Python爬虫与信息提取(七)爬虫实例:爬取股票信息
学习了正则表达式后,就学习并制作了爬取股票信息的爬虫实例。
1.出现的错误
由于已经有了之前的经验和引入了正则表达式的使用,写这个爬虫的过程中出错就比较少了,然后代码也比较简短了
一开始出现了find函数返回NoneType的情况:
https://blog.csdn.net/qq_36525166/article/details/81258168
看了这篇文章,解决了问题。
后来又经过了一段时间的调试查漏补缺,就可以正常运行了。
2.全部代码:
import requests
import traceback
import bs4
import re
#获取HTML页面内容
#默认的编码为utf-8这样可以提高速度
def getHTMLText(url, encode='utf-8'):
try:
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url, headers=kv, timeout = 30)
r.encoding = encode
return r.text
except:
print("getHTMLTextError!")
return ""
#获取股票代码列表
def getStockList(ls, StockUrl):
html = getHTMLText(StockUrl, 'GB2312')
soup = bs4.BeautifulSoup(html, "html.parser")
#使用find_all找到所有的a标签
for i in soup.find_all('a'):
try:
#定义href属性是所有的a标签中的带有href的内容(字符串)
href = i.attrs['href']
#使用正则表达式库来找到所有的href的字符串内容中的‘股票代码部分’
ls.append(re.findall(r'[s][zh]\d{6}', href)[0])
except:
continue
#获取股票信息
def getStockInfo(ls, StockUrl, fpath):
#使用for来遍历股票代码列表中的股票
count = 0
for stock in ls:
url = StockUrl + stock + ".html"
html = getHTMLText(url)
try:
#如果页面信息是空的,就跳过
if html=="":
continue
#构建一个新字典来存储单个股票的各种信息
info = {}
soup = bs4.BeautifulSoup(html, "html.parser")
stockinfo = soup.find('div', attrs={"class":"stock-bets"})
if isinstance(stockinfo, bs4.element.Tag):
#获取股票的名称
stockname = stockinfo.find_all(attrs={"class":"bets-name"})[0]
#更新字典中的信息
info.update({"股票名称":stockname.text})
#标签存储的是Key, 标签存储的是Value
Keylist = stockinfo.find_all('dt')
Valuelist = stockinfo.find_all('dd')
#使用for循环对键值对和键值进行匹配,并且存储
for i in range(len(Keylist)):
key = Keylist[i].text
value = Valuelist[i].text
#向字典中新增内容
info[key]=value
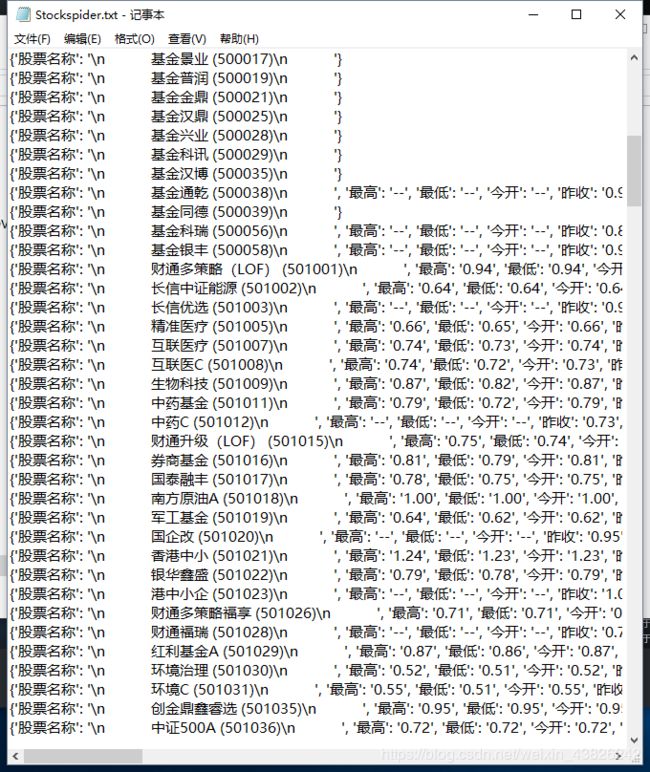
#将字典中的相关信息全部写入到文件中
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(info)+'\n')
#可以增加进度条
count = count + 1
print("\r进度:{:.2f}%".format(count*100/len(ls)), end='')
except:
count = count + 1
print("\r进度:{:.2f}%".format(count*100/len(ls)), end='')
traceback.print_exc()
continue
#运行主函数
def main():
stock_list_url = 'http://quote.eastmoney.com/stocklist.html'
stock_info_url = 'https://gupiao.baidu.com/stock/'
output_file = 'D:\\Stockspider.txt'
stocklist = []
getStockList(stocklist, stock_list_url)
getStockInfo(stocklist, stock_info_url, output_file)
print("Complete Successfully!")
main() 3.最终效果
等待爬取的过程真的是一个非常漫长的过程。。。可以看到requests库的效率在应对大量数据的时候就显得力不从心了,如果使用具有高并发特点的scrapy爬虫框架速度就比较快了