【简单理解】XLNet
【简单理解】XLNet
1. 简单介绍XLNet
XLNet是一个通过排列语言模型实现双向上下文信息的自回归模型。它通过随机排列输入序列而预测某个位置可能出现的词,进而训练出具有上下文的语境化词向量。
XLNet是一个类似BERT的模型,但是它采用了通用的自回归预训练方法(AR模型),而基于DAE的Bert模型采用的则是降噪自动编码方法(AE模型),bert和AR模型的区别主要是在以下三方面:
- 独立假设:bert中一个序列中会被mask掉不超过15%的单词,但是在预训练时的目标函数是基于mask值彼此独立、互不干扰的假设下进行计算的,而AR模型中不需要设置mask值,预训练时的目标函数也不必设立独立假设。同时,mask的设置会导致预训练-微调的数据上的不统一,这也是Bert的一个缺陷。
- 输入噪声:Bert在预训练时对输入序列进行随机mask,这是一种输入噪声设定,但是在下游任务进行微调时却并没有对输入序列设置输入噪声,即随机mask,这引起了预训练-微调间的差异。与之相反,AR模型不设置输入噪声,因而不会有这种问题。
- 上下文依赖:AR模型只考虑前向信息或者后向信息,而bert要考虑双向信息,结果就是,bert的目标函数允许模型被训练为能够更好地抓取双向信息。
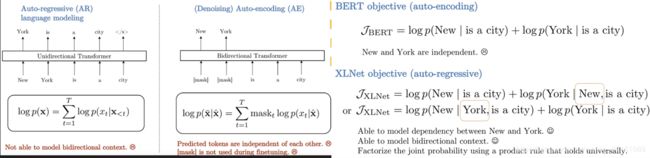
2. XLNet两个创新
2.1 permutation language model: 基于排列的语言建模方法
- 通过随机排列输入序列而预测某个位置可能出现的词:因为某位置只能attention该位置前面的词,但随机排列就可attention序列中的所有单词,进而达到双向上下文的依赖建模的目的。随机排列时带有输入时的位置信息,打乱顺序不会影响建模效果。
- 解决bert主要的两个问题。bert中的独立假设无法考虑New York is a city中New or York的关联,以及自编码引入mask训练和测试不一致
2.2 two-steam attention:
解决预测时想看见自己和不想看见自己的矛盾 两个stream共享一套参数
3.AR与AE的原理
3.1 AR原理
AR是自回归的模型(AutoRegressive LM),是一种使用上下文词来预测下一个词的模型。但是在这里,上下文单词被限制在两个方向,前向或后向。
AR的代表有:
- 传统的语言模型,根据上文预测下一个词。
- ELMo扩展了语言模型,增加了双向词的预测,上文预测下一个词和下文预测上一个词,但是本质上还是AR的原理。
- 再到GPT是把AR发挥到极致的做法,在AR的基础上,提升预料的质量,加大训练的资源,最终训练出相当不错的效果。
AR的优点和缺点:
- 缺点是只能利用上文或者下文的信息,不能同时利用上文和下文的信息。当然,貌似ELMO这种双向都做,然后拼接看上去能够解决这个问题,因为融合模式过于简单,所以效果其实并不是太好。
- 优点是符合下游NLP任务语言环境,比如生成类NLP任务,比如文本摘要,机器翻译等,在实际生成内容的时候,就是从左向右的,自回归语言模型天然匹配这个过程。而Bert这种DAE模式,在生成类NLP任务中,就面临训练过程和应用过程不一致的问题,导致生成类的NLP任务到目前为止都做不太好。
3.2 AE原理
AE是自编码语言模型(AutoEncoder LM),它能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文。
- Bert通过在输入X中随机Mask掉一部分单词,然后预训练过程的主要任务之一是根据上下文单词来预测这些被Mask掉的单词,如果你对Denoising Autoencoder比较熟悉的话,会看出,这确实是典型的DAE的思路。那些被Mask掉的单词就是在输入侧加入的所谓噪音。类似Bert这种预训练模式,被称为DAE LM。
AE的优点和缺点:
- 优点是能比较自然地融入双向语言模型,同时看到被预测单词的上文和下文。
- 缺点是在训练的输入端引入[Mask]标记,导致预训练阶段和Fine-tuning阶段不一致的问题。
4. XLNet具体介绍
提出背景
- 传统的语言模型(自回归语言模型AR天然适合处理生成任务,但是无法对双向上下文进行表征;
- 而自编码语言模型(AE)虽然可以实现双向上下文进行表征,但是:
- BERT系列模型引入独立性假设,没有考虑预测[MASK]之间的相关性;
- MLM预训练目标的设置造成预训练过程和生成过程不一致;
- 预训练时的[MASK]噪声在finetune阶段不会出现,造成两阶段不匹配问题;
- XLNet提出了一种排列语言模型(PLM),它综合了自回归模型和自编码模型的优点,同时避免他们的缺点
XLNet(AR模型)总体思路
XLNet提出了一种让AR语言模型(单向的输入和预测模式)能够从双向上下文中学习的新方法。这也是XLNet的主要贡献。
XLNet仍然采用两阶段模型训练过程,第一阶段是语言模型预训练阶段,第二阶段是任务数据fine-tuning阶段。它主要改动了第一阶段,即不使用bert那种带mask符号的Denoising-autoencoder的模式,而是采用自回归语言模型。就是说,一个输入序列X依然是从左向右输入,在预测单词T时,既知道它的上文信息context_before,也知道它的下文信息contenx_after,但是,这里不采用bert使用mask符号的方式。于是在预训练阶段,这是一个标准的从左向右过程,在微调阶段也是如此,因此两个过程就统一起来,不会造成两阶段的数据不一致问题[3]。而这里具体的实现方法,就是论文提出的排列语言模型。
4.1训练目标:排列语言模型(Permutation Language Modeling)
PLM的中心思想就是重新排列组合输入序列X。具体的说,假设输入序列X = [x1,x2,x3,x4],我们想要预测x3,
1、使用AR模型的常规操作:按照AR模型自左向右的输入X,我们只能看到x3的上文context_before(即x1,x2),而不能看到x3的下文context_after(即x4)。
2、使用PLM的方法:我们需将待预测单词x3固定在它本来的位置上(即Position 3),然后将输入序列X中的元素进行随机排列组合(此例中共会产生24种组合方式),在这24种组合中,抽取一部分(如:x4,x2,x3,x1)作为模型的输入X,则待预测单词x3既能看到上文x1,x2,也能看到下文x4,达到了获取上下文信息的目的,但是在形式上依然是从左向右在预测后一个单词。具体如下图所示:
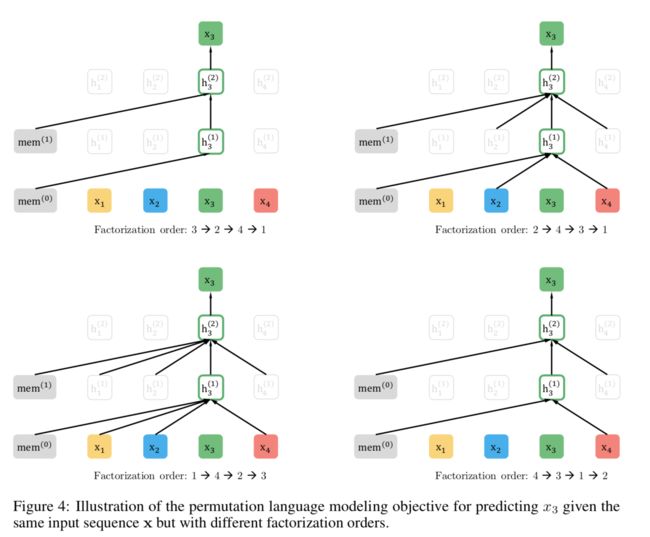
这里解释一下右上图,即Factorization order:2 -> 4 -> 3 -> 1这张图,可以看出在计算h3(1)时,它只获取了x2,x4和mem(0)的信息,即获取了x3的下文信息x4。
注1:由图中可以看出,它并没有更改输入顺序,输入顺序仍然为x1,x2,x3,x4,但是Transformer在获取输入信息时,它只获取了x4和x2,这是因为attention将x1 mask掉了,这一过程是在Transformer中实现的,具体描述在下一节中讲述。
PLM的优势如下:
1、保证预训练-微调两个阶段的一致性,规避了bert模型的劣势(预训练-微调数据不一致以及多个mask之间的独立假设)
2、获取双向信息(AR模型只能获取单向信息)
4.2双流自注意力(Architecture: Two-Stream Self-Attention for Target-Aware Representations )
双流主要是指内容流和查询流,具体介绍如下:
内容流(content stream):指标准的Transformer过程
查询流(query stream)[3]:只保留位置信息,忽略内容信息。具体的说,对于待预测单词x3来说,已知其上文信息x1,x2,因为x3是需要被预测的单词,因此在Transformer的输入端不能输入x3的单词内容,需要将其遮挡掉,bert采用的方法是将x3 mask掉,即使用[MASK]标记符号作为x3的输入内容,但是这引起了预训练-微调数据不一致问题,xlnet既想看不到x3单词的内容,又不想像bert一样引入新的问题,它采取的方式就是使用query流,直接忽略掉x3的单词内容,而只使用x3的位置信息,使用参数w来代表位置的embedding编码。具体的实现过程如下所述:
输入序列依然是x1,x2,x3,x4,但是在Transformer内部,则是针对内容流和查询流分别有遮掩矩阵。就本文例子来说,需要遮掩的是x3,则在下图c中,由于使用的新的排列组合是x3,x2,x4,x1,因此,Query steam对应的遮掩矩阵中第三行中是空,因为没有其他的单词需要被输入。
同理,对于Content stream来说,由于Transformer的输入顺序是x3,x2,x4,x1,因此对于第一行x1来说,它可以将所有的单词都读入,因此矩阵第一行中所有圆点都被标为红色(表示x1,x2,x3,x4的信息都获取);对于第二行x2来说,它只能获取x3的信息以及自己的信息,因此第二个和第三个圆点标为红色(表示x2,x3的信息都获取);对于第三行x3来说,因为它只能读取自己的信息,因此只有第三个圆点标为红色(表示x3的信息被获取);对于第四行x4来说,由于它能获取x2、x3以及自己的的信息,因此其第二、三、四个圆点被标为红色(表示x2,x3,x4的信息都获取)。
由于Content Stream 和 Query Stream的区别仅在于自己的信息是否能获取,而Query Stream不能获取自己的信息,因此Query Stream的遮掩矩阵中对角线的圆点都为白色,表示不能获取自己的内容信息。
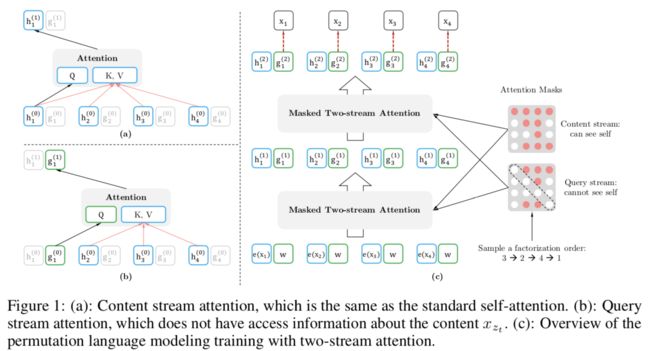
如上图所示,图a表示内容流(content stream),图b表示查询流(query stream),图c是使用了双流自注意力机制的排列语言模型。
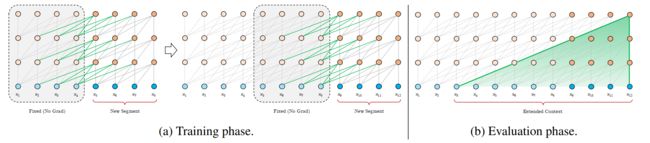
4.3Transformer-XL
Transformer-XL是 XLNet 的特征抽取结构,其相比于传统的Transformer能捕获更长距离的单词依赖关系。
原始的Transformer的主要缺点在于,其在语言建模中会受到固定长度上下文的限制,从而无法捕捉到更长远的信息。
Transformer-XL采用片段级递归机制(segment-level recurrence mechanism)和相对位置编码机制(relative positional encoding scheme)来对Transformer进行改进。
-
片段级递归机制:指的是当前时刻的隐藏信息在计算过程中,将通过循环递归的方式利用上一时刻较浅层的隐藏状态,这使得每次的计算将利用更大长度的上下文信息,大大增加了捕获长距离信息的能力。
-
相对位置编码:Transformer本身引入了三角函数向量作为位置编码向量。而Transformer-XL复用了上文的信息,这就导致位置编码出现重叠,因此采用了训练的方式得到相对位置编码向量。
5. XLNet与Bert比较
- Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词。
- XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。
- Bert隐藏了15%的词,用85%去预测15%的词。缺少了15%的词中的关联性。
- XLNet是通过整个上下文去预测某个词,这样的词的利用率更高,理论上效果更好。