生成对抗网络初步学习Generative Adversarial Network(GAN)
文章目录
- 一、起源
- 二、GAN的思想
- 三、组成
- 四、GAN的优缺点
- 1)GAN的优点
- 2)GAN的缺点
- 为什么GAN中不常用SGD?
- 为什么GAN不适合处理文本数据?
- 五、GAN的广泛应用
- 六、pytorch搭建生成对抗网络
一、起源
该结构由Ian Goodfellow等人在2014年发表的论文《Generative Adversarial Network》中给出。
论文地址:https://arxiv.org/pdf/1406.2661.pdf
源码地址:https://github.com/eriklindernoren/Keras-GAN
https://github.com/eriklindernoren/PyTorch-GAN
附:https://github.com/goodfeli/adversarial(此为作者提供的代码库,但是因为没有相关训练说明以及文件说明,建议先阅读源码地址中的复现版本)sheng
生成对抗网络是一种无监督学习方法,是一种通过对抗网络来训练生成网络,它由两个网络组成:用来你和数据分布的生成网络G,和用来判断输入是否“真实”的判别网络D。
二、GAN的思想
GANs是一类生成模型,它涉及两个“对手”,一个称为Generator(生成者),一个称为Discriminator(判别者)。
例子:现实生活中,往往会出现很多的仿制品。例如一些假鞋制造厂,
1、刚开始,假鞋制造厂做的假鞋和真鞋有很大的区别,特别是颜色和造型方面很不同,使得普通消费者很容易通过网络对比图片辨别出假鞋。
2、后来制假人员将假鞋的颜色和造型制得和真鞋一样,普通消费者已经不能通过对比图片便被鞋得真假了。
3、这时,更精明的消费者会考虑鞋的做工,比如鞋面上的车线或鞋底是否有溢出的胶等。
4、制假者于是进一步改进工艺,使得假鞋做工达到和真鞋相当的水平。
5、更精明的消费者会利用鞋的质感来鉴别。
6、为了对抗这样的消费者,制假人员进一步研发出质感相近但是档次却差的材料,制作出质感类似的假鞋。这样,很多消费者没有办法分辨出鞋的真假。
7、后来,甚至有人通过注意到真鞋的鞋标中文字的对齐和鞋盒里面盖的钢印与假鞋的不同。制假人员闻之,又改进了鞋标和鞋盒。
综上,生成对抗是一种博弈,随着博弈的进行,制造方制假水平会越来越高,假货会越来越像真货。理想的情况下,博弈的结果会得到一个可以“以假乱真”的生成模型。
三、组成
1)生成网络
生成网络生成假数据,并且使假数据尽量显得真实,从而使鉴别网络误认为生成的数据是真数据。生成网络的输入是随机数,之所以需要有随机输入,是因为生成网络需要生成不同的假数据,如果一直不是随机数,那么就一直生成相同的假数据,不符合应用需求。生成网络g可以将这条张量Z映射为一条数据张量X=g(Z)。这个张量X就是伪造数据(生成数据)。
2)鉴别网络
鉴别网络对生成网络生成的数据进行判定。真实数据和生成数据都可以输入到鉴别网络中,鉴别网络试图区别生成数据的真假。鉴别网络d对一条输入张量X进行判决,得到结果d(X)。在这边,鉴别网络只是用来帮助训练生成网络的,因此,鉴别网络只在训练过程中使用,不在实际应用中使用。定义鉴别标签y为:
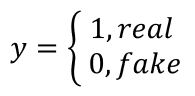
并将鉴别结果d(X)当作鉴别网络得到的对数赔率(d(x)越大,表示越可能是真数据,d(X)越小,表示越可能是假数据)。无论是真数据还是假数据,都可以通过最小化交叉熵损失来训练网络。
- 鉴别网络的优化:
最小化 l o s s ( d ( X ) , 1 ) loss(d(X),1) loss(d(X),1),最小化 l o s s ( d ( g ( Z ) ) , 0 ) loss(d(g(Z)),0) loss(d(g(Z)),0)
- 生成网络的优化:
最大化 l o s s ( d ( g ( Z ) ) , 0 ) loss(d(g(Z)),0) loss(d(g(Z)),0)
可以看出,两个神经网络对于 l o s s ( d ( g ( z ) ) , 0 ) loss(d(g(z)),0) loss(d(g(z)),0)的值有着截然相反的训练目标。所以我们可以得出:
max g min d l o s s ( d ( g ( Z ) ) , 0 ) \max_g\min_d loss(d(g(Z)),0) gmaxdminloss(d(g(Z)),0)
四、GAN的优缺点
1)GAN的优点
-
相比其他的生成模型,只用到了反向传播。
-
相比其他生成模型,GAN可以产生更加清晰、真实的样本。Auto-encoder和VAE分别如下图:
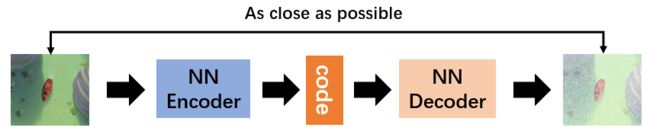
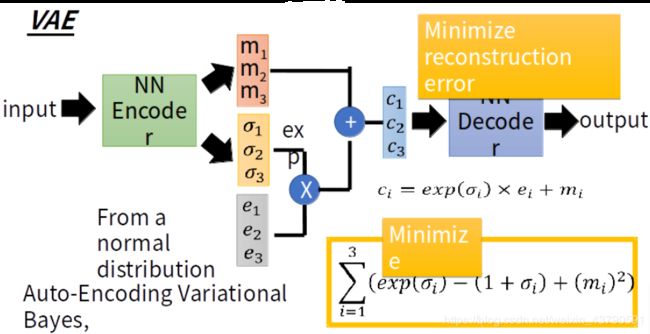
训练一个encoder,把input转换成code(编码过程),然后训练一个decoder,把code转换成一个image,然后计算image和input之间的MSE,训练完这个模型之后,取出后半部分NNDecoder,输入一个随机的code,就可以生成一张image。这个VAE采用的是MSE损失函数,即每一个像素上的均方差。但是在这边loss小真的表示相似吗?它计算是像素点之间的误差,不一定像素点之间的误差小,生成图像就越接近真实图像,像下面这张图片: 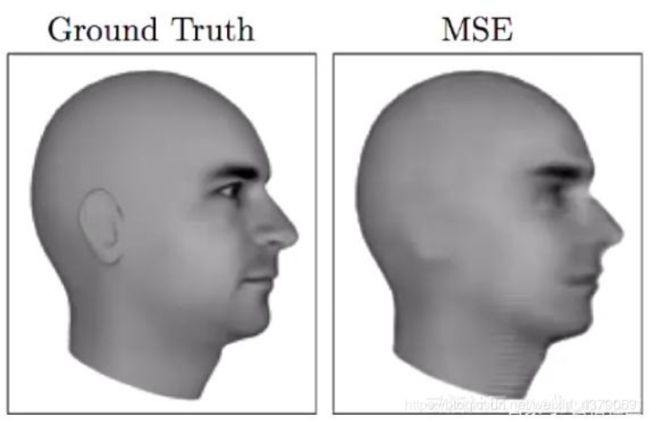
更多的GAN与VAE的对比,详情请看:https://blog.csdn.net/StreamRock/article/details/81415294
- GAN应用到一些场景上,比如图片风格迁移,超分辨率,图像补全,去噪,避免的损失函数的困难,不管三七二十一,只要有一个基准,直接上判别器,剩下的就交给对抗训练。
2)GAN的缺点
-
训练GAN需要达到纳什均衡(G和D构成一个动态的“博弈过程”,最终的平衡点即纳什均衡点),有时候可以用梯度下降法做到,有时候又做不到,我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的。‘
-
GAN不适合处理离散形式的数据,比如文本。
-
GAN存在训练不稳定、梯度消失、模式崩溃的问题(目前以解决)。
模式崩溃(model collapse)原因可以解释如下:GAN采用的是对抗训练的方式,G的梯度更新来自D,所以G生成的好不好,得看D怎么说。具体就是G生成一个样本,交给D去评判,D会输出生成的假样本是真样本的概率(0-1),相当于告诉G生成的样本有多大的真实性,G就会根据这个反馈不断改善自己,提高D输出的概率值。但是如果某一次G生成的样本可能并不是很真实,但是D给出了正确的评价,或者是G生成的结果中一些特征得到了D的认可,这时候G就会认为我输出的正确的,那么接下来我就这样输出肯定D还会给出比较高的评价,实际上G生成的并不怎么样,但是他们两个就这样自我欺骗下去了,导致最终生成结果缺失一些信息,特征不全。
关于梯度消失的问题可以参考郑华滨的wassertein GAN,里面给出了详细解释。
为什么GAN中不常用SGD?
1、SGD容易震荡,容易使GAN训练不稳定。
2、GAN的目的是在高维非凸的参数空间寻找的纳什均衡点,GAN的纳什均衡点是一个鞍点,但是SGD只会找到局部最小值。
为什么GAN不适合处理文本数据?
1、文本数据相比较图片来说是离散的,因为对于文本来说,通常需要将一个词映射为一个高维的向量,最终预测的输出是一个one-hot向量,假设softmax的输出是(0.2,0.3,0.1,0.2,0.15,0.05)那么变成one-hot是(0,1,0,0,0,0),如果softmax输出是(0.2,0.25,0.2,0.1,0.15,0.1),one-hot仍然是(0,1,0,0,0,0),所以对于生成器来说,G输出了不同的结果但是D给出了相同的判别结果,并不能将梯度更新信息很好地传递到G中去,所以D最终输出的判别没有意义。
2、GAN的损失函数是JS散度,JS散度不适合衡量不想交分布之间的距离。(其他GAN网络中可能使用的是别的损失函数。)
五、GAN的广泛应用
1、GAN本身是一种生成式模型,所以在数据生成上用的是最普遍的,最常见的是图片生成,常用的有DCGAN WGAN,BEGAN,个人感觉在BEGAN的效果最好而且最简单。
2、GAN本身也是一种无监督学习的典范,因此它在无监督学习,半监督学习领域都有广泛的应用,比较好的论文有Improved Techniques for Training GANs、Bayesian GAN(最新)、Good Semi-supervised Learning。
3、不仅在生成领域,GAN在分类领域也占有一席之地,简单来说,就是替换判别器为一个分类器,做多分类任务,而生成器仍然做生成任务,辅助分类器训练。
4、GAN可以和强化学习结合,目前一个比较好的例子就是seq-GAN
5、目前比较有意思的应用就是GAN用在图像风格迁移,图像降噪修复,图像超分辨率,都有比较好的结果。
6、目前也有研究者将GAN用在对抗性攻击上,具体就是训练GAN生成对抗文本,有针对或者无针对的欺骗分类器或者检测系统等等,但是目前没有见到很典范的文章。
六、pytorch搭建生成对抗网络
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
from torchvision.utils import save_image
dataset = CIFAR10(root='./data', download=True,
transform=transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)#喂入大小是把原来数据集中的多少图片组合成一张图片
batch_size=64
for batch_idx, data in enumerate(dataloader):
if batch_idx==len(dataloader)-1:
continue
real_images, _ = data
print ('#{} has {} images.'.format(batch_idx, batch_size))
if batch_idx % 100 == 0:
path = './data/CIFAR10_shuffled_batch{:03d}.png'.format(batch_idx)
save_image(real_images, path, normalize=True)
"搭建生成网络和鉴别网络"
"隐藏的卷积层(即除了最后的输出卷积层外)的输出都需要经过规范化操作"
import torch.nn as nn
# 搭建生成网络
latent_size = 64 # 潜在大小
n_channel = 3 # 输出通道数
n_g_feature = 64 # 生成网络隐藏层大小
"生成网络采用了四层转置卷积操作"
gnet = nn.Sequential(
# 输入大小 = (64, 1, 1)
#有点像互相关的反操作,(x-4)/1=1-->x=4
nn.ConvTranspose2d(latent_size, 4 * n_g_feature, kernel_size = 4,
bias = False),
nn.BatchNorm2d(4 * n_g_feature),
nn.ReLU(),
# 大小 = (256, 4, 4)
#{x+2(填充)-4(核尺寸)+2(步长)}/2=4-->x=8
nn.ConvTranspose2d(4 * n_g_feature, 2 * n_g_feature, kernel_size = 4,
stride = 2, padding = 1, bias = False),
nn.BatchNorm2d(2 * n_g_feature),
nn.ReLU(),
# 大小 = (128, 8, 8)
nn.ConvTranspose2d(2 * n_g_feature, n_g_feature, kernel_size=4,
stride = 2, padding = 1, bias = False),
nn.BatchNorm2d(n_g_feature),
nn.ReLU(),
# 大小 = (64, 16, 16)
nn.ConvTranspose2d(n_g_feature, n_channel, kernel_size = 4,
stride = 2, padding = 1),
nn.Sigmoid(),
# 图片大小 = (3, 32, 32)
)
print (gnet)
# 搭建鉴别网络
n_d_feature = 64 # 鉴别网络隐藏层大小
"鉴别网络采用了4层互相关操作"
dnet = nn.Sequential(
# 图片大小 = (3, 32, 32)
nn.Conv2d(n_channel, n_d_feature, kernel_size=4,
stride = 2, padding = 1),
nn.LeakyReLU(0.2),
# 大小 = (64, 16, 16)
nn.Conv2d(n_d_feature, 2 * n_d_feature, kernel_size=4,
stride = 2, padding = 1, bias = False),
nn.BatchNorm2d(2 * n_d_feature),
nn.LeakyReLU(0.2),
# 大小 = (128, 8, 8)
nn.Conv2d(2 * n_d_feature, 4 * n_d_feature, kernel_size=4,
stride = 2, padding = 1, bias = False),
nn.BatchNorm2d(4 * n_d_feature),
nn.LeakyReLU(0.2),
# 大小 = (256, 4, 4)
nn.Conv2d(4 * n_d_feature, 1, kernel_size=4),
# 对数赔率张量大小 = (1, 1, 1)
)
print(dnet)
"初始化权重值"
import torch.nn.init as init
def weights_init(m): # 用于初始化权重值的函数
if type(m) in [nn.ConvTranspose2d, nn.Conv2d]:
init.xavier_normal_(m.weight)
elif type(m) == nn.BatchNorm2d:
init.normal_(m.weight, 1.0, 0.02)
init.constant_(m.bias, 0)
#调用apply()函数,torch.nn.Module类实例会递归地让自己成为weights_init()里面函数的m
gnet.apply(weights_init)
dnet.apply(weights_init)"训练生成网络和鉴别网络并输出图片"
import torch
import torch.optim
# 损失
criterion = nn.BCEWithLogitsLoss()
# 优化器
#Adam优化器的默认学习率n=0.01,过高,应减小为0.002,动量参数默认0.9,会造成震荡,减小为0.5
goptimizer = torch.optim.Adam(gnet.parameters(),
lr=0.0002, betas=(0.5, 0.999))
doptimizer = torch.optim.Adam(dnet.parameters(),
lr=0.0002, betas=(0.5, 0.999))
# 用于测试的固定噪声,用来查看相同的潜在张量在训练过程中生成图片的变换
batch_size = 64
fixed_noises = torch.randn(batch_size, latent_size, 1, 1)
# 训练过程
epoch_num = 10
for epoch in range(epoch_num):
for batch_idx, data in enumerate(dataloader):
if batch_idx==len(dataloader)-1: #剔除最后一张是(16,3,32,32)
continue
# 载入本批次数据
real_images, _ = data#real_images(64,3,32,32)
# 训练鉴别网络
labels = torch.ones(batch_size) # 真实数据对应标签为1(64,)
preds = dnet(real_images) # 对真实数据进行判别(64,1,1,1)
outputs = preds.reshape(-1)#(64,)
dloss_real = criterion(outputs, labels) # 真实数据的鉴别器损失
dmean_real = outputs.sigmoid().mean() # 计算鉴别器将多少比例的真数据判定为真,仅用于输出显示
noises = torch.randn(batch_size, latent_size, 1, 1) # 潜在噪声(64,64,1,1)
fake_images = gnet(noises) # 生成假数据(64,3,32,32)
labels = torch.zeros(batch_size) # 假数据对应标签为0
fake = fake_images.detach()# 使得梯度的计算不回溯到生成网络,可用于加快训练速度.删去此步结果不变
preds = dnet(fake) # 对假数据进行鉴别
outputs = preds.view(-1)
dloss_fake = criterion(outputs, labels) # 假数据的鉴别器损失
dmean_fake = outputs.sigmoid().mean()
# 计算鉴别器将多少比例的假数据判定为真,仅用于输出显示
dloss = dloss_real + dloss_fake # 总的鉴别器损失
dnet.zero_grad()
dloss.backward()
doptimizer.step()
# 训练生成网络
labels = torch.ones(batch_size)
# 生成网络希望所有生成的数据都被认为是真数据
preds = dnet(fake_images) # 把假数据通过鉴别网络
outputs = preds.view(-1)
gloss = criterion(outputs, labels) # 真数据看到的损失
gmean_fake = outputs.sigmoid().mean()
# 计算鉴别器将多少比例的假数据判定为真,仅用于输出显示
gnet.zero_grad()
gloss.backward()
goptimizer.step()
# 输出本步训练结果
if batch_idx % 100 == 0:
print('[{}/{}]'.format(epoch, epoch_num) +
'[{}/{}]'.format(batch_idx, len(dataloader)) +
'鉴别网络损失:{:g} 生成网络损失:{:g}'.format(dloss, gloss) +
'真数据判真比例:{:g} 假数据判真比例:{:g}/{:g}'.format(
dmean_real, dmean_fake, gmean_fake))
fake = gnet(fixed_noises) # 由固定潜在张量生成假数据
save_image(fake, # 保存假数据
'./data/images_epoch{:02d}_batch{:03d}.png'.format(
epoch, batch_idx))