mysql数据库事务隔离级别和锁机制
当一个数据在被并发事务执行时,可能会出现许多意外的问题,这些问题大致可以分为下面三类:
脏读(Drity Read):
事务A读取了事务B更新的数据,然后事务B回滚了,那么事务A读取到的数据就是脏数据。这种情况我们称之为:脏读。
不可重复读(Non-repeatable read):
事务A多次赢取同一数据,事务B在事务A多次读取的过程中,对数据进行了更新或则修改,导致事务A多次读取的同一数据结果不一致。这种情况我们称之为:不可重复读(修改或则删除)。
幻读(Phantom Read):
事务A先进行了一次范围修改,这时事务B在这个范围内新增了一条数据,这时事务A发现还有一条记录没有修改成功,就像发生了幻觉一样。这种情况我们称之为:幻读(新增)。
根据上面的3种问题,大家制定了一些标准,就是我们熟悉的:SQL92 ANSI/ISO标准
- Read Uncommitted(未提交读):未解决并发问题,事务未提交对于其他事务是可见的,会产生脏读。
- Read committed(提交读):事务只能看到自己所做的提交和修改,解决脏读问题。
- Repeatable Read(可重复读):在同一事务中多次读取同样的数据结果是一致的,解决不可重复读问题。这种隔离级别未定义解决幻读的问题。
- Serializable (串行化):最高隔离级别,通过强制事务的串行执行,解决所有问题
Innodb引擎对隔离级别的支持程度
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read Uncommitted(未提交读) | 可能 | 可能 | 可能 |
| Read committed(提交读) | 不可能 | 可能 | 可能 |
| Repeatable Read(可重复读) | 不可能 | 不可能 | 对Innodb不可能 |
| Serializable (串行化) | 不可能 | 不可能 | 不可能 |
Innodb默认为:Repeatable Read(可重复读)
Innodb的隔离级别到底是怎么实现的呢?
Innodb的隔离级别是用锁和MVCC来实现的。下面我们来看看Innodb的锁实现。MVCC会在后面单独弄一篇来说明。
锁是用于管理不同事务对共享资源的并发访问,一般分为:表锁和行锁。
表锁和行锁的区别:
锁定的粒度:表锁>行锁
加锁的效率:表锁>行锁
冲突的概率:表锁>行锁
并发的性能:表锁<行锁
Innodb引擎支持行锁和表锁
Innodb锁的类型:
- 共享锁(行锁):Shared Locks
- 排它锁(行锁):Exclusive Locks
- 意向共享锁(表锁):Intention Shared Locks
- 意向排它锁(表锁):Intention Exclusive Locks
- 自增锁:AUTO-INC Locks
行锁的算法
- 记录锁 Record Locks
- 间隙锁 Gap Locks
- 临键锁 Next-key Locks
共享锁(Shared Locks)
共享锁又称为读锁,简称S锁。共享锁就是多个事务对同一数据可以共享一把锁,都能访问数据,但是只能读取不能修改。
加锁方式:select * from user where id=1 LOCK IN SHARE MODE;
commit/rollback;
排它锁(Exclusive Locks)
排它锁又称为写锁,简称X锁。排它锁不能与其他锁共存。如果一个事务获取了数据行的排它锁,那么其他事务不能再获取该行的锁(排它锁,共享锁)。只有获取了该排它锁的事务才可能对数据行进行读取和修改。(其他事务要读取数据可以来自于快照)
加锁方式:delete/update/insert默认加上X锁
select * from user where id=1 for update
commit/rollback;
Innodb的行锁到底锁了什么
Innodb的行锁是通过给索引上的索引项加锁来实现的
只有通过索引条件进行数据检过,Innodb才会使用行锁,否则Innodb将使用表锁
下面我准备了几个例子来看一下Innodb是怎么锁的:
我们有一个user表,id为主键,name为普通索引,phone为唯一索引,address和age为普通列
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL COMMENT '姓名',
`phone` varchar(20) NOT NULL COMMENT '电话',
`age` int(3) NOT NULL COMMENT '年龄',
`address` varchar(50) DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`),
UNIQUE KEY `i_user_phone` (`phone`) USING BTREE,
KEY `i_user_name` (`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
表里面的数据为:

首先事务A执行下面SQL
BEGIN;
update `user` set `name`='test' where id= 1 ;
这个时候我们另起一个事务B执行下面SQL
BEGIN;
select * from `user` where id= 1 LOCK IN SHARE MODE;
事务C执行下面SQL
BEGIN;
select * from `user` where id= 2 LOCK IN SHARE MODE;
注意上面的事务开启后都没的commit或则rollback;
我们可以看到事务B是处于等待的状态,未拿到锁。而我们的事务C则可以拿到锁,正常执行。
好了,我们回滚上面3个事务,再来看下面的例子:
首先事务A执行下面SQL
BEGIN;
update `user` set `name`='test' where `name`= '芃兮';
这个时候我们另起一个事务B执行下面SQL
BEGIN;
select * from `user` where `name`= '芃兮' LOCK IN SHARE MODE;
事务C执行下面SQL
BEGIN;
select * from `user` where `name`= '贝贝' LOCK IN SHARE MODE;
注意上面的事务开启后都没的commit或则rollback;
和上面的例子一样事务B是处于等待的状态,未拿到锁。而我们的事务C则可以拿到锁,正常执行。
我们下面来看看对非索引字段的操作:
BEGIN;
update `user` set `address`='test' where address= '地址一';
这个时候我们另起一个事务B执行下面SQL
BEGIN;
select * from `user` where address= '地址一' LOCK IN SHARE MODE;
事务C执行下面SQL
BEGIN;
select * from `user` where address= '地址二' LOCK IN SHARE MODE;
注意上面的事务开启后都没的commit或则rollback;
这个时候我们可以看到事务B和事务C都会处于等待的状态,都未拿到锁。
通过上面3个例子我们可以看出:
Innodb的行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件进行数据检过,Innodb才会使用行锁,否则Innodb将使用表锁
意向共享锁(IS)
意向共享锁是指事务准备给数据加入共享锁,必须先拿到该表的意向共享锁。意向共享锁之间是可以相互兼容的。
意向排它锁(IX)
意向排它锁是指事务准备给数据加入排它锁,必须先拿到该表的意向排它锁。
意向锁是Innodb自动加的,不需要用户干预
意向锁的意义:当事务想去进行锁表时,可以先判断意向锁是否存在,存在时则可以快速返回该表不能启用表锁。意向锁是一个标记,标记当前表是否有锁,用于提高性能。
自增锁 AUTO-INC Locks
针对自增列自增长的一个特殊的表级别锁。可以通过下面命令查看:
SHOW VARIABLES like 'innodb_autoinc_lock_mode';
默认值是1,代表连续,事务如果未提交该ID永久丢失。
记录锁 Record Locks
锁住具体的索引项
当sql按照唯一性(Primary key,Unique key)索引进行检索的时候,查询条件等值匹配且查询的数据存在,这时sql语句上的锁即为记录锁,锁住具体的索引项。
间隙锁 Gap Locks
锁住记录不存在的区间(左开右开)
当sql执行按照索引进行数据检索时,查询条件的数据不存在,这时sql语句加上的锁即为间隙锁。锁信记录不存在的区间(左开右开)
临键锁 Next-key Locks
锁住记录+区间(左开右闭)
当sql执行按照索引进行数据检索时,查询条件为范围查找(between and ,<,>)等并有数据命中时,此时Sql语句加上的锁为Next-key Locks,锁住记录+区间(左开右闭)
下面我们还是通过几个例子来看一下:
CREATE TABLE `user_1` (
`id` int(11) NOT NULL,
`name` varchar(20) NOT NULL COMMENT '姓名',
`phone` varchar(20) NOT NULL COMMENT '电话',
`age` int(3) NOT NULL COMMENT '年龄',
`address` varchar(50) DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`),
UNIQUE KEY `i_user_phone` (`phone`) USING BTREE,
KEY `i_user_name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
里面的数据为:
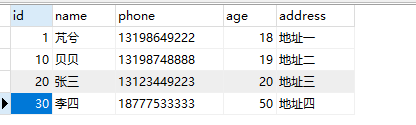
事务A
BEGIN;
update `user_1` set `name`='test' where `id`= 10;
这个时候我们另起一个事务B执行下面SQL
BEGIN;
select * from `user_1` where id= 10 LOCK IN SHARE MODE;
事务C执行下面SQL
BEGIN;
select * from `user_1` where id= 20 LOCK IN SHARE MODE;
注意上面的事务开启后都没的commit或则rollback;
我们可以看到事务A是一个主键等值修改,这个时候事务B是不能拿到锁的,处于等待状态,而事务C则是可以正常拿到锁。所以这个时候通过索引等值查询是用到了记录锁。
下面来看看这个例子:
事务A
BEGIN;
update `user_1` set `name`='test' where `id`> 3 and id <6;
这个时候我们另起一个事务B执行下面SQL
BEGIN;
INSERT into user_1 (id,name,phone,age,address) VALUES (17,'test','138888888',20,'test');
事务C执行下面SQL
BEGIN;
INSERT into user_1 (id,name,phone,age,address) VALUES (7,'test','138888888',20,'test');
注意上面的事务开启后都没的commit或则rollback;
我们可以看到事务A是是修改的一个没有数据的范围值,这个时候事务B是可以正常拿到锁,而事务C则不能拿到锁,处于等待状态,所以这个时候通过是用到了间隙锁。
下面这个例子
事务A
BEGIN;
update `user_1` set `name`='test' where `id`> 3 and id <15;
这个时候我们另起一个事务B执行下面SQL
BEGIN;
INSERT into user_1 (id,name,phone,age,address) VALUES (5,'test','138888888',20,'test');
事务C执行下面SQL
BEGIN;
INSERT into user_1 (id,name,phone,age,address) VALUES (16,'test','138888888',20,'test');
事务D执行下面SQL
BEGIN;
INSERT into user_1 (id,name,phone,age,address) VALUES (21,'test','138888888',20,'test');
注意上面的事务开启后都没的commit或则rollback;
我们可以看到事务A修改的是一个区间,数据库中只有10这一个值,也就是会跨两个区间,1-10,10-20这两个区间
事务B不能正常写处,处理等待状态,事务C不能正常写入,处于等待状态,事务D则是可以正常写入,说明拿到了锁。
由此我们可以看到Innodb是把1-10和10-20这两个区间都锁住了。
通过上面3个例子我们可以明白Innodb为什么把临间锁做为默认行锁的算法了。这也说明了我们上面图中说的Innodb中可重复读为什么不可能出现幻读了。