sparkSQL---不同数据源的读写操作
sparkSQl 可以读取不同数据源的数据,比如jdbc,json,csv,parquet
执行读操作就用sparkSession.read.文件类型,执行写操作就用SparkSession.write.文件类型
首先创建一个SparkSession:
val spark = SparkSession.builder().appName("JdbcDataSource")
.master("local[4]")
.getOrCreate()
jdbc
例如,读取MySQL中的数据:
//load这个函数是并没有真正读取MySQL中的数据,而是建立了一个连接,记录了这个表头(Schema)的信息
val logs: DataFrame = spark.read.format("jdbc").options(
Map("url" -> "jdbc:mysql://localhost:3306/bigdata",
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "logs",
"user" -> "root",
"password" -> "")
).load()
保存数据到MySQL中:
//将结果写入到数据库中
val props = new Properties()
props.put("user","root")
props.put("password","")
//mode是模式
// ignore表示不做任何改变,直接写,如果要写入的表已经存在,则不追加也不覆盖
result.write.mode("ignore").jdbc("jdbc:mysql://localhost:3306/bigdata","logs1",props)
json
读取json文件:
//读取json文件(读取的数据格式直接就是DataFrame,因为json文件中可以保存属性名和属性值)
val logs: DataFrame = spark.read.json("/home/hadoop/app/json")
DataFrame保存到json:
//DataFrame保存成json(可以保存更多的信息,属性和属性名(表头))
result.write.json("/home/hadoop/app/json")
csv
读取csv文件:
//读取csv文件(根据字段分割就知道一行有多少列数据,然后会给每一列取一个名字)
val logs: DataFrame = spark.read.csv("/home/hadoop/app/csv")
//自己定义每一列的名称
val csv: DataFrame = logs.toDF("id","name","age")
保存数据为csv文件:
//DataFrame保存成csv(保存好的数据用逗号隔开,没有表头信息)
result.write.csv("/home/hadoop/app/csv")
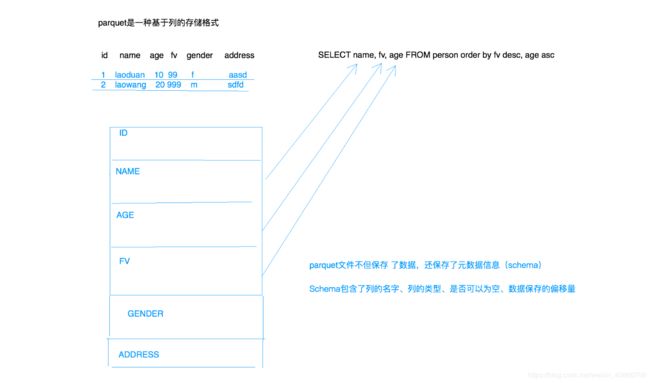
parquet
在大数据领域中,经常会用到parquet,因为这个文件格式更加的智能。他是列式存储的,使用起来更加的高效。
读取parquet文件:
//读取parquet文件(还可以指定HDFS目录),可以智能的知道每一列数据的类型
val parquetLines: DataFrame = spark.read.parquet("/home/hadoop/app/parquet")
//或者使用另一种方式读取
val parquetLines: DataFrame = spark.read.format("parquet").load("/home/hadoop/app/parquet")
将数据保存成parquet:
//DataFrame保存成parquet(智能类型的数据源,列式存储),既保存数据,又保存了Schema信息
result.write.parquet("/home/hadoop/app/parquet")
parquet文件格式为:
DataFrame的过滤操作
1.使用DataFrame上的API:
//过滤(使用DataFrame上的API)
val filtered: Dataset[Row] = logs.filter(f => {
f.getAs[Int](2) <= 13
})
2.使用lambda表达式:
//导入隐式转换
import spark.implicits._
//过滤(使用lambda表达式)
val filtered: Dataset[Row] = logs.filter($"age" <= 13)
filtered.show()
3.操作一列上的数据:
//操作一列上的数据
import spark.implicits._
val result: DataFrame = logs.select($"id",$"name",$"age" * 10 as "new_age")