轻量级神经网络:MobileNetV1到MobileNetV3
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNetV1(2017):https://arxiv.org/abs/1704.04861?context=cs
MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNetV2(2018):https://arxiv.org/abs/1801.04381
Searching for MobileNetV3
MobileNetV3(2019):https://arxiv.org/abs/1905.02244?context=cs
这是一种为移动设备设计的通用计算机视觉神经网络,实现分类/目标检测/语义分割多目标任务。
小型化方面常用的手段有:
(1)卷积核分解,使用1×N和N×1的卷积核代替N×N的卷积核。
(2)使用bottleneck结构,以SqueezeNet为代表。
(3)以低精度浮点数保存,例如Deep Compression。
(4)冗余卷积核剪枝及哈弗曼编码。
MobileNet 深入的研究了depthwise separable convolutions使用方法后设计出MobileNet,depthwiseseparable convolutions的本质是冗余信息更少的稀疏化表达。在此基础上给出了高效模型设计的两个选择:宽度因子(width multiplier)和分辨率因子(resolutionmultiplier);通过权衡大小、延迟时间以及精度,来构建规模更小、速度更快的MobileNet。Google团队也通过了多样性的实验证明了MobileNet作为高效基础网络的有效性。
深度可分离卷积(Depthwise Separable Convolution,DSC),DSC包含两部分:depthwise convolution(DWC)+ pointwise convolution(PWC)。DWC对输入的通道进行滤波,其不增加通道的数量,PWC用于将PWC不同的通道进行连接,其可以增加通道的数量。通过这种分解的方式,可以明显的减少计算量。
一、MobileNetV1
1.1 四个问题
1 要解决什么问题?
在现实场景下,诸如移动设备、嵌入式设备、自动驾驶等等,计算能力会受到限制,所以目标就是构建一个小且快速(small and low latency)的模型。
2 用了什么办法解决?
1)提出了MobileNet架构,使用深度可分离卷积(depthwise separable convolutions)替代传统卷积。
2)在MobileNet网络中还引入了两个收缩超参数(shrinking hyperparameters):宽度乘子(width multiplier)和分辨率乘子(resolution multiplier)。
3 效果如何?
在一系列视觉任务如ImageNet分类、细粒度分类、目标检测等等上,显著降低模型大小的同时也取得了不错的效果。
4 还存在什么问题?(参考自知乎)
1)MobileNet v1的结构过于简单,是类似于VGG的直筒结构,导致这个网络的性价比其实不高。如果引入后续的一系列ResNet、DenseNet等结构(复用图像特征,添加shortcuts)可以大幅提升网络的性能。
2)Depthwise Convolution存在潜在问题,训练后部分kernel的权值为0。
1.2 网络结构

Depthwise Separable Convolution实质上是将标准卷积分成了两步:depthwise卷积和pointwise卷积,其输入与输出都是相同的。
1):depthwise卷积:对每个输入通道单独使用一个卷积核处理。(图b)
2):pointwise卷积:1×1卷积,用于将depthwise卷积的输出组合起来。(图c)

上图中,左为标准,右图为深度可分离卷积。
MobileNet的大多数计算量(约95%)和参数(约75%)都在1×1卷积中,剩余的大多数参数(约24%)都在全连接层中。
由于模型较小,可以减少正则化手段和数据增强,因为小模型相对不容易过拟合。
1.3 控制MobileNet模型大小的两个超参数
Width Multiplier: Thinner Models
用 α 表示,该参数用于控制特征图的维数,即通道数。(文中引入了α作为宽度缩放因子,其作用是在整体上对网络的每一层维度(特征数量)进行瘦身。α影响模型的参数数量及前向计算时的乘加次数。)
Resolution Multiplier: Reduced Representation
用 ρ 表示,该参数用于控制特征图的宽/高,即分辨率。(该因子即为ρ,用于降低输入图像的分辨率(如将224224降低到192192,160160,128128)。)
二、MobileNetV2
V2 主要引入了两个改动:Linear Bottleneck和 Inverted Residual Blocks。
2.1 Inverted Residual Blocks
MobileNetV2 结构基于 inverted residual。其本质是一个残差网络设计,传统 Residual block 是 block 的两端 channel 通道数多,中间少,而本文设计的 inverted residual 是 block 的两端 channel 通道数少,block 内 channel 多,类似于沙漏和梭子形态的区别。另外保留 Depthwise Separable Convolutions。
2.2 Linear Bottlenecks
感兴趣区域在 ReLU 之后保持非零,近似认为是线性变换。
ReLU 能够保持输入信息的完整性,但仅限于输入特征位于输入空间的低维子空间中。
对于低纬度空间处理,论文中把 ReLU 近似为线性转换。
2.3对比
2.3.1 对比 MobileNet V1 与 V2 的微结构

相同点
都采用 Depth-wise (DW) 卷积搭配 Point-wise (PW) 卷积的方式来提特征。这两个操作合起来也被称为 Depth-wise Separable Convolution,之前在 Xception 中被广泛使用。这么做的好处是理论上可以成倍的减少卷积层的时间复杂度和空间复杂度。
不同点:Linear Bottleneck
V2 在 DW 卷积之前新加了一个 PW 卷积。这么做的原因,是因为 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。现在 V2 为了改善这个问题,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数 t = 6,这样不管输入通道数是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维 进行着辛勤工作的。
V2 去掉了第二个 PW 的激活函数。论文作者称其为 Linear Bottleneck。这么做的原因,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个 PW 的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用 ReLU6 了。
2.3.2 对比 ResNet 与 MobileNet V2 的微结构

相同点
MobileNet V2 借鉴 ResNet,都采用了 1 x1 > 3 x 3 > 1 x1 的模式。
MobileNet V2 借鉴 ResNet,同样使用 Shortcut 将输出与输入相加(未在上式画出)
不同点:Inverted Residual Block
ResNet 使用 标准卷积 提特征,MobileNet 始终使用 DW卷积 提特征。
ResNet 先降维 (0.25倍)、卷积、再升维,而 MobileNet V2 则是 先升维 (6倍)、卷积、再降维。直观的形象上来看,ResNet 的微结构是沙漏形,而 MobileNet V2 则是纺锤形,刚好相反。因此论文作者将 MobileNet V2 的结构称为 Inverted Residual Block。这么做也是因为使用DW卷积而作的适配,希望特征提取能够在高维进行。
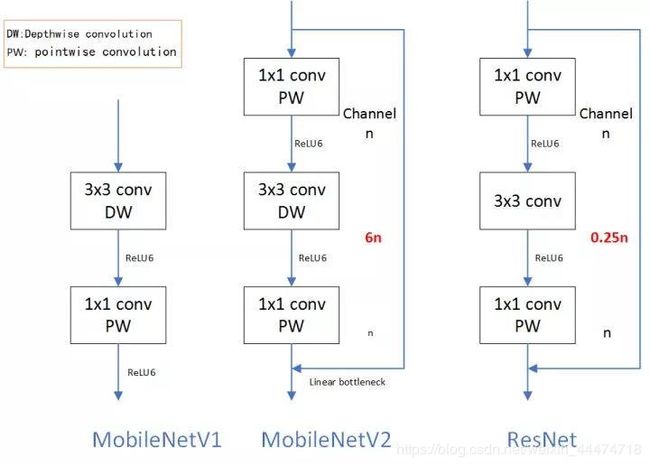
可以看到 MobileNetV2 和 ResNet 基本结构很相似。不过 ResNet 是先降维(0.25 倍)、提特征、再升维。而 MobileNetV2 则是先升维(6 倍)、提特征、再降维。
2.4 总结
MobileNetV2最难理解的其实是 Linear Bottlenecks,论文中用很多公式表达这个思想,但是实现上非常简单,就是在 MobileNetV2 微结构中第二个 PW 后无 ReLU6。对于低维空间而言,进行线性映射会保存特征,而非线性映射会破坏特征。
三、MobileNetV3
3.1 高效的网络构建模块
MobileNetV3 是神经架构搜索得到的模型,其内部使用的模块继承自:
- MobileNetV1 模型引入的深度可分离卷积(depthwise separable convolutions);
- MobileNetV2 模型引入的具有线性瓶颈的倒残差结构(the inverted residual with linear bottleneck);
- MnasNet 模型引入的基于squeeze and excitation结构的轻量级注意力模型。
这些被证明行之有效的用于移动端网络设计的模块是搭建MobileNetV3的积木。
3.2 互补搜索
在网络结构搜索中,作者结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt,前者用于在计算和参数量受限的前提下搜索网络的各个模块,所以称之为模块级的搜索(Block-wise Search) ,后者用于对各个模块确定之后网络层的微调。
这两项技术分别来自论文:
M. Tan, B. Chen, R. Pang, V. Vasudevan, and Q. V. Le. Mnasnet: Platform-aware neural architecture search for mobile. CoRR, abs/1807.11626, 2018.
T. Yang, A. G. Howard, B. Chen, X. Zhang, A. Go, M. Sandler, V. Sze, and H. Adam. Netadapt: Platform-aware neural network adaptation for mobile applications. In ECCV, 2018
前者相当于整体结构搜索,后者相当于局部搜索,两者互为补充。
3.3 网络改进
作者们发现MobileNetV2 网络端部最后阶段的计算量很大,重新设计了这一部分,如下图:
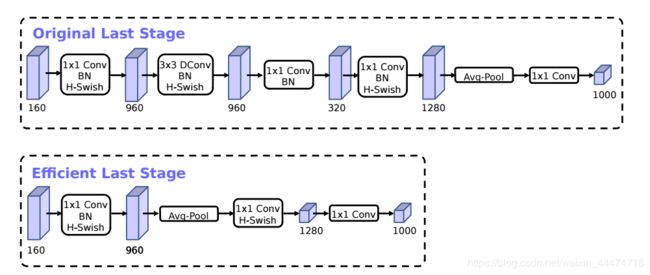
这样做并不会造成精度损失。
另外,作者发现一种新出的激活函数swish x 能有效改进网络精度:
![]()
但就是计算量太大了。
于是作者对这个函数进行了数值近似:

事实证明,这个近似很有效:

从图形上看出,这两个函数的确很接近。
3.4 MobileNetV3 网络结构!
使用上述搜索机制和网络改进,最终谷歌得到的模型是这样(分别是MobileNetV3-Large和MobileNetV3-Small):
图见原文。
内部各个模块的类型和参数均已列出。
谷歌没有公布用了多少时间搜索训练。
目前谷歌还没有公布MobileNetV3的预训练模型,不过读者可以按照上述结构构建网络在ImageNet上训练得到权重。
四、总结(神经架构搜索火了)
MobileNetV3-Large在ImageNet分类上的准确度与MobileNetV2相比提高了3.2%,同时延迟降低了15%。
MobileNetV3-large 用于目标检测,在COCO数据集上检测精度与MobileNetV2大致相同,但速度提高了25%。
在Cityscapes语义分割任务中,新设计的模型MobileNetV3-Large LR-ASPP 与 MobileNetV2 R-ASPP分割精度近似,但快30%。