k近邻法算法对鸢尾花数据集进行分析
一.算法设计
k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
k-近邻算法步骤如下:
获取数据集,分析数据;
数据集划分;
使用KNN算法处理数据:
1.计算已知类别数据集中的点与当前点之间的距离;根据欧式距离公式
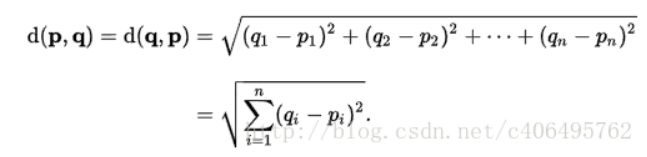
2.按照距离递增次序排序;
3.选取与当前点距离最小的k个点;
4.确定前k个点所在类别的出现次数;
5.返回前k个点所出现次数最高的类别作为当前点的预测分类。
二.有注释的源代码
def knn(x_test,x_data,y_data,k):
# 计算样本数量
x_data_size=x_data.shape[0]
# 复制x_test
np.tile(x_test,(x_data_size,1))
# 计算x_test与每一个样本的差值
diffMat=np.tile(x_test,(x_data_size,1))-x_data
# 计算差值的平方
sqDiffMat=diffMat**2
# 求和
sqDistances=sqDiffMat.sum(axis=1)
# 开方
distances=sqDistances**0.5
# 从小到大排序
sortedDistances=distances.argsort()
classCount={}
for i in range(k):
# 获取标签
votelabel=y_data[sortedDistances[i]]
#统计标签数量
classCount[votelabel] = classCount.get(votelabel,0)+1
# 根据operator.itemgetter(1)-第一个值对ClassCount排序,然后取倒叙
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
遇到的问题:
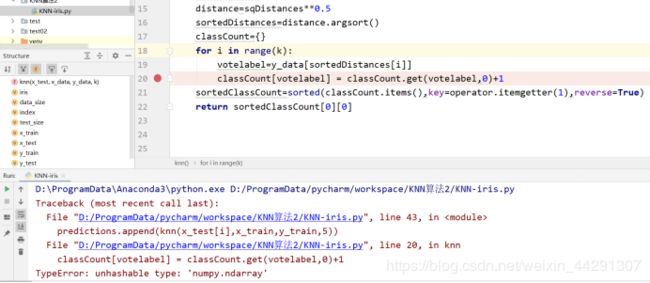
这次的代码是参考过资料以后自己实现的可是遇到了一些问题
TypeError: unhashable type: ‘numpy.ndarray’
查看网上教程的修改结果以后
类型错误:不可hash的类型:‘numpy.ndarray’
解决的思路,如下:
T1、先尝试修改变量名:看到莫名其妙的TypeError要考虑是否存在变量名重复,或者是由于变量名与占位符名冲突导致的。
T2、转为numpy数组:因为得到的X_test_label,其实是 DataFrame格式,故该格式是不能用于迭代的。尝试可将其转化成 np.array 格式的,如 X_train = np.array(X_train)
X_test_label=np.array(X_test_label)
可是这个错误我还是不明白为什么,实现起来还是有错误后面就进行调试
最后附上源代码:
import numpy as np
import operator
import pandas as pd
# newInput: 新输入的待分类数据(x_test),本分类器一次只能对一个新输入分类
# dataset:输入的训练数据集(x_train),array类型,每一行为一个输入训练集
# labels:输入训练集对应的类别标签(y_train),格式为['A','B']而不是[['A'],['B']]
# k:近邻数
# weight:决策规则,"uniform" 多数表决法,"distance" 距离加权表决法
def KNNClassify(newInput, dataset, labels, k, weight):
numSamples = dataset.shape[0]
"""step1: 计算待分类数据与训练集各数据点的距离(欧氏距离:距离差值平方和开根号)"""
diff = np.tile(newInput, (numSamples, 1)) - dataset # 凸显numpy数组的高效性——元素级的运算
squaredist = diff ** 2
distance = (squaredist.sum(axis=1)) ** 0.5 # axis=1,按行累加
"""step2:将距离按升序排序,并取距离最近的k个近邻点"""
# 对数组distance按升序排序,返回数组排序后的值对应的索引值
sortedDistance = distance.argsort()
# 定义一个空字典,存放k个近邻点的分类计数
classCount = {}
# 对k个近邻点分类计数,多数表决法
for i in range(k):
# 第i个近邻点在distance数组中的索引,对应的分类
votelabel = labels[sortedDistance[i]]
if weight == "uniform":
# votelabel作为字典的key,对相同的key值累加(多数表决法)
classCount[votelabel] = classCount.get(votelabel, 0) + 1
elif weight == "distance":
# 对相同的key值按距离加权累加(加权表决法)
classCount[votelabel] = classCount.get(votelabel, 0) + (1 / distance[sortedDistance[i]])
else:
print("分类决策规则错误!")
print("\"uniform\"多数表决法\"distance\"距离加权表决法")
break
# 对k个近邻点的分类计数按降序排序,返回得票数最多的分类结果
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
if weight == "uniform":
print("新输入到训练集的最近%d个点的计数为:" % k, "\n", classCount)
print("新输入的类别是:", sortedClassCount[0][0])
elif weight == "distance":
print("新输入到训练集的最近%d个点的距离加权计数为:" % k, "\n", classCount)
print("新输入的类别是:", sortedClassCount[0][0])
return sortedClassCount[0][0]
iris=pd.read_csv("iris.txt")
iris.head()
iris_x=iris.iloc[:,[0,1,2,3]]
iris_y=iris.iloc[:,[4]]
np.random.seed(7)
indices=np.random.permutation(len(iris_x))
iris_x_train=iris_x.iloc[indices[0:130]]
iris_y_train=iris_y.iloc[indices[0:130]]
iris_x_test=iris_x.iloc[indices[130:150]]
iris_y_test=iris_y.iloc[indices[130:150]]
# 将dataframe格式的数据转换为numpy array格式,便于 调用函数计算
iris_x_train=np.array(iris_x_train)
iris_y_train=np.array(iris_y_train)
iris_x_test=np.array(iris_x_test)
iris_y_test=np.array(iris_y_test)
# 将labels的形状设置为(130,)
iris_y_train.shape=(130,)
if __name__ == '__main__':
test_index = 15
predict = KNNClassify(iris_x_test[test_index], iris_x_train, iris_y_train, 20, "distance")
print(predict)
print("新输入的实际类别是:", iris_y_test[test_index])
print("\n")
if predict == iris_y_test[test_index]:
print("预测准确!")
else:
print("预测错误!")