集成学习之模型融合(一)Stacking
简介
stacking是一种著名的集成学习方法,通过组合多个弱学习器生成的输出作为最终学习器的输入而得到一个更好的结果,我不介绍最原始的方法,那过于简单且容易过拟合,我会展开讲讲利用交叉验证做模型融合的过程。
blending可以跳转这里模型融合blending
基本思路
1、划分数据集
我们将data划分为train和test两部分,我们以k折交叉验证为例,将train划分为5等份,4份作为初级训练集(train_train),1份作为初级验证集(train_val)。
划分5次,直到每一等份都做过验证集为止,生成了5种不同的小训练集和验证集了。
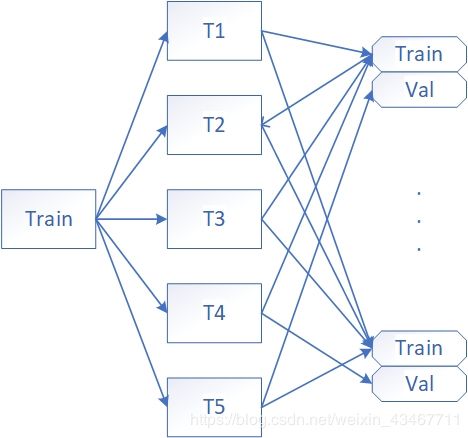
2、生成存储数组
在生成模型之前,我们需要先生成两个数组,一个用来存放次级训练集dataset_train,一个用于存放次级测试集dataset_test。
- dataset_train是一个模型作为一列,训练集train长度作为行数。


- dataset_test也为一个模型作为一列,训练集test长度作为行数。
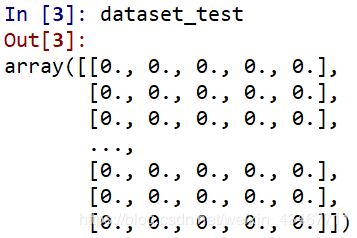

3、训练模型
训练之前根据自己的需求选择初级学习算法,我使用了基于随机决策树的平均算法RandomForest算法和Extra-Trees算法(其中可分为gini,entropy),还有GBDT来作为初级学习算法。
为什么要用这么多不大一样的算法,因为集成学习需要遵循好而不同原则,才能得到泛化能力强的集成。
以RandomForest为例,我们之前使用k折交叉验证划分了五等份,生成5种训练集和其对应的验证集,先将1种初级训练集输入算法,生成初级学习器model_1,再将对应的初级验证集输入model_1得到输出类概率。
与此同时,我们使用该初级学习器对测试集test预测并输出。
由于训练集切分了5等份,验证集只占其一,所以这时候一种初级验证集的预测结果只是训练集的五分之一,所以我们用剩下的4种初级训练集分别得到4个初级学习器,并一一输入对应的初级验证集,就可以再获得4份初级验证集的输出类概率,将五份输出合并成一列,就得到一份完整的训练集输出。然后将其存入次级训练集dataset_train数组中。
相应的,另外四种初级学习器也对训练集test进行预测输出,同样合并成一列保存至次级测试集dataset_test。
简要地说,就是我们的初级学习算法根据5种数据,因此生成了5种初级学习器,并分5次分别对训练集的五分之一进行预测输出,最后将五次的结果合并。
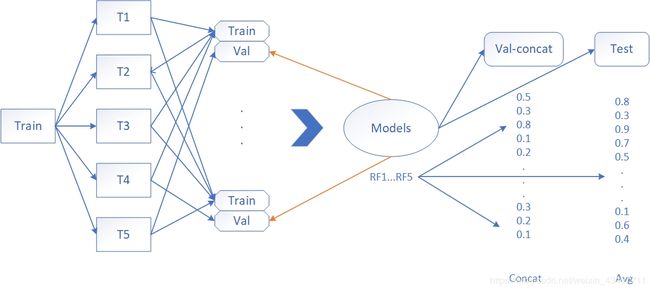
RandomForest模型训练完以后,我们就可以用auc验证一下5个初级学习器对test训练结果的平均对test测试集的准确率了。
![]()
由于我们只用了一种初级学习算法,通过循环再训练其他四种,重复上述过程得到输出并保存,就可以得到一个完整的次级训练集dataset_train。该次级训练集有5个特征,每个特征代表着每种初级学习算法的输出。
同时也可以再验证下每个学习算法输出的准确率。

4、模型融合
在这个阶段我们根据自己需求选择算法,我这里选择了GBDT(一开始选择LR,但是效果不大好,所以这玩意见仁见智)。
在训练模型阶段,我们得到了次级训练集dataset_train和次级测试集dataset_test,如下图。
- dataset_train每一列对应每一个初级学习算法生成的5个初级学习器,对五个验证集的预测结果相加。

- 而dataset_test每一列则是5个使用同一种初级学习算法的初级学习器对测试集test的预测结果取平均。

用次级训练集dataset_train作为输入和相应label进行拟合,生成次级学习器model。
然后将dataset_test喂给model,生成输出向量并用auc进行评估。
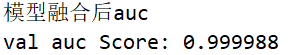
喜闻乐见的代码环节
这是自己实现的一个简单的代码,可以用于理清入门思路
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier,ExtraTreesClassifier,GradientBoostingClassifier
from sklearn.model_selection import train_test_split,StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
data,label=make_blobs(n_samples = 10000,centers = 2,random_state = 0,cluster_std = 0.60)
#划分训练集和测试
x_train,x_test,y_train,y_test=train_test_split(data,label,test_size=0.33,random_state=0)
clfs = [RandomForestClassifier(n_estimators = 100,n_jobs=-1,criterion = 'gini'),
RandomForestClassifier(n_estimators = 100,n_jobs=-1,criterion = 'entropy'),
ExtraTreesClassifier(n_estimators = 100,n_jobs = -1,criterion = 'gini'),
ExtraTreesClassifier(n_estimators = 100,n_jobs=-1,criterion = 'entropy'),
GradientBoostingClassifier(learning_rate = 0.05,subsample = 0.5,max_depth = 6,n_estimators=5)
]
#将训练集分层采样5折交叉切分,四层训练集,一层验证集
skf= list(StratifiedKFold(n_splits = 5,random_state = 0,shuffle = False).split(x_train, y_train))
#多维数组,用来存放每个模型生成的训练集预测结果
dataset_train = np.zeros((x_train.shape[0],len(clfs)))
#多维数组,用来存放每个模型生成的测试集预测结果
dataset_test = np.zeros((x_test.shape[0],len(clfs)))
for j,clf in enumerate(clfs):
# print (j,clf)
dataset_test_j = np.zeros((x_test.shape[0],len(skf)))
for i,(train,val) in enumerate(skf):
#使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。
# print('fold',i)
#从训练集中选出初级训练集和初级验证集
x_train_train,y_train_train= x_train[train],y_train[train]
x_train_val,y_train_val = x_train[val],y_train[val]
#用五种不一样初级训练集获得五个初级学习器
clf.fit(x_train_train,y_train_train)
#每一个初级学习器得出验证集的预测结果,也就是得出全部训练集的1/5
#在五次初级学习器循环预测完后就得到全部训练集的预测值
dataset_train[val,j] = clf.predict_proba(x_train_val)[:,1]
#五个初级学习器将test交替训练一遍
dataset_test_j[:,i] = clf.predict_proba(x_test)[:,1]
#取五次test训练结果的平均
dataset_test[:,j] = dataset_test_j.mean(1)
print("val auc Score: %f" % roc_auc_score(y_test, dataset_test[:, j]))
#模型融合
clf=GradientBoostingClassifier(learning_rate=0.2,subsample=0.5,max_depth=6,n_estimators=30)
clf.fit(dataset_train,y_train)#此时dataset_train是训练集的预测值
#生成预测集结果向量
y_submission = clf.predict_proba(dataset_test)[:,1]
#y_submission = (y_submission - y_submission.min()) / (y_submission.max() - y_submission.min()) #归一化非必要
print('模型融合后auc')
print("val auc Score: %f" % (roc_auc_score(y_test, y_submission)))
最新消息,sklearn更新最新版本后支持直接调用stacking做模型融合,这里不做探讨,算法最重要的是思想,调库没前途的。
欢迎关注我的微信公众号,虽然我没时间发文
数据挖掘初学者
