%,四星的评分占比为34.7%,两者占全部的66.6%,可以看出大多数用户对PUBG这款游戏持有好评态度。
系统除对用户评分的数据进
行分析之外,还对人们对PUBG这款游戏的关注度进行分析并通过折现图展现其关注度随时间的变化(如图4.6所示)。从图中可以看到,自2017年3月游戏发布以来,游戏关注度逐渐增加,在2017年9月份达到了最高。随后PUBG这款游戏的关注度便随时间的增加而减少。
从实际境况来看,在2017年9月份左右PUBG这款游戏在中国引发了一股浪潮,与系统分析相符合。对于游戏开发者而言,可以探究这款游戏的关注度为何在2017年9月份达到顶峰后关注度一路下滑。
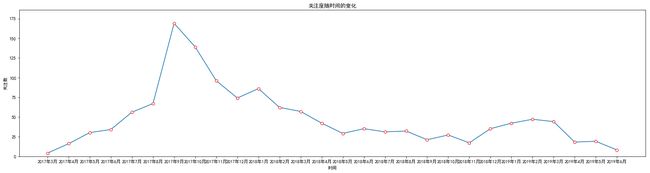
此外,系统还对PUBG的好评率随时间的变化做出了分析(如图4.7所示)。从图中可以看到,玩家对PUBG这款游戏的好评率基本维持在50%以上。2019年6月份因样本量较小,不具有参考价值。但整体来看,游戏的好评率随时间的变化略微下降。
对于游戏本身而言,自游戏推出后游戏经过多次更新与升级,每次给玩家带来的体验有所不同。游戏开发者可以通过分析好评率下降与游戏更新内容的关系,从而不断的做出调整。
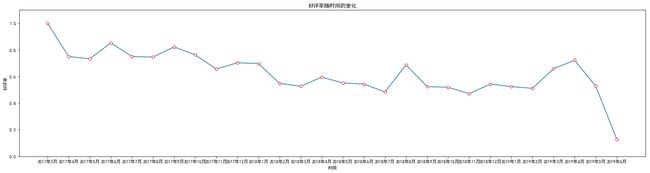
同时,为了探究玩家对PUBG好评与差评的原因,系统还对用玩家的评论内容做出了分析,并通过制作词云的方式(如图4.8所示)进行展现。
 对于高分评价内容的词云如图4.9所示。从图中可以看到玩家对游戏的‘刺激性’的游戏体验,‘大逃杀’的游戏模式,‘战术’、‘开黑’等游戏方式给予‘上瘾’、‘好玩’、‘不错’等肯定。但同时在高分评价的内容中,也提出了存在外挂、服务器不稳定等影响游戏体验的方面存在问题。
对于高分评价内容的词云如图4.9所示。从图中可以看到玩家对游戏的‘刺激性’的游戏体验,‘大逃杀’的游戏模式,‘战术’、‘开黑’等游戏方式给予‘上瘾’、‘好玩’、‘不错’等肯定。但同时在高分评价的内容中,也提出了存在外挂、服务器不稳定等影响游戏体验的方面存在问题。
 对于低分评价内容的词云如图4.9所示。从图中可以看出玩家给与PUBG低分的原因主要是因为游戏优化、外挂和服务器问题。
对于低分评价内容的词云如图4.9所示。从图中可以看出玩家给与PUBG低分的原因主要是因为游戏优化、外挂和服务器问题。

游戏开发者可以根据词云所展示的内容对游戏进行优化,给与玩家更好的体验,以此来提升游戏的质量,吸引更多玩家的参与。
4.1.2 模块实现代码
以下为获取网页源码的主要代码,系统通过调用def get_page(offset)函数并将网址传入给offset便可实现对其网页的获取,获取网页源代码主要使用requests库,通过头文件伪装,实现对网页源码的获取,如果无法正常获取会传回None。def get_page(offset):
try:
url = "https://www.douban.com/game/27005453/{}".format(offset)
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.text
return None
except:
return None
def parse_one_page(html):
pattern = re.compile('[\s]*?[\s]*?(.*?)(.*?)[\s]*?
')
items = re.findall(pattern,html)
#print(items)
for item in items:
yield {
'name' : item[0],
'time' : item[1],
'score' : item[2],
'comment' : item[3]
}
def write_to_csvfile(content,pages):
with open("Comments.csv",'a',encoding='gb18030',newline='') as f:
fieldnames = ["name", "time", "score", "comment"]
writer = csv.DictWriter(f,fieldnames=fieldnames)
if pages ==0:
writer.writeheader()
writer.writerows(content)
f.close()
def main():
i = 1
print("------------执行开始------------")
for page in range(85):
time.sleep(1)
p_comment = get_page("comments?start={}&sort=score".format(page*20))
rows = []
for item in parse_one_page(p_comment):
rows.append(item)
# print(rows)
#以下实现进度条的功能
tt = int(i*20/85)
a = '**'*tt
b = '..'*(20-tt)
c = (i/85)*100
i += 1
print("\r已爬取进度%{:^3.0f}[{}->{}]".format(c,a,b),end='')
write_to_csvfile(rows, page)
print("\n数据写入完毕")
在下列代码中,还调用了make_pie(),make_brokenline()和make_wordcloud()等函数并传递相应的参数分别制作饼状图、折线图和词云。
def analyze_Comments(csvFile):
#fitems = csv.reader(f)
fitems = pd.read_csv(csvFile,encoding = 'gb18030')
#print(fitems['score'])
#filmHead = next(fitems)
print('正在分析评论')
#评分饼状图
scoreCount = {}
for comment in fitems['score']:
scoreCount[comment] = scoreCount.get(comment,0) + 1
#print(scoreCount)
#对字典进行排序
ret = sorted(scoreCount.items(),key = lambda x:x[1],reverse = True)
make_pie(dict(ret))
#受关注度和好评率的折线图
search = re.compile('(.*?月).*?日')
score_month_high = {}
score_month = {}
low_comments = ''
high_comments = ''
for stime,score,comment in zip(fitems['time'],fitems['score'],fitems['comment']):
if score == 50:
high_comments += comment
if score <= 20:
low_comments += comment
year = re.findall(search,stime)
Year = year[0]
if len(Year) >=7 :
score_month[Year] = score_month.get(Year,0) + 1
if (score == 50 or score == 40):
score_month_high[Year] = score_month_high.get(Year,0) + 1
else:
#print(year,score)
month = '2019年' + Year
score_month[month] = score_month.get(month,0) + 1
if (score == 50 or score == 40):
score_month_high[month] = score_month_high.get(month,0) + 1
#print(score_month_high)
sort_high = datesort(score_month_high)
sort_month = datesort(score_month)
high_rate = {}
for high,month in zip(sort_high.items(),sort_month.items()):
#print(high[1],month[1])
rate = high[1]/month[1]
high_rate[high[0]] = rate
#制作折线图
make_brokenline(sort_month,'关注度随时间的变化','时间','关注数')
#print(high_rate)
make_brokenline(high_rate,'好评率随时间的变化','时间','好评率')
#make_brokenline(sort_high)
#print(score_month)
time.sleep(1)
print('正在生成词云')
#词云的制作
make_wordcloud(high_comments,'high')
make_wordcloud(low_comments,'low')
time.sleep(2)
print('词云生成完毕')
下面是制作饼状图的主要代码。在系统调用make_pie()函数时,将对应的字典传给dictname中,字典的键作为饼状图的项,字典的值作为饼状图项的值。函数中主要使用matplotlib库中的函数与方法生成饼状图,并设置其颜色、图例、字体大小等。
def make_pie(dictname):
name = []
number = []
color = ['red', 'orange', 'yellow', 'green', 'blue', 'goldenrod']
for key,value in dictname.items():
name.append(key)
number.append(value)
#print(name,number)
plt.figure(figsize=(6,6))
pie = plt.pie(number, colors=color, labels=name,autopct='%1.1f%%')
for font in pie[1]: #pie[1]:l_text,pie图外的文本
font.set_fontproperties(currentFont)
font.set_size(12) #设置标签字体大小
for digit in pie[2]: #pie[2]:p_text,pie图内的文本
digit.set_size(12)
plt.axis('equal')
plt.title(u'评分', fontproperties=currentFont, fontsize=20)
plt.legend(loc=0, bbox_to_anchor=(1, 1.2)) # 图例
#设置legend的字体大小
leg = plt.gca().get_legend()
ltext = leg.get_texts()
plt.setp(ltext, fontproperties=currentFont, fontsize=6)
plt.show()
下面是制作折线图的主要代码。在系统调用make_ brokenline ()函数时,将对应的字典传给dict中,字典的键作为折线图x轴的值,字典的值作为y轴的值。函数中主要使用matplotlib库中的函数与方法,其过程与制作饼状图方法大体相同。
def make_brokenline(dict,s,a,b):
plt.figure(figsize=(25,6))
x = []
y = []
for key,value in dict.items():
x.append(key)
y.append(value)
plt.ylim(0,max(y)+max(y)/10)
plt.plot(x, y, marker='o', mec='r', mfc='w',label=u'y=x^2曲线图')
plt.title(s)
plt.xlabel(a)
plt.ylabel(b)
plt.show()
下面时制作词云的主要代码。主要使用jieba库对句子进行分割,并使用worldcloud库进行词云的制作,并设置词云的相关参数。
def make_wordcloud(txt,file):
ls = jieba.cut(txt)
text = " ".join(ls)
#print(text)
wc = WordCloud(
background_color="white", #背景颜色
max_words=200, #显示最大词数
#font_path="./font/msyh.tcc", #使用字体
font_path='simfang.ttf',
width=1000, #图幅宽度
height=700
)
wc.generate(text)
wc.to_file(file+".png")
4.2 局内数据分析模块实现
该模块将对本地文件中的局内对战数据进行提取,进行分析,并可视化展示。模块流程图如图4.11所示。
4.2.1 模块实现界面
在该模块运行后,系统会对本地的局内对战数据进行提取,并对数据进行分析(如图4.11所示)。玩家玩游戏时,除了娱乐放松之外,如何获得游戏的胜利也是玩家关注的问题之一。系统针对此问题,做出了以下分析:- 吃鸡率与助攻数的关系
可以分析出,玩家想获得游戏的胜利,就要多与队友进行沟通合作。所以在单排时不妨打开语音与队友商量战术,共同取得游戏的胜利。
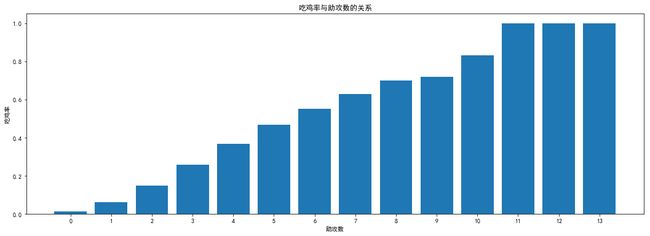
- 吃鸡率与助攻数的关系
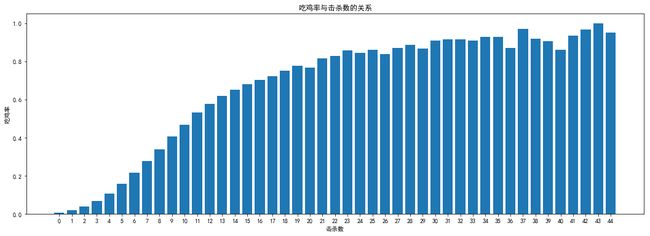
而对于普通玩家,吃鸡率达到20%便具有较高的水平,在此平均每局击杀数也要达到6个。所以对于玩家而言,想吃鸡获得游戏的胜利,最好的办法就是苦练技术,切忌每局苟到最后。
- 落地成盒与跳落地点的关系
从图4.15可以清楚看到,在绝地海岛地图中,Rozhok和学校附近、军事基地周围,由于物资丰富,跳落在这些地区的人数较多,导致其成为开局死亡率最高的地区,再者是Bunkers和Crater、Georgopol等。
从图4.16中可以看到,在热情沙漠地图中,Pecado、San Martin、Power Grid等,是开局死亡率最高的区域。
所以对于技术较差或者新手玩家而言,想要提高自己的存活率,跳伞时最好避开这些地方。
- 吃鸡与携带武器的关系
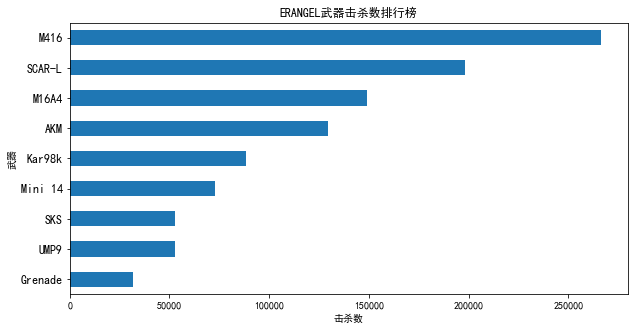
从图4.15可以看到,在绝地海岛地图中,M416武器是击杀数最高的,其次是SCAR-L、M14A4和AKM,其击杀数都在14万以上,遥遥领先于其他武器。
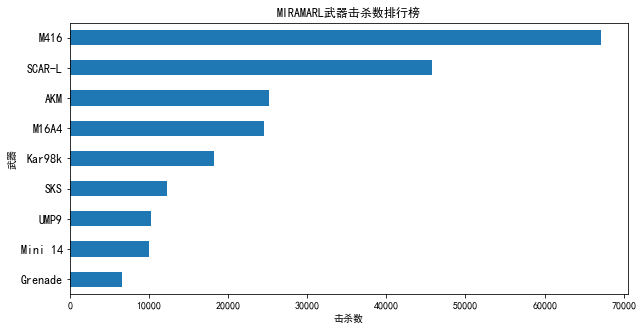
从图4.16可以看到,在热情沙漠地图中,M416武器是击杀数最高的,其次是SCAR-L、AKM和M16A4,其击杀数都在2万以上.
综合两张统计图可以看出,武器击杀数的排行榜的前几名大体相同,可以看出玩家对于这些武器的喜爱程度。玩家不妨试一下这些武器看看是否能够提高自己的吃鸡率。
4.2.2 模块实现代码
分析吃鸡率与助攻数、击杀数关系的代码主要代码如下。系统通过统计文件中的数据,并调用makebar()函数,将字典传递给形参生成柱状图。主要通过pandas库来处理数据。def agg_match_stats():
print('正在分析数据')
time.sleep(2)
assists_dict1 = {}
assists_dict2 = {}
kill_dict1 = {}
kill_dict2 = {}
for file in range(2):
path = r'aggregate\agg_match_stats_{}.csv'.format(file)
fitems = pd.read_csv(path,encoding = 'gb18030')
#print(fitems)
#数据提取和统计 存入字典中
For a,b,c in zip(fitems['player_assists'],fitems['team_placement'],fitems['player_kills']):
assists_dict1[a]=assists_dict1.get(a,0)+1
if int(c)<45:
kill_dict1[c] = kill_dict1.get(c,0)+1
if int(b)==1:
assists_dict2[a] = assists_dict2.get(a,0)+1
if int(b)==1 and int(c)<45:
kill_dict2[c] = kill_dict2.get(c,0)+1
#print(assists_dict2)
#print(assists_dict1)
#对字典进行排序
dict2 = sortV(assists_dict2)
dict1 = sortV(assists_dict1)
kdict1 = sortV(kill_dict1)
kdict2 = sortV(kill_dict2)
dict_ass = {}
dict_k = {}
for a,b in zip(dict1.items(),dict2.items()):
dict_ass[a[0]] = b[1]/a[1]
for a,b in zip(kdict1.items(),kdict2.items()):
dict_k[a[0]] = b[1]/a[1]
#生成柱状图
makebar(dict_ass,'吃鸡率与助攻数的关系','助攻数','吃鸡率')
makebar(dict_k,'吃鸡率与击杀数的关系','击杀数','吃鸡率')
下面是制作条形图的主要代码。在系统调用makebar ()函数时,将对应的字典传给dict中,字典的键作为折线图x轴的值,字典的值作为y轴的值。函数中主要使用matplotlib库中的函数与方法,其过程与模块一中的制作折线图的方法大致相同。
def makebar(dict,s,s1,s2):
x = []
y = []
plt.figure(figsize=(18,6))
for key,value in dict.items():
x.append(key)
y.append(value)
plt.bar(x,y)
plt.xticks(x)
plt.title(s)
plt.xlabel(s1)
plt.ylabel(s2)
plt.show()
下面是生成武器排行榜条形图和落地成盒热力图的主要代码。其核心方式与上述方式不同。下面主要通过pandas库和numpy库进行数据提取和处理,并用loc函数进行数据选取。并通过matplotlib库中的colors、pyplot等字库制作条形图和热力图。
def kill_match_stats():
# 先把玩家被击杀的数据导入
death_0 = pd.read_csv(r'deaths\kill_match_stats_final_0.csv')
for file in range(1,2):
death_1 = pd.read_csv(r'deaths\kill_match_stats_final_{}.csv'.format(file), nrows=5000000)
death = death_0.merge(death_1, how='outer')
print(death.shape)
# (18426348, 12)
#生成 武器排行榜条形图
last_seconds_erg = death.loc[(death['map'] == 'ERANGEL')&(death['killer_placement']==1), :].dropna()
last_seconds_erg['killed_by'].value_counts()[1:10].sort_values().plot.barh(figsize=(10,5))
plt.yticks(fontsize=12)
plt.xlabel('击杀数')
plt.ylabel('武器')
plt.title('ERANGEL武器击杀数排行榜')
plt.show()
plt.savefig('ERANGEL武器排行.png', dpi=100)
last_seconds_erg = death.loc[(death['map'] == 'MIRAMAR')&(death['killer_placement']==1), :].dropna()
last_seconds_erg['killed_by'].value_counts()[1:10].sort_values().plot.barh(figsize=(10,5))
plt.yticks(fontsize=12)
plt.xlabel('击杀数')
plt.ylabel('武器')
plt.title('MIRAMARL武器击杀数排行榜')
plt.show()
plt.savefig('MIRAMAR武器排行榜.png', dpi=100)
# 筛选落地成盒的玩家
in_240_seconds_erg = death.loc[(death['map'] == 'ERANGEL') & (death['time'] < 240), :].dropna()
in_240_seconds_mrm = death.loc[(death['map'] == 'MIRAMAR') & (death['time'] < 240), :].dropna()
data_erg = in_240_seconds_erg[['victim_position_x', 'victim_position_y']].values
data_mrm = in_240_seconds_mrm[['victim_position_x', 'victim_position_y']].values
data_erg = data_erg * 4096 / 800000
data_mrm = data_mrm * 1000 / 800000
def heatmap(x, y, s, bins=100):
heatmap, xedges, yedges = np.histogram2d(x, y, bins=bins)
heatmap = gaussian_filter(heatmap, sigma=s)
extent = [xedges[0], xedges[-1], yedges[0], yedges[-1]]
return heatmap.T, extent
#生成热力图 并保存到本地文件中
bg = imread(r'erangel.jpg')
hmap, extent = heatmap(data_erg[:, 0], data_erg[:, 1], 4.5)
alphas = np.clip(Normalize(0, hmap.max(), clip=True)(hmap) * 4.5, 0.0, 1.)
colors = Normalize(0, hmap.max(), clip=True)(hmap)
colors = cm.Reds(colors)
colors[..., -1] = alphas
fig, ax = plt.subplots(figsize=(24, 24))
ax.set_xlim(0, 4096)
ax.set_ylim(0, 4096)
ax.imshow(bg)
ax.imshow(colors, extent=extent, origin='lower', cmap=cm.Reds, alpha=0.9)
plt.gca().invert_yaxis()
plt.savefig('out1.png', dpi=100)
bg = imread(r'miramar.jpg')
hmap, extent = heatmap(data_mrm[:, 0], data_mrm[:, 1], 4.5)
alphas = np.clip(Normalize(0, hmap.max(), clip=True)(hmap) * 4.5, 0.0, 1.)
colors = Normalize(0, hmap.max(), clip=True)(hmap)
colors = cm.Reds(colors)
colors[..., -1] = alphas
fig, ax = plt.subplots(figsize=(24, 24))
ax.set_xlim(0, 1000)
ax.set_ylim(0, 1000)
ax.imshow(bg)
ax.imshow(colors, extent=extent, origin='lower', cmap=cm.Reds, alpha=0.9)
plt.gca().invert_yaxis()
plt.savefig('out2.png', dpi=100)
系统开发总结
在系统开发的过程中,系统经过不断地升级、优化。在数据提取和处理方面,从cvs库转向pandas库,从遍历数据到使用numpy库和loc函数进行数据选取。在爬虫方面,从最开始的使用BeautifulSoup库到正则表达式。使系统的代码不断简化、优化。但系统仍旧存在很多问题。诸如系统与用户的可交互操作较少,对爬取数据的挖掘不够深入,可视化展示不够形象美观等问题。
此外由于技术限制,系统的第三模块——对直播平台直播PUBG游戏的数据的爬取,以现有的能力还无法实现。并且因自身能力不足,在系统的第二模块中无法实现对游戏内数据的爬取,只能利用Kaggle网站内的数据进行可视化分析与展示。随着自身能力的提升,会不断地完善系统,解决上述问题、实现上述的功能。
最后,感谢Python老师的悉心教导和指点,使我完成系统的设计与开发。在此表达诚挚的谢意。
参考文献
[1] 钱程,阳小兰,朱福喜等.基于Python的网络爬虫技术[J].黑龙江科技信息,2016,(36):273[2] 张良均,王璐,谭立云,苏剑林.Python数据分析与挖掘实战[M].机械工艺出版社,2006.
[3] 张若愚.Python科学计算[M].北京:清华大学出版社.2012.
[4] M. Summerfield著,王弘博等.Python 3 程序开发指南[M],人民邮电出版社
[5] Mark Pilgrim.深入Python 3[M],Apress出版社.2009.