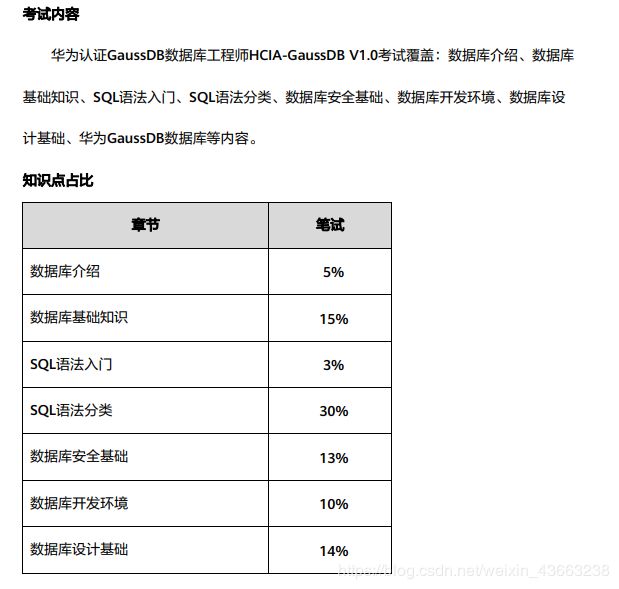
HCIA-GaussDB 华为认证数据库工程师(持续更新中60%)

// An highlighted block
第一、二章主要介绍数据库的发展史,基本概念等内容,
第三、四章节主要介绍GaussDB数据库的SQL语法,
第五章介绍数据库安全相关内容,
第六章介绍GaussDB数据库的常用开发工具,
第七章重点介绍数据库的设计方法,
第八章则介绍GaussDB的特点及应用案例。
HCIA-GaussDB V1.0
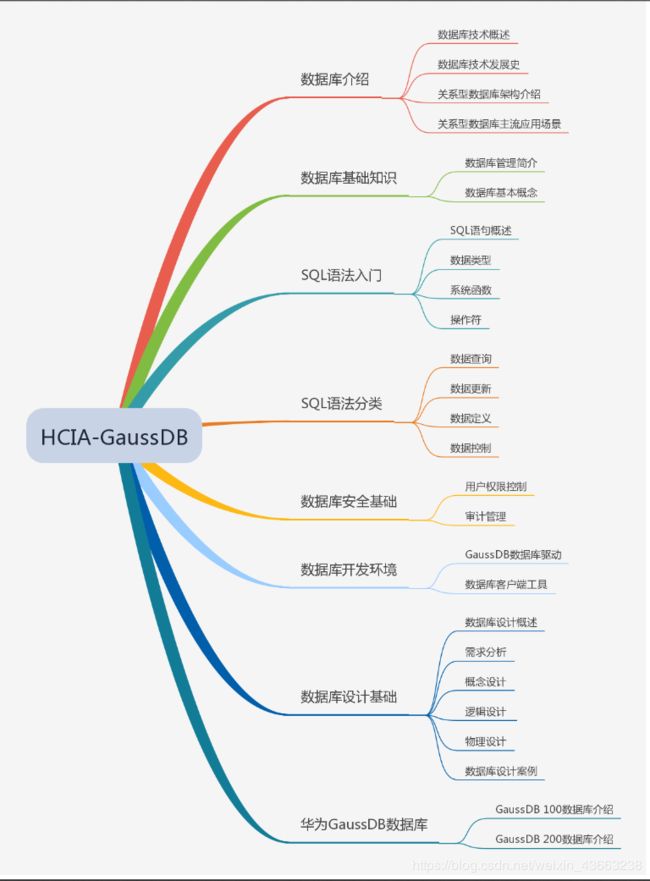
文章目录
- HCIA-GaussDB V1.0
- 第一章 数据库介绍 5%
- 1.1 数据库技术概述
- 1.2 数据库技术发展史
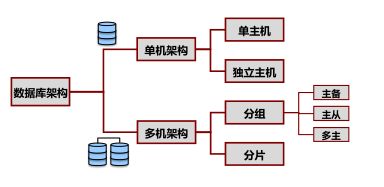
- 1.3. 关系型数据库架构介绍
- 单机架构
- 分组架构 - 主备
- 分组架构 - 主从
- 分组架构 - 多主
- 共享存储多活架构
- 分片(Sharding)架构
- 无共享(Share-Nothing)架构
- MPP架构 (Massively Parallel Processing)
- 1.4 关系型数据库主流应用场景
- 第二章 数据库基础知识 15%
- 2.1 数据库管理简介
- 2.2 数据库基本概念
- 第三章 SQL语法入门 3%
- 3.1/3.2 SQL语句概述/数据类型
- 3.3 系统函数
- 3.4 操作符
- 第四章 SQL语法分类 30%
- 4.1 数据查询
- 4.2 数据更新
- 4.3 数据定义
- 4.4 数据控制
- 第五章 数据库安全基础 13%
- 5.1 用户权限控制
- 5.2 审计管理
- 第六章 数据库开发环境 10%
- 6.1 GaussDB数据库驱动
- 6.2 数据库客户端工具
- 第七章 数据库设计基础 14%
- 7.1 数据库设计概述
- 7.2 需求分析
- 7.3 概念设计
- 7.4 逻辑设计
- 7.5 物理设计
- 7.6 数据库设计案例
- 第八章 华为GaussDB数据库 10%
- 8.1 GaussDB 100数据库介绍
- 8.2 GaussDB 200数据库介绍
- HCIA-GaussDB V1.0 模拟试卷
- 考试一
- 未归类
第一、二章主要介绍数据库的发展史,基本概念等内容,
第三、四章节主要介绍GaussDB数据库的SQL语法,
第五章介绍数据库安全相关内容,
第六章介绍GaussDB数据库的常用开发工具,
第七章重点介绍数据库的设计方法,
第八章则介绍GaussDB的特点及应用案例。
第一章 数据库介绍 5%
描述数据库技术相关概念;
列举主要的关系型数据库;
区分不同的关系型数据架构;
描述并识别关系型数据库的主要应用场景。
本章主要介绍了数据库和数据管理系统的节本概念,对数据库几十年的发展历史进行了回顾,详细介绍了数据库从早期的网状模型,层次模型发展到关系型模型的历程,并对近年来新兴的NoSQL和NewSQL概念进行了介绍。
对关系型数据库的主要架构进行了对比分析和介绍,对于不同场景下各种架构的优缺点进行了简单说明。最后对关系型数据的主流应用场景OLTP和OLAP进行了介绍和对比说明。
1.1 数据库技术概述
1.(判断题)数据的含义称为语义。
A.正确
B.错误
答案:A
2.(判断题)数据库系统是由数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员组成的存储、管理、处理和维护数据的系统。
A.正确
B.错误
答案:A
3.存放在数据库中数据的特点是 ( )
A. 永久存储
B. 有组织
C. 独立性
D. 可共享
答案:ABD
4.属于数据库系统这个概念范围的组成部分有 ( )
A. 数据库管理系统
B. 数据库
C. 应用开发工具
D. 应用程序
答案:ABCD
5.数据库应用程序可以不经过数据库管理系统而直接读取数据库文件。 ( )
A. True
B. False
答案:B
考点
1.数据的含义称为语义。
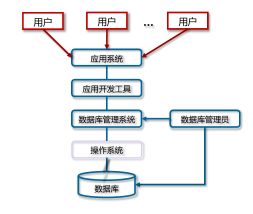
2.数据库系统(Database System, DBS)是由数据库(Database, DB)、数据库管理系统 (DBMS)(及其应用开发工具)、应用程序和数据库管理员组成的存储、管理、处理和维护数据的系统。
3.存放在数据库中数据的特点
永久存储、有组织、可共享
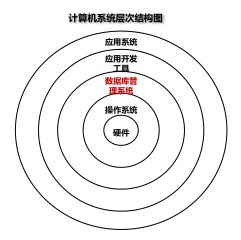
4.数据库系统 (DBS)架构图
1.2 数据库技术发展史
1.(多选题)数据库系统优势有哪些?
A.整体数据的结构化
B.数据的共享性高冗余度低且易扩充
C.数据独立性高
D.统一管理和控制
答案:ABCD
2.(多选题)下列哪些选项属于关系型数据库ACID特性?
A.原子性
B.统一性
C.隔离性
D.持久性
答案:ABCD
3.数据管理的发展历史上经历了哪几个阶段? ( )
A. 人工阶段
B. 智能系统
C. 文件系统
D. 数据库系统
答案:ACD
4.允许一个以上的节点无双亲,一个节点可以有多于一个的双亲,这些特性对应的是哪种数据模型? ( )
A. 层次模型
B. 关系模型
C. 面向对象模型
D. 网状模型
答案:D
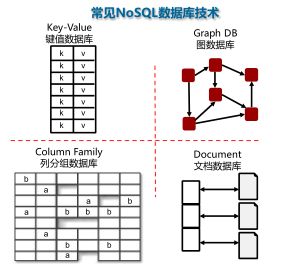
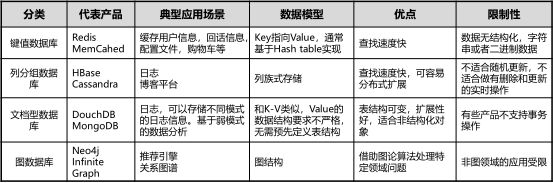
5. 下面选项中属于NOSQL数据库的是: ( )
A. 图数据库
B. 文档数据库
C. 键值数据库
D. 列分组数据库
答案:ABCD
6. NoSQL和NewSQL数据库的出现能够彻底颠覆和取代原有的关系型数据库系统。 ( )
A. True
B. False
答案:B
考点
1.数据库系统优势
(1)整体数据的结构化
数据面向整个系统而不是单个应用,被多个应用共享。
(2)数据的共享性高,冗余度低且易扩充。
(3)数据独立性高
物理独立性:应用程序与数据库中数据的物理存储是相互独立的。
逻辑独立性:应用程序与数据库的逻辑结构是相互独立的。
(4)统一管理和控制
数据的安全性保护;
数据的完整性检查;
并发控制;
数据库恢复。
2.关系型数据库ACID特性
(1)原子性(Atomicity)
事务是数据库的逻辑工作单位,事务中的操作,要么都做,要么都不做。
(2)一致性(Consistency)
事务的执行结果必须是使数据库从一个一致性状态转到另一个一致性状态。
(3)隔离性(Isolation)
数据库中一个事务的执行不能被其他事务干扰。即一个事务的内部操作及使用的数据对其他事务是隔离的,并发执行的各个事务不能相互干扰。
(4)持久性(Durability)
事务一旦提交,对数据库中数据的改变是永久的。提交后的操作或者故障不会对事务的操作结果产生任何影响。
3.数据管理的发展
应用需求推动;
软硬件的飞速发展为基础;
三个阶段:人工管理、文件系统、数据库系统
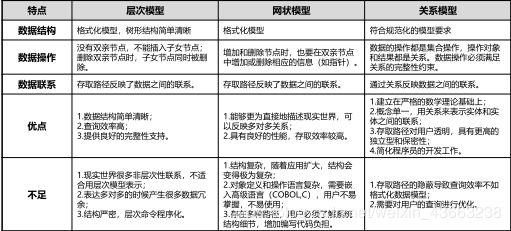
4.数据模型
(1)层次模型
有且只有一个节点没有双亲,该节点被称为根节点(root)。
根节点以外的其他节点有且只有一个双亲节点。
(2)网状模型
允许一个以上的节点无双亲。
一个节点可以有多于一个的双亲。
(3)关系模型
建立在严格的数据概念基础上。
关系必须是规范化的。
关系的分量必须是一个不可分的数据项。
5.什么是NoSQL数据库?
NoSQL(Not Only SQL)
非关系型的、分布式的、不保证满足ACID特性的一类数据管理系统。
技术特点
对数据进行分区(partitioning),利用大量节点并行处理获得高性能,同时能够采用横向扩展方式(scale out);
降低ACID一致性约束,允许暂时不一致,接受最终一致性。遵循BASE(Basically Available,Soft state,Eventual consistency)原则;
各数据分区提供备份(一般是三份),应对节点故障,提高系统可用性。
6.NoSQL和NewSQL
(1)NoSQL并不是为了取代RDBMS
优势显著,缺点也较为明显
与RDBMS[关系数据库管理系统(Relational Database Management System:RDBMS)]一起构建完整的数据生态系统
(2)NewSQL
指追求NoSQL的可扩展性同时能够支持关系模型(包括ACID特性)的关系型数据库系统,主要面向OLTP场景。
能够支持SQL作为主要的使用语言。
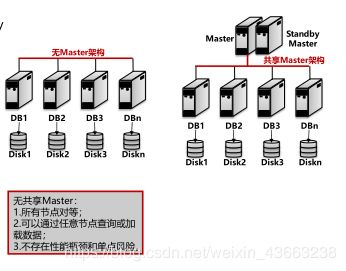
1.3. 关系型数据库架构介绍
1.(判断题)单机架构的数据库具有部署集中、运维方便、易拓展等特性。
A.正确
B.错误
答案:B
2.(单选题)下列关于主从架构描述正确的是?
A.读写都在主机完成
B.查询在主机完成,写入在从机完成
C.查询在从机完成,写入在主机完成
D.读写都在从机完成
答案:C
3.主备架构可以通过读写分离方式来提高整体的读写并发能力 ( )
A. True
B. False
答案:B
4.哪种数据库架构具有良好的线性扩展能力? ( )
A. 主从架构
B. Shared-nothing架构
C. Shared-disk架构
D. 主备架构
答案:B
5.分片架构的特点就是通过一定的算法把数据分散在集群的各个数据库节点上,利用集群内服务器数量的优势进行并行计算。 ( )
A. True
B. False
答案:A
考点
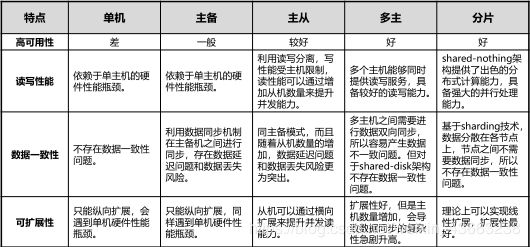
1.数据库架构
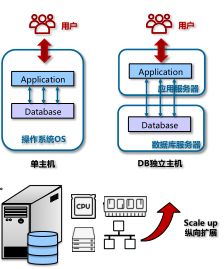
(1)单机架构
优点:部署集中,运维方便。
缺点:可扩展性,存在单点故障,单机会遇到性能瓶颈。
(2)主从架构
通过读写分离方式分散压力:
写入、修改、删除操作,在写库(主机)上完成;
把查询请求,分配到读库(从机)。
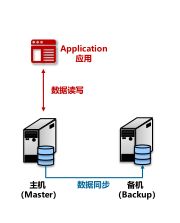
(3)主备架构
数据库部署在两台服务器,其中承担数据读写服务的服务器称为“主机”。
另外一台服务器利用数据同步机制把主机的数据复制过来,称为“备机”。
同一时点,只有一台服务器对外提供数据服务
(4) 共享存储的多活架构(Shared Disk)、分片(Sharding)架构、无共享(Share-Nothing)架构、MPP架构 (Massively Parallel Processing)。
(5)分片(Sharding)架构
主要表现形式就是水平数据分片架构
把数据分散在多个节点上的分片方案,每一个分片包括数据库的一部分,称为一个shard。
多个节点都拥有相同的数据库结构,但不同分片的数据之间没有交集,所有分区数据的并集构成数据总体。
常见的分片算法有:根据列表值,范围取值和Hash值进行数据分片。
优点
数据分散在集群内的各个节点上,所有节点可以独立性工作。
单机架构
分组架构 - 主备
分组架构 - 主从
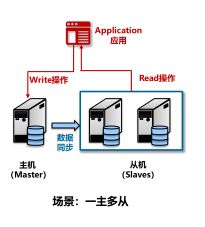
分组架构 - 多主
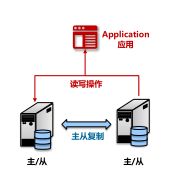
共享存储多活架构
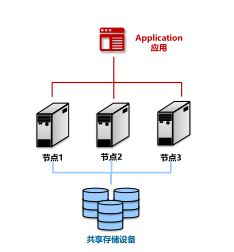
分片(Sharding)架构
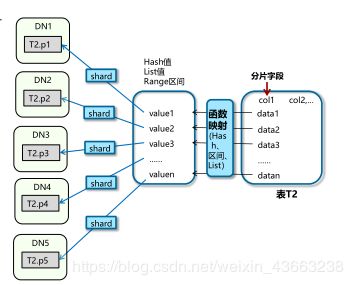
无共享(Share-Nothing)架构
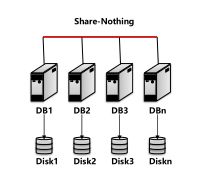
MPP架构 (Massively Parallel Processing)
1.4 关系型数据库主流应用场景
1.(判断题)秒杀活动是典型的OLTP场景。
A.正确
B.错误
答案:A
2.(判断题)OLAP系统的数据不允许更新。
A.正确
B.错误
答案:B
3.衡量OLTP系统的测试指标包括: ( )
A. tpmC
B. Price/tpmC
C. qphH
D. qps
答案:AB
4.OLAP系统适用下面哪些场景 ( )
A. 报表系统
B. 在线交易系统
C. 多维分析,数据挖掘系统
D. 数据仓库
答案:ACD
5.OLAP系统能够对大量数据进行分析处理,所以同样能够满足OLTP对于小数据量处理的性能需求 ( )
A. True
B. False
答案:B
考点
联机事务处理 (OnLine Transaction Processing) OLTP
联机分析处理 (OnLine Analytical Processing) OLAP
1.(1)典型的OLTP场景
零售系统、金融交易系统、火车机票销售系统、秒杀活动
(2)典型的OLAP场景
报表系统、CRM系统、金融风险预测预警系统、反洗钱系统、数据集市、数据仓库。
2.OLTP和OLAP对比分析
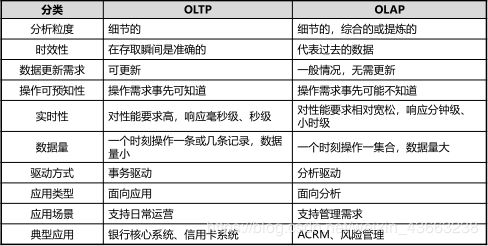
3.数据库性能衡量指标
TPC(Transaction Processing Performance Council,事务处理性能委员会)
(1)TPC-C规范
面向OLTP系统,主要包括两个指标
流量指标:tpmC(tpm – transactions per minuete, 即每分钟测试系统处理的事务数量)。
性价比指标:Price(测试系统价格)/tmpC。
(2)TPC-H规范
面向OLAP类系统
流量指标:qphH – Query per hour,即每小时处理的复杂查询数量。
需要考虑测试数据集合大小,分为不同的测试数据集,指定了22个查询语句,可以根据产品微调。
测试场景:数据加载,Power能力测试和Througput测试。
第二章 数据库基础知识 15%
学完本课程后,您将能够:
描述数据库管理工作的主要内容;
区分不同的备份方式;
列举安全管理的措施;
描述性能管理的工作;
描述数据库的重要基本概念,以及各数据库对象的使用方法。
说明了数据库管理的核心目标,并介绍了数据库管理的工作范围
介绍了数据库对象管理的工作内容
介绍了备份恢复的基本概念,灾难恢复等级以及相关概念,并介绍了不同备份策略以及之间的差异
介绍了数据库系统安全框架和控制模型
介绍了数据库性能管理的意义和目标,以及性能管理工作的一些场景和工作内容
对数据库主要的基本概念进行了介绍和说明
针对一些容易混淆的概念进行了对比说明
并对重要但是不宜理解的概念进行了基于场景的介绍分析
2.1 数据库管理简介
1.(判断题)数据库管理工作就是对数据库进行管理和运维的工作。
A.正确
B.错误
答案:A
2.(判断题)视图和基本表一样,在物理上是实际存在的。
A.正确
B.错误
答案:B
3. 把数据库中的数据迁移到其他异构的数据库中,可以采用( )的方式
A. 物理备份
B. 逻辑备份
答案:B
4. 为提升表的查询速度,可以创建的数据库对象是?( )
A. 视图(View)
B. 函数(Function)
C. 索引(Index)
D. 序列(Sequence)
答案:C
5. 某单位制定灾备标准时,希望在灾难发生后能够在1小时以内系统恢复成对外可服务的状态,这个指标指的是。 ( )
A. RTO
B. RPO
答案:A
考点
1.数据库管理 (Database Admin)
数据库管理工作就是对数据库管理系统进行管理和维护的工作。
核心目标,保证数据库管理系统的:稳定性、安全性、数据一致性、系统的高性能
2.视图和基本表
视图 (View)与基本表不同,不是物理上实际存在的,是一个虚表。
表 (Table)在关系数据库中,数据库表就是一系列二维数组的集合,表用来代表和储存数据对象之间的关系。
3.物理备份和逻辑备份
物理备份:直接备份数据库所对应的数据文件甚至是整个磁盘。
逻辑备份:将数据从数据库中导出,并将导出的数据进行存档备份。
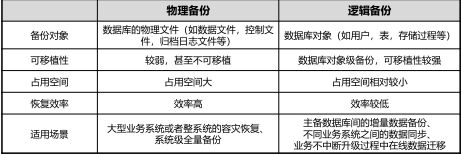
4.什么是数据库对象?
数据库里用来存储和指向数据的各种概念和结构的总称。
对象管理就是使用对象定义语言或者工具创建,修改或删除各种数据库对象的管理过程。
常见的基本数据库对象:
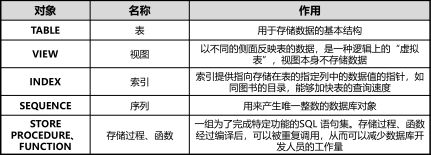
5.灾难恢复
灾难备份:为了灾难恢复而对数据、数据处理系统、网络系统、基础设施、专业技术能力和运行管理能力进行备份的过程。
恢复时间目标(RTO) (Recovery Time Objective)
灾难发生后,信息系统或业务功能从停顿到必须恢复的时间要求。比如说灾难发生后半天内便需要恢复,RTO值就是十二小时。
恢复点目标(RPO) (Recovery Point Objective)
灾难发生后,系统和数据必须恢复到的时间点要求。例如每天00:00进行数据备份,那么如果今天发生了宕机事件,数据可以恢复到的时间点(RPO)就是今天的00:00,如果凌晨3点发生灾难或宕机事件,损失的数据就是三个小时,如果23:59发生灾难,那么损失的数据就是约24小时,所以该用户的RPO就是24小时,即用户最大的数据损失量是24小时。
2.2 数据库基本概念
1.(单选题)以下哪种数据分布策略适合于记录集较小的表。
A.replication
B.hash
C.list
D.range
答案:A
2.(判断题)OLTP是用来存储/查询业务应用中活动的数据来支撑日常的业务活动。
A.正确
B.错误
答案:A
3.NOLOGGING表因为不用写REDO日志,所以写入数据效率很高,应尽可能使用这种方式建表。 ( )
A. True
B. False
答案:B
4.形成命名空间,避免名字冲突的数据库对象是?( )
A. 表空间(Tablespace)
B. 视图(View)
C. 模式(Schema)
D. 索引(Index)
答案:C
5.下面选项中,属于事务特征的是( )
A. Atomicity
B. Isolation
C. Durability
D. Consistency
答案:ABCD
6.在可重复读( Repeatable read )事务隔离机制下,下面哪种情况不会发生?( )
A. 脏读
B. 不可重复读
C. 幻影读
答案:AB
考点
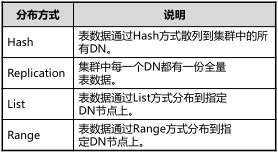
1.GaussDB T分布式数据库的数据表是分散在所有数据节点(DataNode,DN)上的,所以创建表的时候需要指定分布列。
复制(Replication):适合于记录集较小的表、表中数据在各节点上完全复制,各DN都拥有全量数据
Hash/List/Range:这三种方式适合数据量较大的表
2.存储方式的选择
列存适合的场景
统计分析类查询( group,join多的场景);
适合OLAP,数据挖掘等大量查询的应用查询。
行存适合的场景
点查询(返回记录少,基于索引的简单查询);
适合OLTP,这种轻量级事务,大量写操作,数据增删改比较多的场景。
联机事务处理(OLTP): 存储/查询业务应用中活动的数据以支撑日常的业务活动;
联机分析处理(OLAP):存储历史数据以支撑复杂的分析操作,侧重决策支持。
3.NOLOGGING表不记录Redo日志。
(1)日志量减少提高数据写性能。
(2)没有Redo日志,出现故障数据库重启后无法重演恢复(Recover)。
(3)适用对象:可靠性要求不高的非核心数据。
4.表空间(Tablespace)、视图(View)、模式(Schema)、索引(Index)
(1)表空间(Tablespace)
表空间是由一个或者多个数据文件组成
通过表空间定义数据库对象文件的存放位置。
数据库中所有对象在逻辑上都存放在表空间中。
在物理上储存在表空间所属的数据文件中。
表空间作用
根据数据库对象使用模式安排数据物理存放位置,提高性能。
频繁使用的索引放置在性能稳定且运算速度快的磁盘上。
归档数据,使用频率低,对访问性能要求低的表存放在速度慢的磁盘上。
通过表空间指定数据占用的物理磁盘空间。
通过表空间限制物理空间使用上限,避免磁盘空间被耗尽。
(2)视图(View)
视图作用
简化了操作,把经常使用的数据定义为视图。
安全性,用户只能查询和修改能看到的数据。
逻辑上的独立性,屏蔽了真实表的结构带来的影响。
限制性
性能问题:查询可能很简单,但是封装的视图语句很复杂。
修改限制:对于复杂视图,用户不能通过视图修改基表数据。
(3)模式(Schema)
Schema是数据库形式语言描述的一种结构,是对象的集合
允许多个用户使用一个数据库而不干扰其他用户。
把数据库对象组织成逻辑组,让他们更便于管理。
形成命名空间,避免对象的名字冲突。
schema包含表及其他数据库对象,数据类型、函数、操作符等。
(4)索引(Index)
索引提供指向存储在表的指定列中的数据值的指针,如同图书的目录,能够加快表的查询速度,但同时也增加了插入、更新和删除操作的处理时间。
在创建索引时,以下建议作为参考:
在经常需要搜索查询的列上创建索引,可以加快搜索的速度。
在作为主键的列上创建索引,强制该列的唯一性和组织表中数据的排列结构。
在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的。
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序
查询时间。
在经常使用WHERE子句的列上创建索引,加快条件的判断速度。
为经常出现在关键字ORDER BY、GROUP BY、DISTINCT后面的字段建立索引。
5.事务特征 - ACID
(1)原子性(Atomicity)
事务是数据库的逻辑工作单位,事务中的操作,要么都做,要么都不做。
(2)一致性(Consistency)
事务的执行结果必须是使数据库从一个一致性状态转到另一个一致性状态。
(3)隔离性(Isolation)
数据库中一个事务的执行不能被其他事务干扰。即一个事务的内部操作及使用的数据对其他事务是隔离的,并发执行的各个事务不能相互干扰。
(4)持久性(Durability)
事务一旦提交,对数据库中数据的改变是永久的。提交后的操作或者故障不会对事务的操作结果产生任何影响。
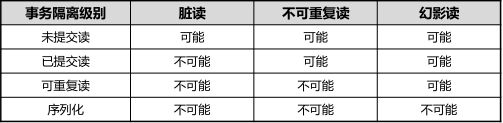
6.事务隔离级别与数据情况问题对应
(1)数据不一致情况 - 脏读
“Dirty”Reads(脏读)
一个事务读取到了其他事务中还没有提交(Committed)的数据。
因为未提交数据存在回滚的可能,所以被称为“脏”数据。
(2)Non-repeatable Reads(不可重复读)
一个事务所获取到的数据是可以被其它事务修改的。
一个事务在处理过程中多次读取同一个数据(重复读),这个数据是可能发生变化的,因此被称为不可重复读。
(3)Phantom Read(幻影读)
是不可重复读的更为特殊的一个场景。
事务T1按照一定条件读取数据(使用了where条件过滤)后,事务T2删除了部分记录或者插入了一些新的记录,这些变更的数据是满足where条件过滤的。
那么当T1再次按照相同条件读取数据时,就会发现莫名其妙地少了(也可能多了)一些数据。
这些变化的数据就被称为“幻影”数据。
事务隔离级别
(4)Serializable(序列化)
系统中所有的事务以串行地方式逐个执行,所以能避免所有数据不一致情况。
但是这种以排他方式来控制并发事务,串行化执行方式会导致事务排队,系统的并发量大幅下降,使用的时候要绝对慎重。
(5)Repeatable read(可重复读)
一个事务一旦开始,事务过程中所读取的所有数据不允许被其他事务修改。
这个隔离级别没有办法解决“幻影读”的问题。
因为它只“保护”了它读取的数据不被修改,但是其他数据会被修改。如果其他数据被修改后恰好满足了当前事务的过滤条件(where语句),那么就会发生“幻影读”的情况。
(6)Read Committed(已提交读)
一个事务能读取到其他事务提交过(Committed)的数据。
一个事务在处理过程中如果重复读取某一个数据,而且这个数据恰好被其他事务修改并提交了,那么当前重复读取数据的事务就会出现同一个数据前后不同的情况。
在这个隔离级别会发生“不可重复读”的场景。
(7)Read Uncommitted(未提交读)
一个事务能读取到其他事务修改过,但是还没有提交的(Uncommitted)的数据。
数据被其他事务修改过,但还没有提交,就存在着回滚的可能性,这时候读取这些“未提交”
数据的情况就是“脏读”。
在这个隔离级别会发生“脏读”场景。
第三章 SQL语法入门 3%
学完本课程后,您将能够:
描述SQL语句的定义及类型,识别给定语句所属的类别;
列举可用的数据类型,并学会选择正确的数据类型来创建表;
描述不同系统函数的用法,并掌握如何在查询语句中正确使用系统函数;
列举常用操作符,并掌握不同操作符的优先级及使用方法。
本章主要讲述华为GaussDB T的数据类型、系统函数、操作符及SQL开发环境等内容,帮助学员初步了解GaussDB T,为下一步的学习打下基础。
3.1/3.2 SQL语句概述/数据类型
1.(判断题)DCL数据控制语言用来设置或更改数据库事务、权限操作(用户或角色授权,权限回收)、锁表(支持共享锁和排他锁两种锁表模式)、停机等。
A.正确
B.错误
答案:A
2.(判断题)创建视图、删除视图语句数据DDL语句。
A.正确
B.错误
答案:A
3. 以下哪些是时间间隔类型?( )
A. timestamp[(n)]
B. timestamp(n) with time zone
C. interval day[(n1)] to second [(n2)]
D. interval year[(n)] to month
答案:CD
4. bigint占用4个字节? ( )
A. True
B. False
答案:B
5. blob用于存储变长大对象二进制数据? ( )
A. True
B. False
答案:A
6.(判断题)integer unsigned表示32位有符号整数。
A.正确
B.错误
答案:B
7.(判断题)常用数据类型有数值类型、字符类型、日期类型等。
A.正确
B.错误
答案:A
考点
1.SQL语句
(1)SQL(Structured Query Language,结构化查询语言)是一种特定目的编程语言,用于管理关系数据库管理系统,或在关系流数据管理系统中进行流处理。
GaussDB T 是一种关系型数据库,SQL语句包括DDL、DML、DCL和DQL。
(2)语句分类
DDL(Data Definition Language)数据定义语言
用于定义或修改数据库中的对象,如:表、索引、视图、序列、用户、角色、表空间等。
DML (Data Manipulation Language)数据操纵语言
用于对数据库表中的数据进行操作,如插入,更新和删除。
DCL (Data Control Language)数据控制语言
用来设置或更改数据库事务、权限操作(用户或角色授权,权限回收)、锁表(支持共享锁和排他锁两种锁表模式)、停机等。
DQL (Data Query Language)数据查询语言
用来查询数据库内的数据,如单表查询、多表查询。
2.常用数据类型和非常用数据类型
数据类型是数据的一个基本属性,主要用于建表时指定字段的数据类型,包括:
常用数据类型
数值类型、字符类型、日期类型等
非常用数据类型
二进制类型、布尔类型、时间间隔类型等
(0)常用数据类型
数值类型
(1)整型类型
integer(32位有符号整数)
– 占用字节:4
– 取值范围:-2^31 ~ 2^31 -1
– 关键字:int,integer,binary_integer,int signed,integer signed
integer unsigned(32位无符号整数)
– 占用字节:4
– 取值范围:0 ~ 2^32 -1
– 关键字:uint、binary_uint32、integer unsigned
bigint(64位有符号整数)
– 占用字节:8
– 取值范围:-2^63 ~ 2^63 -1
– 关键字:bigint、binary_bigint和bigint signed
(2)浮点类型
float
– 占用字节:8
– 取值范围:[-1.79E+308, +1.79E+308]
– 关键字为real,double,float和binary_double
(3)高精度数值类型
decimal/number
– 占用字节:4~24,长度与其有效数字有关
– 取值范围:(-1.0E128, 1.0E128)
– 关键字:decimal,number和numeric
– 语法格式:number/decimal,number/decimal(p),和number/decimal(p,s)
p 表示可存储的最大精度 [1,38] s表示小数点后有效数字个数 [-84,127]
USE_NATIVE_DATATYPE(数据类型控制参数)
数据类型:bigint、double、float、int 、integer、real、smallint、tinyint
TRUE:映射为binary_double类型;
FALSE:映射为number类型。
(4)字符类型
编码类型
UTF8编码:汉字和全角字符占2~8个字节,数字和英文字符等都是1个字节
GBK编码:汉字和全角字符占2个字节,数字等字符占用1个字节
定长字符串类型(1~8000字节,若输入长度小于size,则利用空格在右端补齐)
char(size [byte | char]):存储定长字节或者字符串
– 默认为byte类型,关键字为char。
– size byte:最大能容纳的字节数,size char:最大能容纳的字符数。
nchar(size):存储定长字符串
– 等同于char(size char)
– 关键字:nchar。
变长字符串类型( 若输入长度小于size,不会利用空格补齐)
varchar(size [byte | char]):存储变长字节或字符串
– size byte:最大能容纳的字节数,size char:最大能容纳的字符数,1~8000字节
– 关键字:varchar
nvarchar(size):用于存储变长字符串
– 1~8000字节
– 关键字:nvarchar
clob:存储大对象变长字符串
– 占用字节:0~4G
– 关键字:clob,text,longtext,long。
(5)日期类型
不带时区的时间戳(8字节)
datetime/date
– 保存年、月、日、时、分、秒
– 关键字:date、datetime
– 如:2019-08-22 17:29:13
timestamp[(n)]
– 保存年、月、日、时、分、秒、微秒,n取值为0~6,默认值为6。
– 关键字:timestamp
– 如: 2019-08-22 17:29:13.263183 (n=6)
2019-08-22 17:34:36.383 (n=3)
带时区的时间戳
timestamp(n) with time zone
– 保存年、月、日、时、分、秒、微秒和时区,占12字节
– 关键字:timestamp(n) with time zone.
– 如: 2019-08-22 18:41:30.135428 +08:00
timestamp(n) with local time zone:
– 不保存时区,存储时转换为数据库时区的timestamp,占8字节
– 关键字:timestamp(n) with local time zone。
– 如:存储时为2019-08-22 18:41:30.135428
查看时为2019-08-22 18:41:30.135428 +08:00
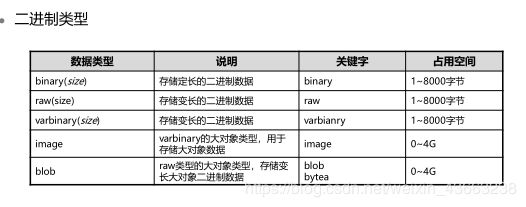
(0)非常用数据类型
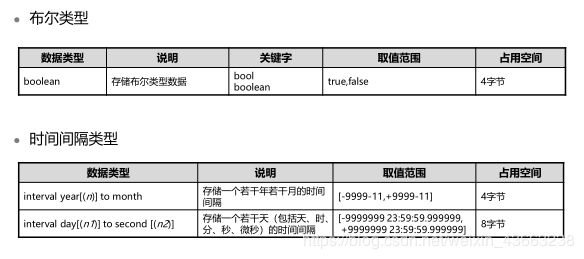
3.3 系统函数
1.(单选题)以下哪个选项属于系统函数。
A.数值计算函数
B.字符处理函数
C.时间日期函数
D.以上说法全都正确
答案:D
2.(判断题)months_between(date1, date2)可以计算两个日期之间的月份差。
A.正确
B.错误
答案:A
3.以下哪些是数值计算函数?( )
A. length(str)
B. sin(n)
C. trunc(number, scale)
D. hex(p1)
答案:BC
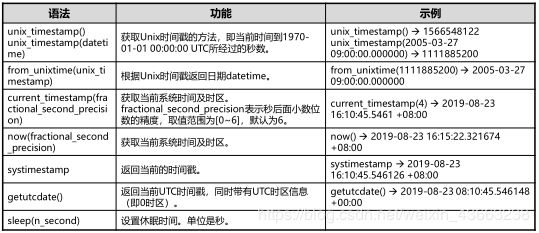
4.GaussDB T获取Unix时间戳的方法。 ( )
A. unix_timestamp()
B. unix_timestamp(datetime)
C. unix_timestamp(datetime_string)
D. from_unixtime(unix_timestamp)
答案:AB
5.if( cond , exp1 , exp2 )函数,在cond条件为假时,返回( )。
A. exp1
B. exp2
答案:B
6.返回值最大支持8000字节的函数包括( )。
A. concat( str [, …])
B. concat_ws( separator , str1 , str2 , …)
C. to_nchar( text_exp )
D. to_number( n [, fmt )
答案:AB
考点
1. 系统函数
系统函数是对一些业务逻辑的封装,以完成特定的功能。系统函数可以有参数,也可以没有参数。系统函数执行完成后会返回执行结果。
系统函数的分类:数值计算函数、字符处理函数、时间日期函数、间隔函数、类型转换函数
2.时间日期函数
add_months(date,n),months_between(date1, date2):返回date加或减n个月后的值,计算两个日期之间的月份差。
extract(field from datetime),trunc(date[,fmt]):从指定的日期(datetime)中提取指定的时间字段(field),按指定的格式截取输入的日期数据。
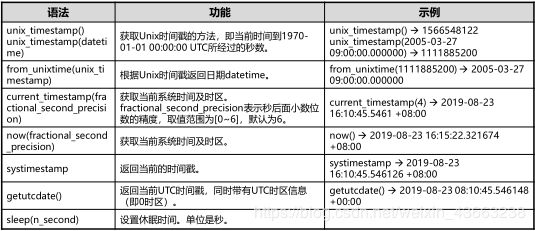
3.数值计算函数和字符处理函数
(1)数值计算函数
abs(exp),cos(exp),sin(exp),acos(exp),asin(exp):返回表达式的绝对值,余弦值,正弦值,反余弦值和反正弦值。
abs函数
入参:数值类型或可以隐式转换为数值类型的非数值类型;返回值:同入参数据类型
sin和cos函数
入参:可转成数值型的表达式;返回值:NUMBER类型
asin和acos函数
入参:可转成数值型的表达式,取值范围为[-1,1];返回值:NUMBER类型
bitand(exp1,exp2),bitor(exp1,exp2),bitxor(exp1,exp2) :按位与,按位或,按位异或运算。
round(number[,decimals]):将number类数值按照decimals指定的向小数点前后截断。
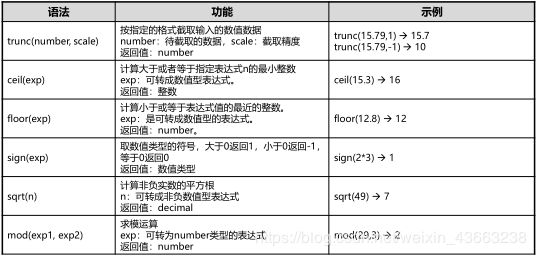
(2)字符处理函数
concat(str[,…]),concat_ws(separator,str1,str2,…):拼接一个或多个字符串。第一个函数无分隔符,第二个函数可以指定分隔符连接。
hex(str),hex2bin(str),hextoraw(str):第一个函数返回十六进制值的字符串表示形式,其他函数返回十六进制字符串所表示的字节串。不同点:hex2bin返回binary型,hextoraw返回raw型。
insert(str,pos,len,newstr),replace(str,src,dst):字符串插入和字符串替换函数。
instr(str1,str2[,pos[,n]]),instrb(str1,str2[,pos[,n]]):字符串查找函数。返回要查找的字符串在源字符串中的位置。不同点:instr按字符计算位置,instrb按字节计算位置。
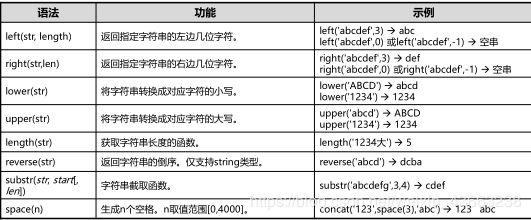
4.时间日期函数
add_months(date,n),months_between(date1, date2):返回date加或减n个月后的值,计算两个日期之间的月份差。
extract(field from datetime),trunc(date[,fmt]):从指定的日期(datetime)中提取指定的时间字段(field),按指定的格式截取输入的日期数据。
5.类型转换函数
if(cond,exp1,exp2) , ifnull(exp1,exp2) , nullif(exp1,exp2) , nvl(exp1,exp2) ,nvl2(exp1,exp2,exp3):条件判断函数。
nullif函数不支持两个参数同为clob类型或同为blob类型,并且入参exp1不能为NULL,否
则校验报错。
to_char(exp[,fmt]),to_clob(str),to_date(exp[,fmt]),to_number(n[,fmt]):将指定入参转换为char,clob,date,number类型。
SQL> select if(10>13,10,14),ifnull(10,12),nullif(10,12),nvl(10,12),nvl2(0,10,12) from sys_dummy;
IF(10>13,10,14) IFNULL(10,12) NULLIF(10,10) NVL(10,12) NVL2(0,10,12)
--------------- ------------- ------------- ------------ -------------
14 10 10 10 10
1 rows fetched.
6.最大能容纳的字符数,1~8000字节
定长字符串类型: char(size [byte | char]) 、 nchar(size)
变长字符串类型:varchar(size [byte | char])、nvarchar(size)、clob
将文本表达式、日期表达式、数字等转换为NCHAR格式,可用于格式化输出结果。
SELECT TO_NCHAR(TO_DATE('2018-06-06 10:18:36', 'yyyy-mm-dd hh24:mi:ss'), 'mm-yyyy-dd') FROM SYS_DUMMY;
TO_NCHAR(TO_DATE('2018-06-06 10:18:36', 'YYYY-MM-DD HH24:MI:SS')
----------------------------------------------------------------
06-2018-06
3.4 操作符
1.(判断题)操作符可对一个或多个操作数进行处理,位置上可能处于操作数之前、之后,或两个操作数之间。
A.正确
B.错误
答案:A
2.(判断题)常见操作符类型有逻辑操作符、比较操作符、算术运算符、测试运算符、通配符、其他操作符等。
A.正确
B.错误
答案:A
3.以下哪些是逻辑操作符?( )
A. and
B. or
C. not
D. not or
答案:ABC
4.通配符用于like和not like语句中。 ( )
A. True
B. False
答案:A
5.算术运算符中优先级最低的是^。 ( )
A. True
B. False
答案:B
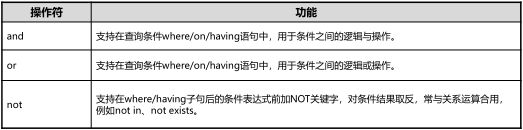
1.操作符
操作符可对一个或多个操作数进行处理,位置上可能处于操作数之前、之后,或两个操作数之间。
常见操作符类型(从使用场景划分):逻辑操作符、比较操作符、 算术运算符、测试运算符、通配符、其他操作符
2.逻辑操作符
3.通配符
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4ZzqTYDt-1587666792267)(C:\Users\asus\AppData\Roaming\Typora\typora-user-images\image-20200424011548387.png)]](http://img.e-com-net.com/image/info8/96d7f008a91a48348824b1580169f09f.jpg)
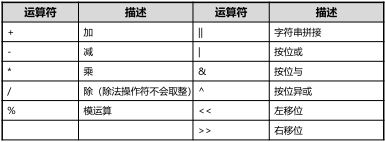
4.算术运算符优先级 优先级最低的是位或。
第四章 SQL语法分类 30%
学完本课程后,您将能够:
列举SQL语法的种类;
区分不同语句的使用场景;
使用SQL语句处理数据库中的数据。
通过本章的学习,介绍了SQL语句中的数据库查询语言DQL、数据操作语言DML、数据定义语言DDL和数据控制语言DCL,给出了每种语句的语法句式、使用场景以及典型示例。
4.1 数据查询
1.(判断题)如果在DISTINCT关键字后只有一个列,则使用该列来计算重复,如果有两列或者多列,则将使用这些列的组合来进行重复检查。
A.正确
B.错误
答案:A
2.(判断题)列和表的SQL别名分别跟在相应的列名和表名后面,中间可以加或不加一个“AS”关键字。
A.正确
B.错误
答案:A
3. 查找岗位是工程师且薪水在6000以上的记录,逻辑表达式为( )?
A. 岗位 =‘工程师’OR 薪水 > 6000
B. 岗位 = 工程师 AND 薪水 > 6000
C. 岗位 = 工程师 OR 薪水 > 6000
D. 岗位 =‘工程师’AND 薪水 > 6000
答案:D
4. WHERE子句中,表达式“age between 20 and 30”等同于( )?
A. age >= 20 and age <= 30
B. age >= 20 or age <=30
C. age > 20 and age < 30
D. age > 20 and age < 30
答案:A
5. 从student表中查询学生姓名、年龄和成绩,结果按照年龄降序排序,年龄相同的按照成
绩升序排序,下面SQL语句正确的是( )?
A. select name, age, score from student order by age desc , score;
B. select name, age, score from student order by age , score asc;
C. select name, age, score from student order by 2 desc , 3 asc;
D. select name, age, score from student order by 1 desc , 2 ;
答案:AC
考点
1.去除重复值
DISTINCT关键字
从SELECT的结果集中删除所有重复的行,使结果集中的每行都是唯一的。取值范围:已存在的字段名,或字段表达式。
语法格式
如果在DISTINCT关键字后只有一个列,则使用该列来计算重复,如果有两列或者多列,则将使用这些列的组合来进行重复检查。
select distinct job, bonus from sections;
JOB BONUS
-------------------- ------------
developer 9000
tester 7000
developer 10000
3 rows fetched.
2.别名
通过使用子句AS some_name,可以为表名称或列名称指定另一个标题名显示,一般创建别名是为了让列名称的可读性更强。
语法格式
列和表的SQL别名分别跟在相应的列名和表名后面,中间可以加或不加一个“AS”关键字。请参见下方示例:
示例:别名使用。
SELECT staff_id AS empno,course_name FROM training;
EMPNO COURSE_NAME
------------ --------------------------------------------------
10 SQL majorization
10 information safety
10 master all kinds of thinking methonds.
select a.sid, a.score math, b.score english from math a, english b where a.sid = 10 and
b.sid = 10;
SID MATH ENGLISH
------------ ------------ ------------
10 95 82
3.条件查询
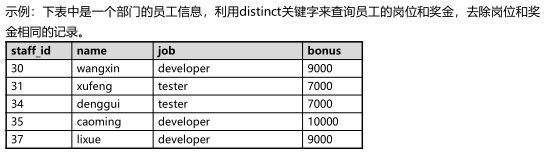
示例:从上表bonuses_depa中查询岗位为developer,且奖金>8000的职员信息。
示例:从上表bonuses_depa中查询姓wang,且奖金在8500~9500之间的职员信息。
select * from bonuses_depa where job = 'developer' and bonus > 8000;
STAFF_ID NAME JOB BONUS
------------ --------- ------------ -----------------------
30 wangxin developer 9000
select * from bonuses_depa where name like 'wang%' and bonus between 8500 and 9500;
STAFF_ID NAME JOB BONUS
----------- ---------- -------------- ------------
30 wangxin developer 9000
4.2 数据更新
1.(判断题)通过insert…select形式可以实现查询插入,但select查询的列数必须与待插入的字段数一样。
A.正确
B.错误
答案:
2.(多选题)删除数据时,可以采用下列哪些关键字?
A.trunc
B.delete
C.drop
D.truncate
答案:BD
3. 使用SQL命令将STAFFS表中员工的年龄AGE字段的值增加5岁,应该使用的命令是 ( )
A. UPDATE SET AGE WITH AGE+5
B. UPDATE AGE WITH AGE+5
C. UPDATE STAFFS SET AGE = AGE+5
D. UPDATE STAFFS AGE WITH AGE+5
答案:C
4. 下面四组SQL命令,全部属于数据操作语言的命令是( )
4.3 数据定义
A. CREATE,DROP,UPDATE
B. INSERT,UPDATE,DELETE
C. INSERT,DROP,ALTER
D. UPDATE,DELETE,ALTER
答案:B
5. 删除表student中班级(cid)为6的全部学生信息,下面SQL语句正确的是 ( )
A. delete from student where cid = 6;
B. delete * from student where cid = 6;
C. delete from student on cid = 6;
D. Delete * from student on cid = 6
答案:A
4.3 数据定义
1.(判断题)CREATE TABLE语句中IF NOT EXISTS表示:如果表已经存在,则不做改动直接返回;如果表不存在,则创建新表。
A.正确
B.错误
答案:A
2.(单选题)创建序列时,设置序列的步长应使用下列哪个关键字?
A.START WITH
B.INCREMENT BY
C.MAXVALUE
D.CYCLE
答案:B
3. 为某表建立索引,如果对索引进行撤销操作则与之对应的基本表的内容也会被删除。( )
A. 对
B. 错
答案:B
4. SQL语言集数据查询、数据操纵、数据定义和数据控制于一体,其中,CREATE、DROP、
ALTER语句是实现那种功能?( )
A. 数据查询
B. 数据操纵
C. 数据定义
D. 数据控制
答案:C
5. 创建一个递减序列seq_1,起点为400,步长为-4,最小值为100,序列到达最小值时可
循环,下面语句正确的是?( )
A. CREATE SEQUENCE seq_1 START WITH 400 MAXVALUE 100
INCREMENT BY -4 CYCLE;
B. CREATE SEQUENCE seq_1 MAXVALUE 400 MINVALUE 100
INCREMENT BY -4 CYCLE;
C. CREATE SEQUENCE seq_1 START WITH 400 MINVALUE 100
INCREMENT BY -4 CYCLE;
D. CREATE SEQUENCE seq_1 START WITH 400 MINVALUE 100
MAXVALUE 400 INCREMENT BY -4 CYCLE;
答案:BD
4.4 数据控制
1.(判断题)truncate属于DDL操作,不能 rollback。
A.正确
B.错误
答案:A
2.(判断题)事务控制提供了事务的启动、提交、两阶段提交准备、回滚、设置隔离级别操作,并支持在事务中创建保存点。
A.正确
B.错误
答案:A
3. SQL语句中“COMMIT”命令的作用是回滚一个事务( )
A. 对
B. 错
答案:B
4. 下面操作需要显式COMMIT的有( )
A. INSERT
B. DELETE
C. UPDATE
D. CREATE
答案:ABC
5. 现有空表t1,执行以下语句:
1、insert into t1 values(1,1);
2、create table t2 as select * from t1;
3、insert into t2 values(2,2);
4、rollback;
以下说法正确的是?( )
A. t1表有1条数据(1,1),t2表为空
B. t1表和t2表均为空
C. t1表有1条数据(1,1),t2表有1条数据(1,1)
D. t1表有1条数据(1,1),t2表有2条数据(1,1)和(2,2)
答案:C
第五章 数据库安全基础 13%
学完本课程后,您将能够:
描述用户、角色、权限的特性;
列举常见的系统权限和对象权限;
区分授权和权限回收的场景;
列举GaussDB T支持的审计方式。
本章首先介绍了用户、角色、权限的基础概念、使用方法和应用场景,以及三者之间的关系;接着阐述了授权和权限回收,包括语法和执行授权或权限回收操作的用户需要满足的条件;最后概述了审计及GaussDB支持的审计方式。
5.1 用户权限控制
1.(判断题)拥有DROP ANY ROLE系统权限的用户可以删除角色。
A.正确
B.错误
答案:A
2.(单选题)更改其他用户对象定义的对象权限为下列哪个选项?
A.SELECT
B.ALERT
C.DELETE
D.DROP
答案:B
3.以下哪个语法用于授权?( )
A. CREATE
B. ALTER
C. GRANT
D. REVOKE
答案:C
4.角色和用户的名字可以重复。 ( )
A. T
B. F
答案:B
5.系统权限和对象权限不使用时需及时回收。( )
A. T
B. F
答案:A
5.2 审计管理
1.(判断题)DDL类型的审计日志是对数据库表中数据的操作进行审计。
A.正确
B.错误
答案:B
2.(判断题)PL类型的审计日志会审计用户的所有操作。
A.正确
B.错误
答案:B
3.以下哪个参数是审计开关?( )
A. RECORD_SWITCH
B. RECORD_LEVEL
C. AUDIT_SWITCH
D. AUDIT_LEVEL
答案:D
4.GaussDB默认审计级别为?( )
A. 1
B. 2
C. 3
D. 4
答案:C
5.审计级别为7时,开启了哪些审计?( )
A. DDL
B. DCL
C. DML
D. PL
答案:ABC
第六章 数据库开发环境 10%
学完本课程后,您将能够:
描述数据库驱动的概念;
使用JDBC、ODBC等驱动开发应用程序;
列举GaussDB T的客户端工具;
熟练使用zsql工具进行数据库相关操作;
熟练使用Data Studio工具进行数据库相关操作。
本章主要介绍了GaussDB数据库的相关工具,jdbc、odbc、zsql、gsql等。通过本章的学习可以更好的帮助我们使用GaussDB数据库。
6.1 GaussDB数据库驱动
1.(判断题)数据库驱动是应用程序和数据库存储之间的一个接口。
A.正确
B.错误
答案:A
2.(判断题)GaussDB数据库支持JDBC与ODBC。
A.正确
B.错误
答案:A
1. 简述数据库驱动的概念。
答案:数据库驱动是应用程度和数据库存储之间的一种接口,数据库厂商为了某一种开发语言环境(比如Java,C)能够实现数据库调用而开发的类似翻译员功能的程序,将复杂的数据库操作与通信抽象成为了当前开发语言的访问接口
2. 简述JDBC开发应用的流程。
答案:开始,加载驱动。连接数据库,执行SQL语句,处理结果集,关闭连接,结束
3. 在代码中隐含加载驱动的方法是什么?
答案:Class.forName(“com.huawei.gauss.jdbc.ZenithDriver”)
6.2 数据库客户端工具
1.(判断题)DataStudio是图形化的集成开发环境,能够帮助数据库开发人员快捷地进行数据库开发。
A.正确
B.错误
答案:A
2.(判断题)GaussDB 100提供的交互和查询的客户端工具是zsql。
A.正确
B.错误
答案:A
3. 简述ODBC开发应用的流程。
答案:开始,申请句柄资源,设置环境属性,连接数据源,执行SQL语句,处理结果集,断开连接,释放句柄资源,结束
4. 简述分配和释放ODBC句柄接口的语法格式。
答案:SQLRETURN SQL_API SQLAllocHandle(SQLSMALLINT HandleType,SQLHANDLE InputHandle,SQLHANDLE *OutputHandle)
SQLRETURN SQL_API SQLFreeHandle(SQLSMALLINT HandleType, SQLHANDLE Handle)
5. GaussDB T除了支持基于JDBC和ODBC驱动的开发,还支持哪些其他驱动的开发?
答案:GSC(C-API),Python,go
第七章 数据库设计基础 14%
学完本课程后,您将能够:
描述数据模型的特点和用途;
列举数据模型的类型;
描述第三范式数据模型的标准;
描述逻辑模型中的常见概念;
区别逻辑模型和物理模型中对应的概念;
列举物理设计过程中常见的反范式化处理手段。
在这一章中,围绕着数据库建模的新奥尔良法,对需求分析,概念设计,逻辑设计和物理
设计这四个阶段进行了介绍和讲解,对每一个设计阶段的任务都进行了明确说明。
对需求分析阶段的重要意义进行了阐述。
在概念设计阶段引入了E-R方法。
在逻辑设计一节中阐述了重要的基本概念和三范式模型,并结合实例对各层范式进行了深
入讲解。
在物理设计阶段重点讲解了反范式化手段和工作中需要关注的重点。
最后是结合一个小型的实际案例把逻辑建模和物理建模的主要内容进行了说明。
7.1 数据库设计概述
1.(判断题)数据库设计的目标是为用户和各种应用系统提供一个信息基础设施和高效的运行环境。
A.正确
B.错误
答案:A
2.在新奥尔良设计方法中逻辑设计完成后接下来需要完成的阶段是 ( )
A. 需求分析
B. 物理设计阶段
C. 概念设计阶段
D. 逻辑设计阶段
答案:B
3.数据库运行环境的高效性,表面在哪些方面?( )
A. 数据存取效率
B. 数据存放的时间周期
C. 存储空间利用率
D. 数据库系统运行管理的效率
答案:ACD
4.进行需求调查的过程中,可以使用的方法包括以下哪些选项?( )
A. 问卷调查
B. 和业务人员座谈调研;
C. 采集样本数据,进行数据分析
D. 评审《用户需求规格说明书》
答案:ABC
7.2 需求分析
1.(判断题)需求分析阶段主要是收集信息并进行分析和整理,为后续阶段提供充足信息。
A.正确
B.错误
答案:A
2.(多选题)数据字典是对数据的描述,其包含下列哪些选项?
A.数据项
B.数据结构
C.数据存储
D.数据流
答案:ABCD
3. 模型设计中E-R图的三要素包括下面哪些选项? ( )
A. 实体
B. 联系
C. 基数
D. 属性
答案:ABD
4. 属于实体间联系的选项是( )
A. 一对一联系(1:1)
B. 一对空联系(1:0)
C. 一对多联系(1:n)
D. 多对多联系(m:n)
答案:ACD
5. 具有公共性质并且可以相互区分的现实世界对象的集合是E-R方法中的属性。( )
A. True
B. False
答案:B
7.3 概念设计
1.(判断题)概念模型的主要特点是能真实、充分地反映现实世界,包括事物和事物之间的联系,是现实世界的真实模型。
A.正确
B.错误
答案:A
2.(多选题)下列哪些选项属于实体?
A.飞行员
B.学生
C.身高
D.性别
答案:AB
3. 在新奥尔良设计方法中逻辑设计完成后接下来需要完成的阶段是 ( )
A. 需求分析
B. 物理设计阶段
C. 概念设计阶段
D. 逻辑设计阶段
答案:B
4. 模型设计中E-R图的三要素包括下面哪些选项?( )
A. 实体
B. 联系
C. 基数
D. 属性
答案:ABD
5. 在逻辑模型设计过程中进行范式化建模的意义是?( )
A. 提升数据库使用效率
B. 减少数据冗余
C. 模型具有良好的可扩展性
D. 减少数据不一致的可能性
答案:BCD
6. 满足第三范式的模型就一定是满足第二范式的。( )
A. True
B. False
答案:A
7.4 逻辑设计
1.(判断题)唯一标识一个实例,无重复值,非空。
A.正确
B.错误
答案:A
2.(判断题)识别性关系发生在独立型实体和依赖型实体之间。
A.正确
B.错误
答案:A
3. 相对于逻辑模型而言,物理模型具备的特点是 ( )
A. 严格遵守第三范式
B. 可以含有冗余数据
C. 主要面向DBA和应用开发人员使用
D. 可以含有派生数据
答案:BCD
4. 数据反范式化处理的方式,包括下列哪些选项?( )
A. 增加派生字段
B. 建立汇总表或临时表
C. 预关联
D. 增加重复组
答案:ABCD
5. 使用索引带来的影响有( )
A. 会占用更多的物理存储空间
B. 索引生效的情况下,能够大幅提升查询的效率
C. 插入基表的效率会有下降
D. 建立索引后,数据库优化器就一定会在查询中使用索引
答案:ABC
6. 因为分区能够减少数据查询时候IO扫描的开销,所以在物理化建设过程中,对于分区应当建立的越多越好。( )
A. True
B. False
答案:B
7.5 物理设计
1.(判断题)物理设计最终目的是转化为目标数据库的可部署的定义语言(DDL)。
A.正确
B.错误
答案:A
2.(判断题)反范式处理可能会带来数据冗余问题。
A.正确
B.错误
答案:A
3. 识别实体中每一个实例的唯一性的对象是外键?( )
A. True
B. False
答案:B
4. 满足第一范式的原子性就是把每个属性都切分到不可再分的最细粒度。( )
A. True
B. False
答案:B
5. 只有存在外键,实体之间才会存在关系,没有外键不能建立两个实体之间的关系( )
A. True
B. False
答案:A
6. 建立逻辑模型过程中,下面哪些选项属于确定实体中的属性的工作范围?( )
A. 定义实体的主键
B. 定义部分非键属性
C. 定义非唯一属性组
D. 定义属性的约束
答案:ABC
7.6 数据库设计案例
第八章 华为GaussDB数据库 10%
学完本课程后,您将能够:
了解GaussDB数据库的特性;
了解GaussDB数据库的应用场景。
本章主要介绍了华为GaussDB T数据库与华为GaussDB A数据库的特性和应用案例,了解了GaussDB的业务价值。
8.1 GaussDB 100数据库介绍
1.(单选题)( )是基于RDMA技术构建的全局缓存机制。
A.GBP
B.CBP
C.HBP
D.DBP
答案:A
2.(单选题)以下哪个选项不属于GaussDB 100的部署形态?
A.单机部署
B.主备部署
C.全分布式部署
D.主从部署
答案:D
3. GaussDB T属于什么类型数据库?
答案:关系型数据库,应用于OLTP场景。
4. GaussDB T可应用于哪些场景?
答案:金融,互联网。
5. GaussDB T支持哪几种部署模式
答案:单机,主备,分布式。
8.2 GaussDB 200数据库介绍
1.(判断题)GaussDB 200支持并行Bulk Load技术,提供10TB级/h加载性能。
A.正确
B.错误
答案:A
2.(判断题)GaussDB 200支持标准SQL2003,支持数据库事务ACID特性。
A.正确
B.错误
答案:A
3. 数据迁移工具Migration Tool支持迁移哪些数据库数据到GaussDB A?
答案:Oracle,teredata
4. GaussDB A数据库应用场景有哪些?
答案:金融,电信,公共安全。
5. GaussDB A可访问华为FusionInsight HD集群数据 ( )?
A. True
B. False
答案:A
HCIA-GaussDB V1.0 模拟试卷
1.(单选) 除了根节点外的节点有且只有一个双亲节点,这说的是哪一个数据模型的特点?( C )
A. 关系型模型
B. 面向对象模型
C. 层次模型
D. 网状模型
2.(单选) 在Share-Disk架构中,容易导致系统瓶颈的硬件资源是?( C )
A. CPU
B. 内存
C. 磁盘IO
D. 带宽
3.(多选) 下列关于Function(函数)的描述中,正确的选项有?( ACD )
A. 完成特定功能的SQL语句集合
B. 无需被编译就可以运行
C. 可以被重复调用
D. 可以减少数据库开发人员的重复工作量
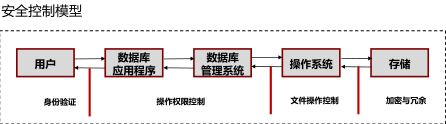
4.(单选) 下列哪些方法属于安全控制的手段?( D )
A. 身份验证
B. 操作权限控制
C. 文件操作控制
D. 以上全都正确
5.(多选) 关于备份,下面论述中正确的是?( ABD )
A. 全备是增量备份和差异备份的基础,没有全备,无法进行增量备份或差异备份。
B. 全备份的周期要根据系统的整体容量和可以使用的时间窗口来综合评估,不能盲目追求高频次的全备份。
C. 增量备份就是在全量备份的基础上每次备份出增加的那部分数据。
D. 备份出来的数据也有丢失的风险,所以在做备份要考虑备份数据的生命周期,保证有多个可用的数据备份。
6.(判断) 索引能够加速查询,所以建立的越多越好。( B )
A. TRUE
B. FALSE
7.(多选)当事务T1读取数据X的过程中,第一次读取B=200,第二次读取B=400,为了避免这种情况,事务T1可以采用哪种事务隔离机制?( BD )
A. Read Committed
B. Serializable
C. ReadUncommitted
D. Repeatable read
8.(判断) ORDER BY默认排序方向为升序。?( A )
A. True
B. False
9.(单选) SQL语法中,使用什么子句可以筛选分组后的数据?( D )
A. GROUP BY
B. ORDER BY
C. WHERE
D. HAVING
10.(单选) 现有表TI和T2,分别有2行数据和3行数据,那么使用查询语句select * from T1,T2;返回的结果集有多少行记录?( A )
A. 6
B. 5
C. 4
D. 3
11.(多选)下面关于union和union all说法正确的是?( AD )
A. union会过滤重复的记录
B. union不会过滤重复的记录
C. union all会过滤重复的记录
D. union all不会过滤重复的记录
12.(判断)SYS用户不允许被创建。( A )
A. TRUE
B. FALSE
13.(单选)拥有哪个系统权限可以创建新用户?( A )
A. CREATE USER
B. CREATE ROLE
C. ALTER USER
D. ALTER ROLE
14.(多选) 用户、角色和权限之间的关系,下列哪些选项描述正确?( ABC )
A. 用户可以定义角色
B. 角色为多个权限的集合
C. 如果将角色赋予用户,则用户具有该角色的所有权限
D. 用户与角色一一对应
15.(多选)GaussDB 100默认开启了哪些审计类型?( AB )
A. DDL
B. DCL
C. DML
D. PL
16.(单选) 某数据库管理员只想对存储过程的解析与执行进行审计,则AUDIT_LEVEL的值应设置为下列哪个选项?( D )
A. 1
B. 3
C. 5
D. 8
17.(判断) 数据库驱动是驱动管理器和数据库存储之间的一种接口。( B )
A. TRUE
B. FALSE
18.(多选) 下面哪些情况可以用实体的嵌套关系反映出来?( ABD )
A. 上下级部门
B. 老师和学生
C. 产品和产品组
D. 员工和领导
19.(多选) 在给字段增加约束的时候,下面说法不正确的是?( ABD )
A. 即便取值肯定不为空,也不要增加NOT NULL约束,因为优化器可能无法对SQL进行优化
B. DEFAULT的约束尽可能加上,这样表的数据就不会因为数据缺失而导致大量空值存在
C. 主键约束等价于唯一约束加上非空约束
D. 索引一定要有唯一性约束才能有很好的性能
20.(多选) GaussDB 100的主要特点有哪些?( ABC )
A. 极致性能
B. 安全可靠
C. 简单易用
D. 是NoSQL数据库
考试一
1. 拥有DROP ANY ROLE系统权限的用户可以删除角色。
A.正确
B.错误
答案:
2. 物理设计最终目的是转化为目标数据库的可部署的定义语言(DDL)。
A.正确
B.错误
答案:
3. GaussDB 200中列存向量化支撑PB级数据的深度分析与挖掘。
A.正确
B.错误
答案:
4. GaussDB数据库支持JDBC与ODBC。
A.正确
B.错误
答案:
5. CREATE TABLE语句中IF NOT EXISTS表示:如果表已经存在,则不做改动直接返回;如果表不存在,则创建新表。
A.正确
B.错误
答案:
6. 识别性关系发生在独立型实体和依赖型实体之间。
A.正确
B.错误
答案:
7. 视图和基本表一样,在物理上是实际存在的。
A.正确
B.错误
答案:
8. integer unsigned表示32位有符号整数。
A.正确
B.错误
答案:
9. 反范式处理可能会带来数据冗余问题。
A.正确
B.错误
答案:
10. 唯一标识一个实例,无重复值,非空。
A.正确
B.错误
答案:
11. SQL语法中,使用什么子句可以筛选分组后的数据?
A. GROUP BY
B. HAVING
C. ORDER BY
D. WHERE
12. 拥有哪个系统权限可以创建新用户?
A. ALTER USER
B. CREATE ROLE
C. ALTER ROLE
D. CREATE USER
13. 下列关于主从架构描述正确的是?
A. 读写都在主机完成
B. 查询在从机完成,写入在主机完成
C. 查询在主机完成,写入在从机完成
D. 读写都在从机完成
14. 以下哪个选项是GaussDB 100提供的交互和查询的客户端工具?
A. sqlplus
B. gsql
C. zsql
D. mysql
15. 以下哪种数据分布策略适合于记录集较小的表?
A. replication
B. range
C. list
D. hash
16. 创建序列时,设置序列的步长应使用下列哪个关键字?
A. INCREMENT BY
B. MAXVALUE
C. CYCLE
D. START WITH
17. 现有表TI和T2,分别有2行数据和3行数据,那么使用查询语句select * from T1,T2;返回的结果集有多少行记录?
A. 5
B. 6
C. 4
D. 3
18. 下列哪些方法属于安全控制的手段?
A. 文件操作控制
B. 身份验证
C. 操作权限控制
D. 以上全都正确
19. 在Share-Disk架构中,容易导致系统瓶颈的硬件资源是?
A. CPU
B. 带宽
C. 磁盘IO
D. 内存
20. 某数据库管理员只想对存储过程的解析与执行进行审计,则AUDIT_LEVEL的值应设置为下列哪个选项?
A. 8
B. 5
C. 3
D. 1
21. 当事务T1读取数据X的过程中,第一次读取B=200,第二次读取B=400,为了避免这种情况,事务T1可以采用哪种事务隔离机制?(多选)
A. Serializable
B. Read Committed
C. Repeatable read
D. ReadUncommitted
22. 下面关于union和union all说法正确的是?(多选)
A. union不会过滤重复的记录
B. union会过滤重复的记录
C. union all不会过滤重复的记录
D. union all会过滤重复的记录
23. 下列哪些选项属于关系型数据库ACID特性?(多选)
A. 统一性
B. 原子性
C. 隔离性
D. 持久性
24. GaussDB 100默认开启了哪些审计类型?(多选)
A. DML
B. PL
C. DDL
D. DCL
25. 用户、角色和权限之间的关系,下列哪些选项描述正确?(多选)
A. 如果将角色赋予用户,则用户具有该角色的所有权限
B. 角色为多个权限的集合
C. 用户与角色一一对应
D. 用户可以定义角色
26. GaussDB 100的主要特点有哪些?(多选)
A. 简单易用
B. 安全可靠
C. 极致性能
D. 是NoSQL数据库
未归类
GaussDB 200在部署时,对服务器没有要求,推荐部署在异构服务器上。单选
A.TRUE
B.FALSE
正确答案:B
GaussDB 200具有哪些特点?多选
A.高可靠
B.高性能
C.高拓展
D.易用
正确答案:ABCD
GaussDB 100是款完全自研的交易型数据库。单选
A.TRUE
B.FALSE
正确答案:A
GaussDB 100主要用于单数据中心,目前不支持多地域部署。单选
A.TRUE
B.FALSE
正确答案:B
GaussDB 200支持列存、向量化执行技术,可以支撑PB级数据的深度分析与挖掘。单选
A.TRUE
B.FALSE
正确答案:A
依赖型实体中的主键必须是独立实体主键的全部,而不能是一部分。单选
A.TRUE
B.FALSE
正确答案:B
下列哪些选项符合二范式的论述 ?单选
A.The KEY
B.The WHOLE Key
C.NOTHING But theKey
D.以上全都正确
正确答案:B
实体之间的识别性关系也可以发生在两个独立实体之间单选
A.TRUE
B.FALSE
正确答案:A
下列哪些选项是对逻辑模型进行反范式处理所带来的结果?多选
A.会不满足第三范式
B.会带来数据冗余的情况
C.会导致数据不致的问题
D.会带来数据查询的性能提升
正确答案:ABC
下列关于范式理论,描述正确的选项是?多选
A.低级范式的关系模式通过模式分解一定能够转换为更高等级的范式关系
B.在物理模型设计过程中,最后建立的模型一定要完全满足第三范式
C.设计模型越理想越好,所以尽可能把模型范式做到5NF
D.星型模型,雪花型模型也是符合第三范式的
正确答案:BC
在给字段增加约束的时候,下面说法不正确的是?多选
A.主键约束等价于唯一约束加上非空约束
B.索引一定要有唯一性约束才能有很好的性能
C.即便取值肯定不为空,也不要增加NOT NULL约束,因为优化器可能无法对SQL进行优化
D.DEFAULT的约束尽可能加上,这样表的数据就不会因为数据缺失而导致人量空值存在
正确答案:BCD
按照三范式的理论进行逻辑建模带来的好处包括以下哪些选项?多选
A.提升应用的访问性能
B.消除数据不一致的情况
C.让模型可扩展性强
D.减少数据冗余
正确答案:BCD
zsql连接数据库时参数w表示客户端连接数据库时的等待超时时间,则-w- 1和-w 0分别表示什么? 单选
A.不等待超时,等待不超时
B.不等待超时,等待超时
C.等待不超时,不等待超时
D.等待不超时,等待超时
正确答案:C
A公司小张需要查看表privilege的定义信息,因此执行如下SQL语句: SQL> CREATE TABLE privilege(staff_id INT PRIMARY KEY, privilege_name VARCHAR(64) NOT NULL,privilege_description VARCHAR(64), privilege_approver VARCHAR(10)); SQL> DESC privilege;单选
A.TRUE
B.FALSE
正确答案:A
zsql支持下列哪些登陆方式?多选
A.图形化登陆
B.交互方式登陆
C.非交互方式登陆
D.静默登陆
正确答案:BC
zsql安装成功后,首次登陆必须使用sysdba用户才可以成功登陆。单选
A.TRUE
B.FALSE
正确答案:B
JDBC驱动应用开发连接数据库时,需要下列哪些参数?多选
A.数据库URL
B.数据库数据大小
C.数据库用户名
D.数据库密码
正确答案:ACD
以下哪些为数据库用户的用途?多选
A.访问数据库对象
B.权限组织及划分
C.执行SQL语句
D.连接数据库
正确答案:ACD
创建用户时密码可以随意设置。单选
A.TRUE
B.FALSE
正确答案:B
审计日志是安全事件中事后追溯、定位问题原因及划分事故责任的重要手段。单选
A.TRUE
B.FALSE
正确答案:A
角色不能与数据库已有的用户名或角色名重名。单选
A.TRUE
B.FALSE
正确答案:A
SYS用户不允许被创建。单选
A.TRUE
B.FALSE
正确答案:A
以下哪个语法用于权限回收?单选
A.GRANT
B.REVOKE
C.CREATE
D.ALTER
正确答案:B
若想要查询表student班级为1班且成绩排名前5名的学生信息,以下语句能实现的是?单选
A.select * from student where class_id =1 order by score desc limit 5;
B.select * from student where class_id=1 group by score limit 5;
C.select * from student where class id=1 order by score desc offset 5;
D.select * from student where class_id=1 order by score limit 5;
正确答案:A
table A与table B进行连接查询,下列哪种连接查询可以返回table A的所有记录且table B只返回符合连接条件的记录?单选
A.Right join
B.Inner join
C.left join
D.full join
正确答案:C
下面创建索引的语句正确的是?多选
A.CREATE INDEX T1_ind1,T1_ind2 ON T1(f1,f2).
B.CREATE INDEX T1_ind ON T1(f1 ASC,f2) ONLINE:
C.CREATE UNIQUE INDEX T1_ind ON T1(f1, f2);
D.CREATE INDEX T1_ind ON T1(f1) ;
正确答案:BCD
命令ORDER BY A, B DESC表示的含义是? 单选
A.查询结果先按A降序排序,然后再按B升序排序
B.查询结果先按A升序排序,然后再按B降序排序
C.查询结果先按A升序排序,然后再按B升序排序
D.查询结果先按A降序排序,然后再按B降序排序
正确答案:B
下面命令表示查询结果跳过前2行记录后输出5行记录的是? 单选
A.limit 5, 2
B.limit 2, 5
C.limit 5 offset 2
D.offset 2 limit 5
正确答案:B
提交事务并不意味着事务的结束,只是对事务当前工作进行保存。单选
A.TRUE
B.FALSE
正确答案:B
下面哪种别名用法是正确的?多选
A.select staff_id “id” from staffs;
B.select staff_id as id from staffs;
C.select staffl_id ‘id’ from staffs;
D.select staff_id id from staffs;
正确答案:ABD
在数据库中可以创建和删除表视图、索引,也可以修改表。这是因为数据库管理系统提供了什么功能? 单选
A.数据控制功能
B.数据维护功能
C.数据定义功能
D.数据操纵功能
正确答案:C
ORDER BY默认排序方向为升序。单选
A.TRUE
B.FALSE
正确答案:A
数据操INSERT、DELETE、UPDATE提交是默认关闭的,会话退出时,需要显COMMIT, 否则记录将丢失。单选
A.TRUE
B.FALSE
正确答案:A
如果想要删除当前用户的索引,不需要授予额外权限。单选
A.TRUE
B.FALSE
正确答案:B
创建表时定义某列值不能为NULL.应使用下列哪个约束条件? 单选
A.NOT NULL
B.!=NULL
C.≠ NULL
D.NOT
正确答案:A
如果想从表中删除所有的行,只能使用delete语句完成。单选
A.TRUE
B.FALSE
正确答案:B
SQL语句包括以下哪几类? 多选
A.DCL
B.DDL
C.DML
D.DQL
正确答案:ABCD
用户B想查询表T的数据,在授权的时候只给予select的权限,而不给予delete和update的权限。这种权限管理方式符合哪种原则?单选
A.精准权限管理
B.最小权限管理
C.关键权限管理
D.基于角色的权限管理
正确答案:B
索引能够加速查询,所以建立的越多越好。单选
A.TRUE
B.FALSE
正确答案:B
GaussDB在默认设置情况下,会把第一个可执行的SQL作为事务的开始。单选
A.TRUE
B.FALSE
正确答案:A
下列属于并发类控制资源的有哪几项?单选
A.队列
B.互斥信号
C.缓存
D.以上全都正确
正确答案:D
对大表进行分区能够带来的收益包括下列哪些选项?单选
A.可以减少搜索空间,提升访问性能
B.批量删除可以通过删除对应的分区快速实现
C.集中删除对应的分区,可以减少清理存储碎片的工作量
D.以上全都正确
正确答案:D
同个表可以创建多个不同的视图,既可以使用字段作为过滤条件创建视图,也可以使用行记录作为过滤条件创建视图。单选
A.TRUE
B.FALSE
正确答案:A
两个表进行关联,为了保证效率和正确的执行计划,发生关联的字段除了类型要一致以外,命名也必须完全致。单选
A.TRUE
B.FALSE
正确答案:B
数据库常见的约束类型包括下列哪些选项?多选
A.唯一性约束
B.外键约束
C.非空约束
D.键约束
E.默认约束
正确答案:ABCE
在数据库集群里面.采用同步机制能够保证所有的节点数据都更新成功,所以在集群里面优先采用同步复制方式而不是异步复制方式。单选
A.TRUE
B.FALSE
正确答案:B
GaussDB 200数据库适用于下列哪些计算场景?多选
A.大并发插入在线数据
B.统计历史业绩,对未来的业务发展进行预测分析
C.响应在毫秒级的高并发查询
D.复杂的报表统计和分析
正确答案:BD
在Share- Disk架构中,容易导致系统瓶颈的硬件资源是?单选
A.内存
B.CPU
C.带宽
D.磁盘I0
正确答案:D
下列哪些场景会涉及到复杂查询(多表关联分析)?多选
A.个人征信分析
B.个人信贷资料流失率分析
C.车辆区域对碰分析
D.人员亲密度关系分析
E.老乡同列车分析
正确答案:ABCD
GaussDB 100用于实现AZ内高可用,提供秒级快速倒换的特性叫做? 单选
A.Quick Switch
B.Switch Smart
C.Flash Back
D.Switch Turbo
正确答案:D
闪回特性访问的是undo页上的数据。单选
A.TRUE
B.FALSE
正确答案:A
GaussDB 200使用的是MPP架构。单选
A.TRUE
B.FALSE
正确答案:A
同AZ下,GaussDB 100可保证RPO在秒级。单选
A.TRUE
B.FALSE
正确答案:A
GaussDB 100可应用于下列哪些行业?多选
A.金融
B.政府
C.电信
D.电力
正确答案:ABCD
如果A实体的主键成为B实体的非键属性,那么A实体和B实体之间的关系是? 多选
A.A和B是父子实体关系
B.A和B不是父子实体关系
C.A和B是识别性关系
D.A和B是非识别性关系
正确答案:AD
需求分析阶段完成后,提供的需求分析材料包括以下哪些选项?多选
A.E-R图
B.建表语句
C.数据字典
D.用户需求规格说明书
正确答案:CD
需求分析阶段在了解用户的期望和目标基础上注意引导用户,避免需求无限制扩大。单选
A.TRUE
B.FALSE
正确答案:A
需求分析阶段随便做下,通过迭代式的过程在后续阶段找时机改正就可以了。单选
A.TRUE
B.FALSE
正确答案:B
物理建模是为了解决效率问题,所以只要能带来效率提升的处理方法都是可以采用的。单选
A.TRUE
B.FALSE
正确答案:B
需求分析阶段的工作内容,包括以下哪些选项到。多选
A.了解相关业务流程
B.了解当前已有系统的情况
C.了解新系统的功能要求
D.采集一些基础数据
正确答案:ABCD
概念模型是把现实反映到数据库设计的阶段。所以既要反映现实世界。又要和实现模型的特定数据库紧密结合,发挥目标数据库的专有性。单选
A.TRUE
B.FALSE
正确答案:B
概念设计中使用的E-R图由下列哪些选项构成?多选
A.联系
B.字段
C.实体
D.属性
E.表
正确答案:ACD
在逻辑导入和逻辑导出时,FILETYPE-BIN时,会导出哪几类文件?多选
A.数据文件CD文件)
B.用户指定的文件
C.LOB文件(.L文件)
D.元数据文件
正确答案:ABC
JDBC常用接口可实现下列哪些功能?多选
A.数据库删除
B.执行SQL语句
C.数据库卸载
D.执行存储过程
正确答案:BD
下列哪个zsql参数可以设置GaussDB 100数据库的列宽度? 单选
A.COL
B.COL_WD
C.COL_W
D.COLU
正确答案:A
通过zsql或者JDBC等API方式远程接入数据库之自前,需要在配置文件zengine. ini中设置监听的IP地址和端口号。一次最多可以设置多少个监听的IP地址。单选
A.8
B.9
C.7
D.6
正确答案:A
用户hr在执行zsql [email protected]:1611 -s silent.1og命令时,有哪些需要注意的地方?多选
A.该SQL语句在无提示模式下执行
B.回显到当前屏幕
C.执行结果会统输出到指定文件中
D.使用-s参数时需放置在命令末尾
正确答案:AC
当审计级别为15时,GaussDB 100数据库开启了哪些审计类型? 多选
A.DCL
B.DDL
C.PL
D.DML
正确答案:ABCD
GaussDB 100数据库系统预置的用户有哪些?多选
A.RESOURCE
B.SYS
C.PUBLIC
D.DBA
正确答案:BC
被授予DBA角色的用户拥有以下哪些权限?单选
A.CREATE USER
B.CREATE ROLE
C.CREATE SESSION
D.以上全都正确
正确答案:D
用户要修改审计级别需要有以下哪个系统权限? 单选
A.ALTER LOG
B.ALTER AUDIT
C.ALTER LEVEL
D.ALTER SYSTEM
正确答案:D
以下哪个参数为审计开关。单选
A.AUDIT_ LEVEL
B.RECORD_LEVEL
C.AUDIT_SWITCH
D.RECORD_SWITCH
正确答案:A
系统权限、角色和对象权限的授了都要遵循最小化使用原则。单选
A.TRUE
B.FALSE
正确答案:A
以下哪些为审计日志的类型?多选
A.DCL
B.DML
C.PL
D.DDL
正确答案:ABCD
下列哪个对象权限可以访问其他用户的对象?单选
A.INSERT
B.UPDATE
C.ALTER
D.SELECT
正确答案:D
现有两个表A、B,有相同列id,若要更新表A中id和表B中id相同的记录且修改A表中的列name为'Gauss' ,以下语句可以实现的是 单选
A.update A join B where A.id=B.id set A.name ='Gauss';
B.alter table A join B on A.id=B.id set A.name='Gauss';
C.update A join B set A.name ='Gauss';
D.update A join B on A.id=B.id set A.name ='Gauss';
正确答案:D
现有表student,包含学号(sid)、班级(class)、课程编号(course)和成绩(score)等字段,若想要查询每个班级每个课程的平均成绩。下列语句能实现的是? 单选
A.select class, course, avg (score) from student group by course order by class;
B.select class, course, avg (score) from student group by class:
C.select class, course, avg(score) from student group by course:
D.select class, course, avg(score) from student group by class, course;
正确答案:D
现有员工表A,包含员工id(staff_id).和部门id(section_id)两字段,部门表B,包含部门id (section_id) 和部所在城市(city)两字段,若想要查询该公司每个城市的员工数,以下语句可以实现的是?单选
A.select city, count(staff _id) from A joinB on A. section _id = B. section_id group by B. section;
B.select city, count(staff id) from A,B group by city;
C.select city,count(staff_ id) from A join B where A. section_id=B. section_id group by city;
D.select city,count(staff_id) from A join B on A.section_id= B.section_id group by city;
正确答案:D
现有表TI和T2,分别有2行数据和3行数据,那么使用查询语句select * from T1, T2;返回的结果集有多少行记录? 单选
A.5
B.6
C.3
D.0
正确答案:B
下面关于GROUP BY的用法正确的是? 多选
A.select id, score from student group by id,score;
B.select id, sum(score) from student group by id;
C.select sum(score) from student group by id;
D.select id, score from student group by id;
正确答案:ABC
在表student中添加年龄age列,下面语句正确的是? 单选
A.alter table student add age;
B.alterr table student with age;
C.alter table student add age int;
D.alter table student with age int;
正确答案:C
GROUP BY后面的表达式支持的格式有。单选
A.group by (expr1, expr2)
B.group by (expr1), (expr2)
C.group by (expr1, expr2),expr3
D.group by expr1, expr2,expr3
正确答案:D
创建视图A时,若A视图已存在则更新A视图,那么应使用的关键字是?单选
A.UPDATE
B.OR UPDATE
C.REPLACE
D.OR REPLACE
正确答案:D
下面关于子查询说法错误的是? 单选
A.查询执行时先执行主查询再执行子查询
B.子查询中可以包含ORDER BY而不能包含GROUP BY
C.子查询可以引用外部查询表中的列
D.主查询和子查询必须从相同的表中获取数据
正确答案:D
FROM子句中的子查询也可以称为嵌套子查询。单选
A.TRUE
B.FALSE
正确答案:B
以下属于视图的DDL操作有?多选
A.清空视图中的数据
B.删除视图
C.修改视图
D.创建视图
正确答案:BCD
删除索引ind_1,下列语句正确的是?单选
A.DROP SEQUENCE ind_1
B.DROP INDEX ind_1
C.DELETE SEQUENCE ind_1
D.DELETE INDEX ind_1
正确答案:B
用户可通过TRUNCATE TABLE语句删除表中所有的行,若想恢复数据,可回滚事务。单选
A.TRUE
B.FALSE
正确答案:B
序列可以产生一组等间隔的数值,能自增,主要用于表的主键。单选
A.TRUE
B..FALSE
正确答案:A
以下不属于数据库对象的是? 单选
A.索引
B.用户
C.视图
D.数据模型
正确答案:D
如果在SELECT语句中使用聚集函数。一定要使用?单选
A.JOIN
B.HAVING
C.GROUP BY
D.ORDER BY
正确答案:C
以下不属于DDL命令的是?单选
A.ALTER
B.DROP
C.COMMIT
D.CREATE
正确答案:C
下列语句中,与”A BETWEEN 5 AND 10”等价的是?单选
A.A>= 5 AND A<=10
B.A>=5 OR A <=10
C.A>5 OR A<10
D.A>5 AND A<10
正确答案:A
%通配符表示确切的一个末知字符。用于like和not like语句中。单选
A.TRUE
B.FALSE
正确答案:A
GaussDB 100数据库不支持二进制数据类型。单选
A.TRUE
B.FALSE
正确答案:B
在OLAP应用中,CPU利用率达到100%的SQL都是有问题的,需要进行优化,把CPU利用率给降下来。单选
A.TRUE
B.FALSE
正确答案:B
关于备份,下面论述中正确的是?多选
A.增量备份就是在全量备份的基础上每次备份出增加的那部分数据。
B.备份出来的数据也有丢失的风险,所以在做备份要考虑备份数据的生命周期,保证有多个可用的数据备份。
C.全备是增量备份和差异备份的基础,没有全备,无法进行增量备份或差异备份。
D.全备份的周期要根据系统的整体容量和可以使用的时间窗口来综合评估,不能盲目追求高频次的全备份。
正确答案:BCD
用户A想查询表Y的数据,目前用户B是可以直接查询表Y的,另外系统中还有角色C,能够对表Y进行增删改的操作。下面的权限管理操作中,正确的选项包括?多选
A.授子用户A查看表Y的权限
B.让用户A使用B的账号登陆数据库系统进行数据查看
C.创建一个新角色D 授权角色D能够查看表Y的权限,然后把角色D授子用户A
D.把角色C授予A.这样A就可以访问表Y了
正确答案:AC
使用数据库连接池的目标是?单选
A.可以免密登陆
B.增大系统的并发量
C.可以复用session资源
D.降低频繁连接数据库带来的开销,提高数据库资源利用率
正确答案:D
数据库扩容是一个复杂而繁琐的系统工作,所以为了减少对系统的影响,应在设计阶段尽可能留出充足的资源富余量,硬件资源配置的越多越好。单选
A.TRUE
B.FALSE
正确答案:A
数据库的实例是操作系统中一系列的进程以及为这些进程所分配的内存块。单选
A.TRUE
B.FALSE
正确答案:A
数据库迁移工作要考虑下列哪些因素?单选
A.迁移操作可以使用的时间窗
B.数据源和目标系统之间的硬件资源差异
C.需要迁移的数据量
D.以上全都正确
正确答案:D
把表进行分区带来很多好处,所以在建表的时候,分区应大量创建而且粒度要最细化。单选
A.TRUE
B.FALSE
正确答案:B
下列选项中对Schema表述正确的是?多选
A.形成命名空间,避免命名冲突。
B.和用户等价,用来区分不同用户所属的对象。
C.数据库对象的集合,构成逻辑组,便于管理。
D.Schema的搜索顺序根据创建的先后顺序排序。
正确答案:AC
在数据库集群里面,采用同步机制能够保证所有的节点数据都更新成功,所以在集群里面优先采用同步复制方式而不是异步复制方式。单选
A.TRUE
B.FALSE
正确答案:B
数据库管理系统和操作系统之间的关系是?单选
A.操作系统调用数据库管理系统
B.并发运行
C.相互调用
D.数据库管理系统调用操作系统
正确答案:C
下面的选项中,不属于数据库系统的是?多选
A.数据库
B.数据库服务器
C.操作系统
D.数据库管理系统
正确答案:BC
链接: HCIA-GaussDB 华为认证数据库工程师.
链接: HCIA-Cloud Computing华为认证云计算工程师.
链接: HCIA-Intelligent Computing 华为认证智能计算高级工程师.
链接: HCIA-Routing&Switching华为认证路由交换工程师.
链接: HCIA-Kunpeng Application Developer鲲鹏.
链接: HCIA-AI 华为认证AI工程师.