《Python 自然语言处理》学习笔记--第一章:语言处理与python
《Python 自然语言处理》学习笔记--第一章:语言处理与python
- NLTK入门与函数
- 安装
- 基础函数
NLTK入门与函数
本文将记录书中所述函数,并对报错处做出修正。
安装
从NLTK库中下载文章资料并查看。
>>> import nltk
>>> nltk.download()

>>> from nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
>>> text1
基础函数
词语索引
>>> text1.concordance("monstrous")
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
查看那些词出现在类似的上下文
>>> text1.similar("monstrous")
true contemptible christian abundant few part mean careful puzzled
mystifying passing curious loving wise doleful gamesome singular
delightfully perilous fearless
研究两个及以上的词共同的上下文
>>> text2.common_contexts(["monstrous","very"])
a_pretty am_glad a_lucky is_pretty be_glad
词汇分布离散图
>>> text4.dispersion_plot(["citizens","democracy","freedom","duties","America"])

产生随机文本(报错)
>>> text3.generate()
Traceback (most recent call last):
File "", line 1, in
TypeError: generate() missing 1 required positional argument: 'words'
报错原因:
探索一下后发现问题所在:
打开nltk文件夹中的text.py发现了,原来新版本的NLTK没有了“text1.generate()”这个功能作者已经把demo里的text.generate()注释掉了,但是我下载了nltk2.0.1版本的安装包,解压后打开nltk文件夹下的text.py,发现老版本中有这个功能(《python自然语言处理时》书中用的是NLTK2.0版本),所以要是想用这个功能的同学请安装nltk2.0.1版本,nltk3.x的版本是没了
原文:https://blog.csdn.net/huludan/article/details/47375357
计数,文本词汇表与标识符
>>> len(text3)
44764
>>> sorted(set(text3))
['!', "'", '(', ')', ',', ',)', '.', '.)', ':', ';', ';)', '?', '?)', 'A', 'Abel', 'Abelmizraim', 'Abidah', 'Abide', 'Abimael', 'Abimelech', 'Abr', 'Abrah', 'Abraham', 'Abram', 'Accad', 'Achbor', 'Adah', 'Adam', 'Adbeel', 'Admah', 'Adullamite', 'After', 'Aholibamah', ...]
>>> len(set(text3))
2789
词汇丰富度
>>> from __future__ import division
>>> len(text3)/len(set(text3))
16.050197203298673
>>> text3.count("smote")
5
>>> 100*text4.count('a')/len(text4)
1.457973123627309
链表处理
>>> ['Monty','Python']+['and','the','Holy','Grail']
['Monty', 'Python', 'and', 'the', 'Holy', 'Grail']
>>> sent1 = ['Call','me','Ishmael','.']
>>> sent1.append("Some")
>>> sent1
['Call', 'me', 'Ishmael', '.', 'Some']
>>> text4[1600:1625]
['America', '.', 'Previous', 'to', 'the', 'execution', 'of', 'any', 'official', 'act', 'of', 'the', 'President', 'the', 'Constitution', 'requires', 'an', 'oath', 'of', 'office', '.', 'This', 'oath', 'I', 'am']
>>> name='Monty'
>>> name[0]
'M'
>>> name*2
'MontyMonty'
>>> name+'!'
'Monty!'
>>> ''.join(['Monty','Python'])
'MontyPython'
'Monty Python'.split()
['Monty', 'Python']
频率分布(报错)
>>> fdist1=FreqDist(text1)
>>> fdist1
FreqDist({',': 18713, 'the': 13721, '.': 6862, 'of': 6536, 'and': 6024, 'a': 4569, 'to': 4542, ';': 4072, 'in': 3916, 'that': 2982, ...})
>>> vocabulary1=fdist1.keys()
>>> vocabulary1[:50]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'dict_keys' object is not subscriptable
修改方式
>>> list(vocabulary1)[:50]
['[', 'Moby', 'Dick', 'by', 'Herman', 'Melville', '1851', ']', 'ETYMOLOGY', '.', '(', 'Supplied', 'a', 'Late', 'Consumptive', 'Usher', 'to', 'Grammar', 'School', ')', 'The', 'pale', '--', 'threadbare', 'in', 'coat', ',', 'heart', 'body', 'and', 'brain', ';', 'I', 'see', 'him', 'now', 'He', 'was', 'ever', 'dusting', 'his', 'old', 'lexicons', 'grammars', 'with', 'queer', 'handkerchief', 'mockingly', 'embellished', 'all']
>>> fdist1['whale']
906
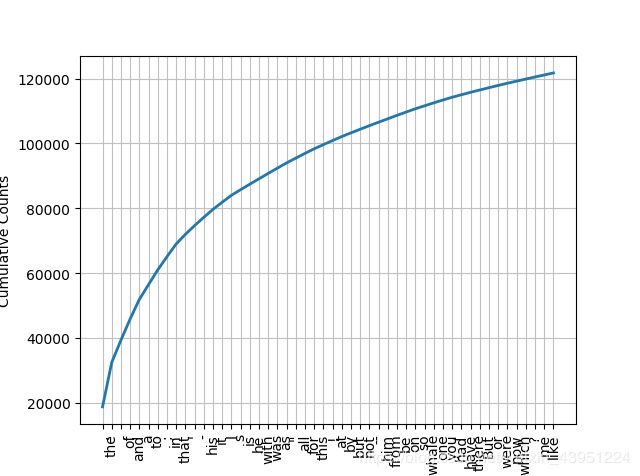
词汇累计频率图
>>> fdist1.plot(50,cumulative=True)
细粒度的选择词
>>> V=set(text1)
>>> long_words=[w for w in V if len(w)>15]
>>> sorted(long_words)
['CIRCUMNAVIGATION', 'Physiognomically', 'apprehensiveness', 'cannibalistically', 'characteristically', 'circumnavigating', 'circumnavigation', 'circumnavigations', 'comprehensiveness', 'hermaphroditical', 'indiscriminately', 'indispensableness', 'irresistibleness', 'physiognomically', 'preternaturalness', 'responsibilities', 'simultaneousness', 'subterraneousness', 'supernaturalness', 'superstitiousness', 'uncomfortableness', 'uncompromisedness', 'undiscriminating', 'uninterpenetratingly']
>>> fdist5 = FreqDist(text5)
>>> sorted([w for w in set(text5) if len(w)>7 and fdist5[w]>7])
['#14-19teens', '#talkcity_adults', '((((((((((', '........', 'Question', 'actually', 'anything', 'computer', 'cute.-ass', 'everyone', 'football', 'innocent', 'listening', 'remember', 'seriously', 'something', 'together', 'tomorrow', 'watching']
词语搭配和双连词(报错)
>>> bigrams(['more','is','said','than','done'])
修改方式
>>> list(bigrams(['more','is','said','than','done']))
[('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
比基于单个词的频率预期得到的更频繁出现的双连词(报错)
>>> text4.collocations()
Traceback (most recent call last):
File "", line 1, in
File "D:\anaconda\lib\site-packages\nltk\text.py", line 440, in collocations
print(tokenwrap(self.collocation_list(), separator="; "))
File "D:\anaconda\lib\site-packages\nltk\text.py", line 440, in
print(tokenwrap(self.collocation_list(), separator="; "))
ValueError: too many values to unpack (expected 2)
原因与修改方式
I was going through chapter 1 of the book and the collocations function returns an error. It seems like line 440 in text.py is redundant, since the collocation_list function has been introduced. I fixed the issue by rewriting the current line 440 and line 441 in text.py.
old code:collocation_strings = [w1 + ’ ’ + w2 for w1, w2 in self.collocation_list(num, window_size)]*
print(tokenwrap(collocation_strings, separator="; “))
new code:
print(tokenwrap(self.collocation_list(), separator=”; "))
就是找出anaconda中nltk中的text.py的collocation函数的这两行修改一哈就行。
原文:https://github.com/nltk/nltk/issues/2299
>>> text4.collocations()
United States; fellow citizens; four years; years ago; Federal
Government; General Government; American people; Vice President; God
bless; Chief Justice; Old World; Almighty God; Fellow citizens; Chief
Magistrate; every citizen; one another; fellow Americans; Indian
tribes; public debt; foreign nations
计数其他东西
#创建包含给定样本的频率分布
>>> fdist = FreqDist([len(w) for w in text1])
>>> fdist
FreqDist({3: 50223, 1: 47933, 4: 42345, 2: 38513, 5: 26597, 6: 17111, 7: 14399, 8: 9966, 9: 6428, 10: 3528, ...})
#以频率递减的顺序排序的样本链表
>>> fdist.keys()
dict_keys([1, 4, 2, 6, 8, 9, 11, 5, 7, 3, 10, 12, 13, 14, 16, 15, 17, 18, 20])
>>> fdist.items()
dict_items([(1, 47933), (4, 42345), (2, 38513), (6, 17111), (8, 9966), (9, 6428), (11, 1873), (5, 26597), (7, 14399), (3, 50223), (10, 3528), (12, 1053), (13, 567), (14, 177), (16, 22), (15, 70), (17, 12), (18, 1), (20, 1)])
#数值最大的样本
>>> fdist.max()
3
#给定样本的频率
>>> fdist.freq(3)
0.19255882431878046
#样本总数
>>> fdist.N()
260819
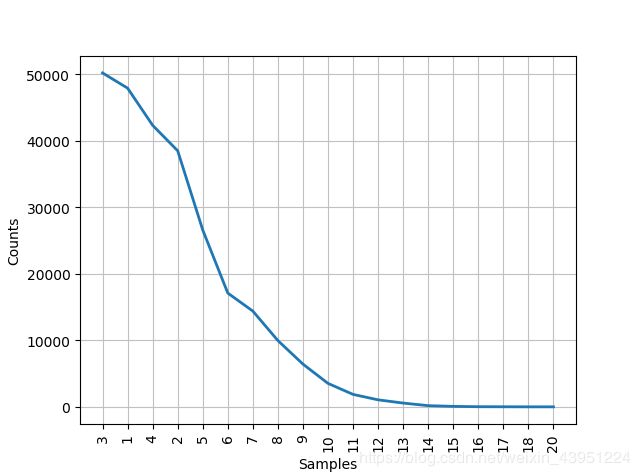
#绘制频率分布表
>>> fdist.tabulate()
3 1 4 2 5 6 7 8 9 10 11 12 13 14 15 16 17 18 20
50223 47933 42345 38513 26597 17111 14399 9966 6428 3528 1873 1053 567 177 70 22 12 1 1
#绘制频率分布图
>>> fdist.plot()
#测试s是否以t开头
s.startswith(t)
#测试s是否以t结尾
s.endswith(t)
#是否都是小写字母
s.islower()
#是否都是大写字母
s.isupper()
#是否都是字母
s.isalpha()
#是否都是字母或数字
s.isalnum()
#是否都是数字
s.isdigit()
#是否首字母大写
s.istitle()
>>> sorted([w for w in set(text1) if w.endswith('ableness')])
['comfortableness', 'honourableness', 'immutableness', 'indispensableness', 'indomitableness', 'intolerableness', 'palpableness', 'reasonableness', 'uncomfortableness']
>>> sorted([term for term in set(text4) if 'gnt' in term])
['Sovereignty', 'sovereignties', 'sovereignty']
>>> [len(w) for w in text1]
[1, 4, 4, 2, 6, 8, 4, 1, 9, 1, 1, 8, 2, 1, 4, 11, 5, 2, 1, 7, 6, 1, 3, 4, 5, 2, ...]
>>> [w.upper() for w in text1]
['[', 'MOBY', 'DICK', 'BY', 'HERMAN', 'MELVILLE', '1851', ']', 'ETYMOLOGY', '.', ...]
词意消歧:我们需要算出特定上下文中的词被赋予的是哪个意思。
指代消解(anaphora resolution):确定代词或名词短语指的是什么,即谁对谁做了什么。
语义角色标注(semantic role labeling):确定名词短语如何与动词相关联。
自动问答:一台机器能够回答用户关于特定文本集的问题。
机器翻译(MT):从根本上提供高品质的符合语言习惯的任意两种语言之间的翻译。
文本对齐:给出两种语言的文档或者一个双语词典,就可以自动配对组成句子。
文本含义识别(Recognizing Textual Entailment RET):通过简短的文字使用自动方法做出正确决策是困难的。