Pyhton_语法综述_re模块和正则表达式_常用详解(15)
文章目录
- 一、re模块
- (一)关于正则表达式介绍
- (二)Python中操作正则表达式
- (三)字符查询匹配函数
- (四)字符串拆分替换函数
- (五)正则表达式元字符
- (六)正则表达式中的量词
- (七)正则表达式范围匹配
- (八)正则表达式分组
- (九)贪婪模式和懒惰模式
- 二、正则表达常用案例
- 1、正则表达基本使用
- 2、匹配单个字符
- 3、匹配多个字符
- 4、匹配开头和结尾
- 5、案例操作[ 匹配爬取邮箱,合法名判断]
- 6、匹配分组
- 7、案例操作 [ sub() search()findall()]
- 8、贪婪和非贪婪
建议第一节阅读,到第二节可以对照第一节查看使用
一、re模块
(一)关于正则表达式介绍
- 1.数据抓取,数据提取,如:抓取网站中的图片地址
- 2.数据清洗:把不雅的评论清洗掉
- 3.数据验证:验证手机号的合法性
正则表达式:是一种字符串的查询和匹配规则,按照提供的规则完成目标字符串中的数据的查询和检索。
50年代,神经学、精神学两位科学家尝试将大脑中认知事物的方式描述出来,最终没 有成功。70 年代数学家看到了两位科学家笔记/笔录,联合另外一位生物学家一起将人类大脑认知事物的方式,使用数学表达式第一次简单的描述了出来,并没有出现实际的应用价值。肯·汤普森(Unix 之父):学校实验室打工,自己想玩游戏,搭建游戏平台→ 研发第一代的Unix 操作系统,在操作系统中为了能快速的检索字符串信息,研究各种文献发现了数学家发表的论文,将正确规则描述事物的方式-正则表达式-在 Unix操作系统中第一次实现了出来并且取得了非常好的效果。
正则表达式在发展过程中,晨露峥嵘,被很多编程语言所接纳,各种编程语言在构建语法规则的过程中,纷纷表示支持正则表达式的操作语法。python:支持正则表达式语法操作的模块:re
项目需求:录入资料--手机号码
要求:长度11位、都是数字、156|188开头
比较传统解决思路,和使用正则表达的思路,发现,正则表达代码优化更好!
① 传统代码的验证方式
phone = input("请输入您的手机号码:")
def common_verify(phone):
# 判断长度
if len(phone) == 11:
# 判断开头
if phone.startswith("156") or phone.startswith("188"):
# 判断数字
for x in phone:
if not x.isdigit(): # 是数字
break
else:
# 合法手机号码
input("这是一个合法的手机号码")
return True
# 非法手机号码
input("这是一个非法的手机号码")
return False
print(common_verify(phone))
输入正确的结果图:

错误的结果:

② 正则表达式的验证方式
import re
phone = input("请输入您的手机号码:")
def re_verify(phone):
"""验证手机号码是否合法的函数"""
# 定义一个正则表达式
vp = r"(156|188)\d{8}"
return True if len(re.findall(vp, phone)) > 0 else False
re_verify(phone)
(二)Python中操作正则表达式
Python 提供的正则表达式处理模块 re,提供了各种正则表达式的处理函数
● 使用过程 【不一定是这种结构,以最简单说明】:
1.导入模块 import re
2.匹配,ret = re.match("正则 表达式公式", "要匹配的字符串")
3.判断是否成功
ret: 不为空,表示匹配成功,返回match对象
为空,匹配失败
4.取匹配结果 ret。group()
注意:re.match():匹配xxx开头的字符串
● 对应代码说明:
# 匹配 "csdn"
import re
ret = re.match("csdn","csdn.com") # 从头开始匹配
if ret:
print(ret.group())
print(ret)
else:
print("匹配成功")
在结果此处,可以看到有一个"CSDN",这是ret.group()直接查看结果的,而剩下哪行则是对象
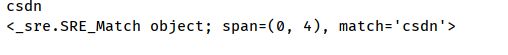
(三)字符查询匹配函数
官方 re.py 可以查看注释,本篇文章主要讲解常用的,并且本文基本基于match函数讲解
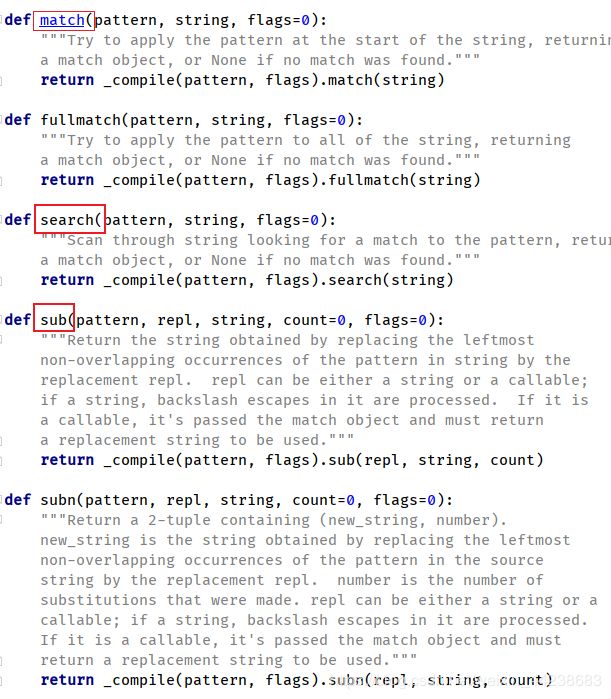

对于函数简单的做一个说明
| 函数 | 说明 |
|---|---|
| re.match(reg,info) | 用于在 开始位置[从左往右] 匹配目标字符串info,符合正则表达式reg,会返回一个match对象,匹配不成功返回None |
| re.search(reg,info) ) | 扫描整个字符串info,符合正则表达式reg,返回一个match对象,否则None |
| re.findall(reg,info) | 扫描整个字符串info,符合正则表达式reg字符串, 提取出来,存放到列表中 |
| re.fullmatch(reg,info) | 扫描整个字符串,字符串在正则表达式reg限定范围,返回整个字符串,否则None |
| re.finditer(reg,info) | 扫描整个字符串,将匹配到的字符保存在一个可以遍历的列表中 |
(四)字符串拆分替换函数
| 函数 | 说明 |
|---|---|
| re.split(reg,string) | 正则表达式reg,将字符串string 才分成一个字符串列表,如:re.split(r"\s+",string),表示使用一个或者多个空白字符对字符串info进行拆分,并返回一个拆分后的字符串列表 |
| re.sub(reg,repl,string) | 使用指定的字符串repl来替换字符串string中匹配的正则表达式reg的字符 |
(五)正则表达式元字符
使用正则表达式时,用到了一些包含特殊含义的字符,用于表示字符串中一些特殊的位置, 非常重要,我们先简单了解一下一些常用的元字符
| 元字符 | 描述 |
|---|---|
| ^ | 表示匹配字符串的开头位置 在 [ ] 中使用代表取反 |
| $ | 表示匹配字符串的结束位置的字符 |
| . | 表示匹配任意一个字符 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \s | 匹配一个空白字符 |
| \S | 匹配一个非空白字符 |
| \w | 匹配一个数字/字母/下划线中任意一个字符 |
| \W | 匹配一个非数字字母下划线的任意一个字符 Python3 中文也算 |
| \b | 匹配一个单词的边界 |
| \B | 匹配不是单词的开头或者结束位置 |
(六)正则表达式中的量词
量词,用于限定字符出现数量的关键字
| 量词 | 描述 |
|---|---|
| x* | 用于匹配符号*前面的字符出现0次或者多次 |
| x+ | 用于匹配符号+前面的字符出现1次或者多次 |
| x? | 用于匹配符号?前面的字符出现0次或者1次 |
| x{n} | 用于匹配符号{n}前面的字符出现n次 |
| x{m,n} | 用于匹配符号{m,n} 前面的字符出现至少m次,最多n次 |
| x{n,} | 用于匹配符号{n,}前面的字符出现至少n次 |
(七)正则表达式范围匹配
在正则表达式中,针对字符的匹配,除了快捷的元字符的匹配,还有另一种使用方括号进行 的范围匹配方式,具体如下:
| 范围 | 说明 |
|---|---|
| [0-9] | 用于匹配一个0~9之间的数字,等价于\d |
| [^0-9] | 用于匹配一个非数字字符,等价于\D |
| [3-6] | 用于匹配一个3~6之间的数字 |
| [a-z] | 用于匹配一个a~z之间的字母 |
| [A-Z] | 用于匹配一个A~Z之间的字母 |
| [a-f] | 用于匹配一个a~f之间的字母 |
| [a-zA-Z] | 用于匹配一个a-z或者A-Z之间的字母,匹配任意一个字母 |
| [a-zA-Z0-9] | 用于匹配一个字母或者数字 |
| [a-zA-Z0-9] | 用于匹配一个字母或者数字或者下划线,等价于\w |
| [^a-zA-Z0-9] | 用于匹配一个非字母或者数字或者喜爱划线,等价于\w |
(八)正则表达式分组
正则表达式主要是用于进行字符串检索匹配操作的利器,在一次完整的匹配过程中,可以将 匹配到的结果进行分组,这样就更加的细化了我们对匹配结果的操作,正则表达式通过圆括 号()进行分组,以提取匹配结果的部分结果。常用的两种分组:
| 分组 | 描述 |
|---|---|
| (expression) | 使用圆括号直接分组;正则表达式本身匹配的结果就是一个组,可以通过group()或者group(0)获取;然后正则表达式中包含的圆括号就是按照顺序从1开始编号的小组 |
| (?Pexpression) | 使用圆括号分组,然后给当前的圆括号表示的小组命名为name,可以通过group(name)进行数据的获取 |
(九)贪婪模式和懒惰模式
贪婪模式:从目标字符串的两头开始搜索,一次尽可能多的匹配符合条件的字符串,但是有 可能会匹配到不需要的内容,正则表达式中的元字符、量词、范围等都模式是贪婪匹配模式, 使用的时候一定要注意分析结果:
`<div>.*</div>就是一个贪婪模式,用于匹配<div>和 </div>之间所有的字符
懒惰模式: 从目标字符串按照顺序从头到位进行检索匹配,尽可能的检索到最小范围的匹配 结果,语法结构是在贪婪模式的表达式后面加上一个符号?即可,
如<div>.*?</div>就是一个 懒惰模式的正则,用于仅仅匹配最小范围的<div>和</div>之间的内容
二、正则表达常用案例
1、正则表达基本使用
# 匹配 "csdn"
import re
ret = re.match("csdn","csdn.com") # 从头开始匹配
if ret:
print(ret.group())
print(ret)
else:
print("匹配成功")
2、匹配单个字符
"""
常用的
"""
import re
# 1. “.” : 表示匹配任意一个字符,除了\n(换行符)以外
# 案例:看电影,输入电影名称:“速度与激情”时,“激”字符可以任意输入,都算成功
# ret = re.match("速度与.情","速度与激情123123")
# print(ret)
# 2. [] : 匹配 “ []”列举的字符
# 案例:看电影,输入电影名称:“速度与激情”时,“速度与激情1”时 和 “速度与激情2”都正确
# ret = re.match("速度与激情[1245678]","速度与激情1") # 成功
# ret = re.match("速度与激情[1245678]","速度与激情a") # None
# ret = re.match("速度与激情[1245678]","速度与激情10") # 需要完善
# ret = re.match("速度与激情[1-8]","速度与激情8") # 另外个写法,成功 简化
# “速度与激情6”不匹配
# ret = re.match("速度与激情[1-57-8]","速度与激情6") #None
# ret = re.match("速度与激情[a-z]","速度与激情a") #成功,如果是注册也可以
# print(ret)
# 3. \d :匹配数字,0-9
# ret = re.match("速度与激情\d","速度与激情6") #成功
# 4. \D :匹配非数字
# ret = re.match("速度与激情\D","速度与激情6") #None
# ret = re.match("速度与激情\D","速度与激情a") #成功
# print(ret)
# 5. \s 匹配空格,包含空格和tab
# ret = re.match("速度与激情\s","速度与激情 ") #成功
# ret = re.match("速度与激情\s","速度与激情a") #None
# ret = re.match("速度与激情\s","速度与激情 a") #成功
# print(ret)
# 6. \S 匹配空格,只要不是空格都匹配
# ret = re.match("速度与激情\S","速度与激情a")#成功
# ret = re.match("速度与激情\S","速度与激情")#None
# print(ret)
# 7. \w 匹配单词字符:包含(a-z,A-Z,0-9,_下划线)
# 在python3 中,中文字符包含在单词字符中
# ret = re.match("\w","1")#成功
# ret = re.match("\w","a")#成功
# ret = re.match("\w","_")#成功
# ret = re.match("\w","@")#None
# ret = re.match("\w","稳")#成功 !!
# print(ret)
# 8. \W 匹配非单词字符
# ret = re.match("\W","@")#成功
# ret = re.match("\W","=")#成功
# ret = re.match("\W","张")#None
ret = re.match("\W","a")#None
print(ret)
3、匹配多个字符
import re
# 1.{m} : 匹配前一个字符出现m次
# 匹配合法手机号
# 规则 要求满足11位,并且第一位是 1
# ret = re.match("\d{11}","12345687901")# 成功 判断规则:数字+11位
# ret = re.match("1\d{10}","12345687901")# 成功 除了第一位,往后10位匹配
# ret = re.match("1\d{10}","42345687901")# None 开头不为1
# ret = re.match("1\d{10}","1234fg68791")# None 包含了字母
# ret = re.match("1\d{10}","12345687901asd")# 成功,10后 没有参与匹配
# print(ret)
# 2.{m,n} : 匹配前一个字符出现m到n次
# 验证电话号码的合法性 如:010-1234567,0558-8080255
# 规则:区号3-4位数字,电话号是7-8位,中间用“ - ” 连接
# ret = re.match("\d{3,4}-\d{7,8}","010-12345678")#成功
# ret = re.match("\d{3,4}-\d{7,8}","0558-8080255")#成功
# ret = re.match("\d{3,4}-\d{7,8}","0558-8080255a")#成功
# print(ret)
# 3.?: 前一个字符出现0次或者1次,要么出现1次,要么出现0次
# 验证电话号码的合法性 如:010-1234567,0558-8080255
# 规则:区号3-4位数字,电话号是7-8位,中间用“ - ” ,“-”可有可无
# ret = re.match("\d{3,4}-\d{7,8}","0101234567")#None
# # ret = re.match("\d{3,4}-?\d{7,8}","0101234567")#成功
# ret = re.match("\d{3,4}-?\d{7,8}","010@1234567")#None
# print(ret)
# 4. * : 匹配前一个字符出现0次或多次
# 要求:把一个文本内容全部提取出来
# content = "life is short, I use Python !"
# ret = re.match(".",content) # 匹配的第一个
# ret = re.match(".*",content) # 匹配所有,只能匹配一行
# content = "life is short, I use \n Python !"
# ret = re.match(".*",content,re.S) # re.S 可以匹配多行
# ret = re.match(".*","") # 成功
# print(ret)
# 5. + :匹配前一个字符,出现1次或者多次,即至少出现1次
# ret = re.match("a+","aaaa")# 成功
ret = re.match("a+","")# None
print(ret)
4、匹配开头和结尾
import re
# 1. ^ :匹配开头的字符串
# ret = re.match("csdn","csdn.com") # 成功
# ret = re.match("csdn","www.csdn.com") # None
# ret = re.search("csdn","www.csdn.com") # 成功
# ret = re.search("^csdn","www.csdn.com") # None
# print(ret)
# 注意用在[]表示取反
# ret = re.match("速度与激情[^6]","速度与激情9") # 成功
# ret = re.match("速度与激情[1-57-9]","速度与激情9") # 成功
# print(ret)
# 2. $ :匹配以XXX结尾的字符串
# 匹配出合法的手机号
# 规则:11位数字 且第一位是1
# ret = re.match("1\d{10}","12345678901") # 成功
# ret = re.match("1\d{10}","12345678901abc") # 成功 后面字母没有匹配,不符合
ret = re.match("1\d{10}$","12345678901abc") # None
print(ret)
5、案例操作[ 匹配爬取邮箱,合法名判断]
import re
# 1、匹配出合法的变量名
# 匹配规则:字符由数字,字母,下划线组成,首字符不能是数字
names = ["age1","1age","AGO_","_9age","age_","a9#_2","a#ge"]
for i in names:
ret = re.match("[a-zA-Z_]\w*",i) #
if ret :
print(f"{i}是合法的")
else:
print(f"{i}不合法")
# 2、匹配合法的163邮箱
# 匹配规则:每个邮箱以“@163.com”结尾,@之前4-20单词字符
# email_list = ["[email protected]","[email protected]","[email protected]","[email protected]","liang@163ccom"]
# for a in email_list:
# ret = re.match("\w{4,20}@163\.com$",a)
# if ret:
# print(f"{a}是合法的")
# else:
# print(f"{a}不合法")
6、匹配分组
import re
# 1. | : 匹配左右任意一个表达式 管道符
# email_list = ["[email protected]","[email protected]","[email protected]","[email protected]","liang@163ccom"]
# for a in email_list:
# ret = re.match("\w{4,20}@163\.com$|\w{4,20}@126\.com|\w{4,20}@qq\.com",a)
# if ret:
# print(f"{a}是合法的")
# else:
# print(f"{a}不合法")
# 2、 (ab):分组
# A、引入
email = "[email protected]"
ret = re.match("(\w{4,20})@qq\.com",email)
print(ret.group())
print(ret.group(1))
# email_list = ["[email protected]","[email protected]","[email protected]","[email protected]","liang@163ccom"]
# for a in email_list:
# ret = re.match("\w{4,20}@(163|qq|126)\.com$",a)
# if ret:
# print(f"{a}是合法的")
# else:
# print(f"{a}不合法")
# 3、引用分组 \num: 引用分组匹配到的字符串
# 检查html网页的合法性
# 语法规则:标签必须配对
# content = "hello world
" # 前后配对 合法
# content = "hello world
" # 前后不配对也合法
# ret = re.match("<\w+>.*",content) # 不严谨的写法
# ret = re.match("<(\w+)>.*",content) # 严谨的写法
# print(ret)
# 4、给分组起别名(?P) 写到前面
# 5、(?P=name):引用别名为name的分组匹配到的字符串
# 检查html网页的合法性
# content = "hello world
"
# # ret = re.match("<(\w+)><(\w+)>.*<(/\\2)>",content)
# ret = re.match("<(?P\w+)><(?P\w+)>.*",content)
# print(ret)
7、案例操作 [ sub() search()findall()]
import re
# 1、search
# content = "阅读次数88次,下载次数30次"
# ret = re.search("\d+",content)
# print(ret) # 只打印一个结果,并不能所有匹配
# # 2、findall(): 查找字符串中所有匹配的数据,返回的是列表
# # 匹配所有数字
content = "阅读次数88次,下载次数30次"
ret = re.findall("\d+",content)
print(ret) # 打印列表 包含所有数字
# 3、sub() :替换,返回的是替换后的字符串
# 将所有次数归0
# content = "阅读次数88次,下载次数30次"
# ret = re.sub("\d+","0",content)
# print(ret) # 只打印一个结果,并不能所有匹配
8、贪婪和非贪婪
"""
Python 中默认是贪婪,总是尝试尽可能多的匹配字符,非贪婪相反,总是尽可能少的匹配字符
"""
import re
# 1、Python 中默认是贪婪,总是尝试尽可能多的匹配字符,非贪婪相反,总是尽可能少的匹配字符
# ret = re.match("\d{2,5}","12345")
# print(ret) # 匹配了5次
# 2、字符串前面加r“表示原生字符串”
# 3、re.complie(strPattern)
# 将字符串形式的正则表达式编译成pattern对象
pattern = re.compile("\d{2,5}")
ret = pattern.match("12345")
print(ret)