Python入门与进阶:手把手教你掌握Pandas三大利器
回顾一下,2018 年中国的电影票房可以说是再创了一个新纪录,实现了总票房突破 600 亿的成绩。作为一个影迷,当然还是需要认真盘点一下啦!今天我们使用 Python 的 Pandas 库,对猫眼专业电影排行榜的 2018 年电影票房 Top50 的数据来进行一次简单的数据分析。
Part one:Index
Pandas 库是用于提供高性能易用数据类型和分析工具的 python 第三方库,而要对Series、Dataframe类型的数据进行运算、提取数据特征、进行数据间的关联等操作,离不开对 index 的使用。下面,我们就用猫眼电影数据为例子,解锁数据分析的新姿势。
更多干货分享加python编程语言学习QQ群 515267276
数据读取与观察
因为 pandas 是基于 numpy 实现的,我们需要导入 numpy 与 pandas 库和数据存储路径,并使用 read_csv 函数读取数据,用head函数展示数据的前几行(默认为5行):


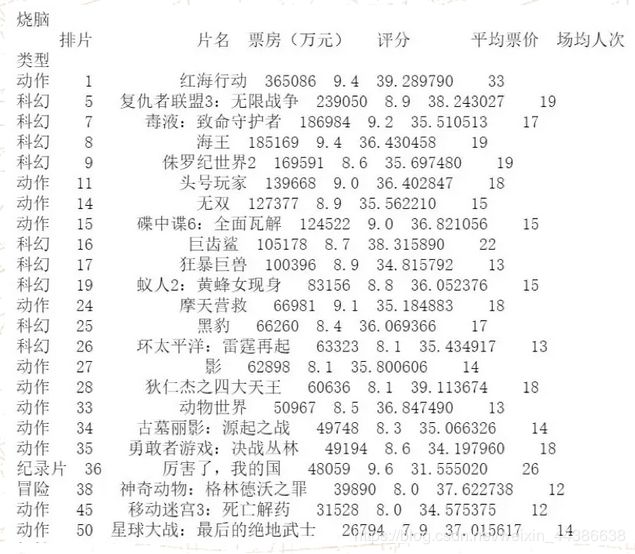
remark:排片是按照票房数据进行的排名
基于index的数据排序与筛选
接下来,我们可以对这些电影按照上映时间排序,再对排序后的电影进行提取、筛选、汇总的操作。这里我们想要提取每个月份的电影数据,并汇总。
第一步,是对上映时间转换格式,我们采用 datatime 的时间格式。然后,以上映时间作为排序变量,对电影数据进行重新排序:

当当当~成功按照上映时间进行展示:

可这还不够,我们要做的是将上映时间作为我们的行索引(index),方便我们进行数据处理。所以我们进行第二步,指定该列作为我们的行索引:

最后,我们就可以对这Top50的电影数据按月度进行加总,终于得到每个月度Top50票房电影的票房总额:

It's amazing!
使用index对数据直接索引筛选
Pandas 的 index 功能提供了对低维数据和高维数据的索引和筛选功能,既可以采用行列索引的方式提取某个元素值,也可以通过切片的方式提取部分行列的元素值。
举两个栗子来说明方法。
第一个,我们想提取出在去年正月初一新春第一天,也就是2018年2月16日上映的所有电影的类型,我们可以这样操作:
我们先将这些数据放入一个 DataFrame 中,并检查对应的列索引。

有了行列索引,我们就可以根据对应的索引来找到相应的数据值,然后使用 loc 函数分别指定行索引和列索引:

成功得到2018年2月16日在榜单里的所有上映电影的类型,在该日有 5 场电影上映,其中 3 部为喜剧,一部动作片,一部动画片。是不是发现和 2019 年的新春贺岁片布局很接近呢,不得不提,笔者对今年初一即将上映的几部喜剧片也是关注满满呢。
如果我们还想要展示每个日期内每场电影的详细数据,我们也可以使用 stack 函数,继续以2018-02-16上映的电影为例:

第二个小栗子,我们想要提取出 2018 年票房 Top50 所有电影中的类型为动作片的电影,并按照票房排名顺序排列(动作片是我的最爱),我们可以加上切片索引的方式,像下面这样:

我们也可以按电影类型计算不同日期内上映的电影票房总数,使用一个简单的 pivot_table(数据透视表)就可以了(展示部分结果):

这就是 pandas 的 index 简单应用,有没有很简单,一学就会呢!
其实,index 就像是 pandas 解锁数据分析的钥匙,好好使用这把钥匙,就可以轻松处理低维数据,进而进阶高维数据,当然,这也还需要结合许多其他的 pandas 数据操作方式,比如下面的 groupby。
Part two:GroupBy
在上述操作中,我们使用了 resample 来实现对这 Top50 电影的票房数据按月度进行加总。其实 pandas 还提供了一种非常强大且简便的工具可以轻松实现分类统计的功能,就是接下来要介绍的 groupby 对象。
Groupby 从字面意思上很好理解,可以认为是以下三个步骤的总称:
-
基于一些准则,将数据分组;
-
对每个组独立地调用函数;
-
将结果组合成一个你想要的数据结构。
GroupBy的分组原理
1.不论分组键是数组、列表、字典、Series、函数,只要其与待分组变量的轴长度一致都可以传入groupby进行分组。
2.默认axis=0按行分组,可指定axis=1对列分组。

接下来,我们就上手开始应用吧!
Groupby基础数据分析
电影票房哪家强?
首先计算每种类型下电影的排片、票房、评分、票价、场均人次的均值:

可以看出,在高分电影中,喜剧、爱情、科幻是票房最高的三种,这也和主流市场的偏好相吻合。从评分上看,纪录片的评分是最高的。
纪录片最优?质疑!
更多干货分享加python编程语言学习QQ群 515267276
这个时候笔者就质疑了,难道大家思想觉悟都这么高吗?仔细思考了一下,联想到纪录片的票房显著很低,也许只是因为纪录片只有一部特别棒的上榜了,所以评分自然高了。所以这里我们可以使用 groupby 的 size 方法,来查看每个组的大小:

果然不出所料,纪录片只有一部进入了前50,所以,同学们在分析的时候,千万别把小样本的数据当作总体的信息啦。
灵活的GroupBy分组
Groupby 的分组相当灵活,除了根据已有的列或者索引进行分组外,还能自定义组别。
-
通过字典确定分组关系
轻松电影VS烧脑?电影大作战!
先将电影类型分为两类。我们认为,喜剧、爱情、动画这三类电影属于“轻松”类,其他电影属于“烧脑”类,我们仅就这两类进行分组统计。
为了达成目的,需要先将电影类型设置为索引(展示部分结果):
![]()

接下来,直接传入 mapping 作为 groupby 的参数,针对 grouped 对象使用 mean 方法即可:


看来,轻松类的电影虽然在排片上和票价上不如烧脑类,但是从票房、评分、人次上来看都稳稳地赢了啊,如果影院看到这样的结果,会不会决定多对轻松类电影排片呢?
如果我们想查看分组后的具体细节,可以采用迭代分组的方式:

这样就可以依次输出组别和对应的组详细信息:

多组别分组
上述内容只介绍了单组别分组,其实我们完全可以使用索引和列名、索引和函数、列名和函数(字典)、花式索引等来进行分组,只有你想不到,没有做不到。
-
通过花式索引分组
我们选取电影类型和片名长度作为二级索引,然后对多级索引进行分组,输出每组的最小值:

-
同时使用索引和列分组
假设我们想对类型这个 index 和场均人次列进行分组,并求平均,可以使用 Grouper 指定第一级索引,再和列名组合起来作为分组标志。

以上就是 pandas 中 groupby 的基础操作简介,是不是同样很简单呢!(信心满满!)
![]()

Part three:Matplotlib之pyplot
为什么要数据可视化?
一般来说,数据可视化的目的有两个:一是在数据分析开始时熟悉数据,观察特点;二是在项目的报告或展示阶段,以美观直接的方式向他人介绍自己数据分析的结果。数据可视化可以使我们看到变量的分布和变量之间的关系,还可以检查建模过程中的假设。
Python 提供了若干种用于绘图的扩展包,包括matplotlib、pandas、ggplot和seaborn。其中,matplotlib是最基础的。
Pandas 可以直接通过 plot 函数对 Series 及DataFrame 进行图形绘制,简化了创建图表的过程。 plot 函数默认创建折线图,通过设置参数 kind,可以创建其他类型的图表。
在使用 Pandas 绘图之前,我们需要写下:

上一句的作用是,matplotlib.pyplot 的绘图函数 plot() 在进行绘图或生成一个 figure 画布时,直接在 python console 里面生成图像。
前一句是使用 ggplot 样式,后一句的作用是: matplotlib.pyplot 的绘图函数 plot() 在进行绘图或生成一个 figure 画布时,直接在 python console 里面生成图像。
这里,%matplotlib qt5 会让图像在跳出的单独小窗中显示;若写成 %matplotlib inline,则适用于 jupyter notebook 的内嵌式显示,Spyder 中会在显示在右边,很小,不方便看。
各种图形的功能
Pandas绘图操作
| 1 |
折线图:它通常用来表示数据随着时间发生的变化,支持多组数据对比。 绘图命令:*.line.plot() |
| 2 |
条形图:能够使人们一眼看出各个数据的大小;易于比较平行数据之间的差别。 绘图命令:*.bar.plot()——条形图 *.barh.plot()——横向条形图 |
| 3 |
直方图:描述的是一组数据的频次分布,易于知道众数、中位数的大致位置、以及数据是否存在缺口或者异常值。 绘图命令:*.hist.plot() |
| 4
|
箱线图:箱线图可以表示出数据的最小值、第一四分位数、中位数、第三四分位数和最大值。 绘图命令:*.box.plot() |
| 5 |
饼图: 易于观察各部分占总体的比例。 绘图命令:*.pie.plot() |
| 6
|
散点图:直观反映数据集中情况,对离散数据线性回归等曲线预测性的拟合辅助作用。 绘图命令:*.scatter.plot() |
绘制条形图、散点图与直方图
我们以上文的电影为例,展示三种图像的绘制方法。
现在我们想看看 50 部电影的评分,并将他们用条形图表现出来,我们创建一个 DataFrame, 并只提取“片名”与“评分”。
现在我们想关注这 50 部电影的评分,并打算将他们用图像的形式表现出来,我们创建一个 DataFrame,并只提取“片名”与“评分”:

我们想把评分由高到低排列,并把“片名”作为新的索引,采用 sort_values 与 set_index 实现。

接着用 plot.bar 实现画图,出现了:

嗯?怎么都是框框,没有一个中文字?为了让中文字显示出来,我们需要:


出现了中文字,但是这样显示 50 部电影的评分真的很丑,不能获取什么有用的信息。
于是,我们打算用散点图看看 50 个分数的情况,散点图中点颜色的深浅可以代表评分的高低,这样我们可以很容易地找出哪部电影的评分低,哪部的评分高。使用 DataFrame.plot.scatter() 方法绘制。
散点图的 x 轴,y 轴都需要数字列,我们可以用电影的原始编号来代替这些电影,将x轴与y轴都设成一样的,形成由 50 个点组成的“45度线”。
由于我们之前用片名重新做了索引,这里需要进行一些处理。

说明:sort_values是将这些数据按照评分进行排序,
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
这样我们就把电影的编号成功地插入到了 DataFrame 的最后一列,叫做 d 列。接下来,我们用这一列作为 x 轴与 y 轴的参数,关键字 c 作为列的名称给出,为每个点提供颜色。函数中 s 控制点的大小,还可以用 color 指定颜色。

这样比之前的条形图直观也好看了很多,点颜色的深浅代表了评分的高低。注意到第 32 个点颜色最浅,也就是原始编号为 31 的电影,是哪部呢?
原来是它:

接下来,我们用直方图看看电影的评分都集中在哪些区间。
先看总体情况,选取“评分”栏使用 DataFrame.plot.hist() 绘制,alpha 表示直方图的透明度。
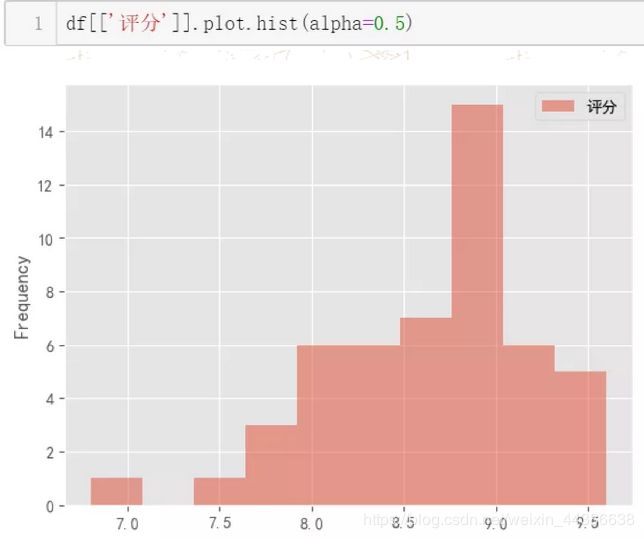
可以看出,这 50 部电影的评分在 8.7-9.1 区间内居多。
当然,我们也想看看不同类型的电影的评分是怎样的。
首先,我们需要创建一个新的 DataFrame,将同一类型的评分放在一列。这里我们选取动作、喜剧与科幻三种类型。先将每一种类型的评分单独提取出来,采用df[df.column==’a’],a 是 column 中特定的值。接着将这些评分进行组合形成新的 DataFrame。由于数据层次不齐,新的DataFrame中肯定有缺失值,我们用DataFrame.dropna()将它们删除:

接下来就可以画图啦!还是和上边一样用 hist 函数,不过这里我们将参数 stacked 设置为 True,不然三个直方图的颜色会相互渗透,分不清楚谁是谁了。

从这个图中我们能够得到的信息是:50部电影中科幻片在这三种类型中最多;三种类型的电影评分最多的区间仍为 8.7-9.1,喜剧与科幻评分第二集中的区间为 7.9-8.2;动作片中有一部口碑较差的。
更多干货分享加python编程语言学习QQ群 515267276
结语
Pandas 作为数据分析的首选库,提供了 Series 和 DataFrame 这两个按轴自动或显式数据对齐功能的数据结构,灵活掌握 index 是入门 pandas 的首要步骤。Groupby 操作是对数据进行数学运算和约简的一个重要方法,读者可以参照 SQL 中的 groupby 函数来类比理解。最后,可视化是数据分析者和外界交流的重要语言。图形的表现力远胜于文字,熟练使用 matplotlib 创造出一系列极富表现力的图形,对于数据分析者来说,是一项非常具有竞争力的技能。
本文的介绍仅仅是基础的 pandas 操作入门,旨在引起读者的兴趣。pandas作为一个日益强大的库,需要我们持续不断的学习和训练才能将其掌握。加油鸭!