基于《Kaldi语音识别》技术及开源语音语料库分享
前言:
数据堂自AI开源计划发起,面向高校和科研机构首次开源的【1505小时中文普通话语音数据集】,该数据集句标注准确率达到了98%,得到了很多开发者的认可。
不仅如此,数据堂基于此开源数据集还精选出了【200小时中文普通话语音数据】同期发布,并提供了基于Kaldi【200小时中文普通话语音数据】训练方法。该训练方法同时得到了广泛的关注及开发者的极度认可,并表示希望数据堂持续分享相关技术。
日前,数据堂AI开放实验室发起基于《Kaldi语音识别》技术的分享会,分享会也一同邀请到了北印和北工商实验室的同学参加。
分享会上,数据堂AI开放实验室语音识别数据处理技术研究同事详细的讲解了语音识别技术、语音识别引擎框架、开源语音语料库、算法归纳、模型训练实战演示、语音识别技术未来的挑战。
以下为分享会主要内容回顾:
一、语音识别技术
1.1什么是语音识别ASR (Automatic Speech Recognition)
声波蕴含了更为丰富的信息,比如说话人性别、口音、年龄、情感等,语音识别即让机器把语音信号转变为相应的文本,进而达到机器自动识别和理解语音内容。输入一段随时间播放的信号序列,输出对应的一段文本序列。
 ——基本流程——
——基本流程——
1.2语音识别技术的应用
语音识别作为一种基础层感知类技术,既可以作为核心技术直接应用于终端产品,也可以仅作为一种感知类辅助技术集成于语音助手、车载系统、智慧医疗、智慧法院等场景的产品中。

——语音识别应用——
1.3语音识别数据处理技术
1.3.1信号预处理
信号预处理包括:滤波与采样、预加重、端点检测、分帧、加窗。
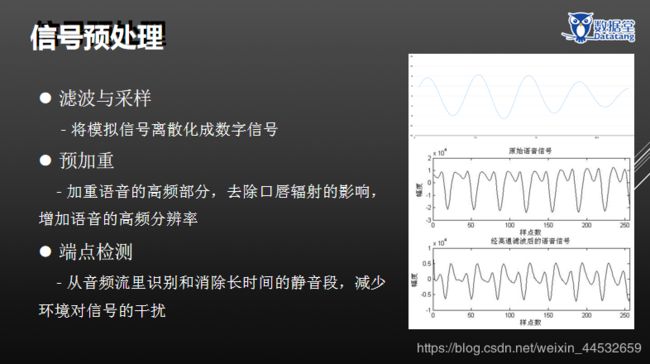
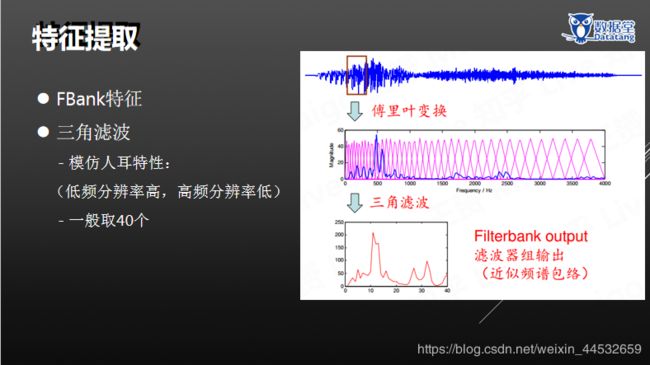
1.3.2特征提取
包括:常用特征(MFCC、Fbank、pitch)、时频转换、共振峰/包络——MFCC、基音周期/精细结构——pitch、 FBank特征 、三角滤波、MFCC特征、特征压缩、一段语音信号、滑动窗口、语谱图等。



1.3.3解码
包含:声学模型(AM)、语言模型(LM)、词典(Lexicon)、解码器(Decoder)、 维特比算法、词图(lattice)。



1.3.3评价指标
包含:词错误率(Word Error Rate,WER)、字错误率(Character Error Rate,CER)、音素错误率(Phone Error Rate,PER)、句错误率(Sentence Error Rate,SER)。
例如:词错误率(Word Error Rate,WER)
-将标准答案与识别结果对齐
- 用插入、删除、替换错误的总数除以 标准答案的长度
- 标准答案:too young too simple sometimes naïve
- 识别结果: too young simple some times knife
- 错误: 删除 替换 插入 替换
- WER:4 / 6 = 66.7%
二、语音识别引擎框架

2.1 Hidden Markov Toolkit
Hidden Markov Toolkit由剑桥大学开发的早期经典的语音识别工具包,最早开发于1989年,使用C语言编写,代码和功能非常稳定,集成了最主流的语音识别技术,具有相对完善的文档手册HTK Book。
缺点:更新相对缓慢,缺乏易用的脚本系统,不方便上手
2.2 Microsoft Cognitive Toolkit
微软公司开发的工具箱,开源于2015年, 强大的神经网络功能,定位于多种问题的组合,比如机器翻译+语音识别,是工具包中对Windows平台支持最好的。
缺点:不是完全专业的语音识别工具,需要配合Kaldi等工具使用, 在持续的优化和更新中
2.3 CMU Sphinx
CMU Sphinx由卡内基梅隆大学开发,在Github和SourceForge平台同步更新,至今也有20多年的历史了, 有C和Java两个版本,文档简单易读,贴近实践操作,适合做开发。
缺点:在Github上只有一个管理员维护,其他杂项处理程序(如pitch提取)没有kaldi丰富。
2.4 KAIDI
有全套的语音识别工具,由Dan Povey博士和捷克的BUT大学联合开发,最早发布于2011年,底层代码使用C++编写,接口采用shell和python,覆盖了统计模型和深度学习方法,灵活代码,易于扩展,开发者更为活跃。
缺点:由于贡献者比较多,所以会有不稳定或有问题的代码更新
三、开源语音语料库

3.1 LibriSpeech
当前衡量语音识别技术的最权威主流的开源数据集
1000小时英语有声读物

Librispeech: An ASR corpus based on public domain audio books
http://www.openslr.org/11/
3.2 牛津大学:VoxCeleb
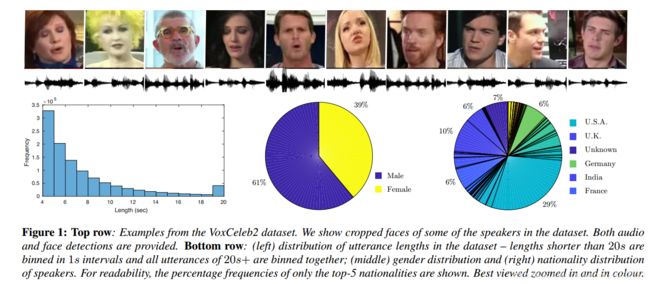

VoxCeleb2: Deep Speaker Recognition 2018 VoxCeleb
3.3 清华大学:Thchs-30
时长30多小时,16kHz,16bits;安静室内,单麦克风;
设计目的:
- 增广863数据集(2001年,TCMSD)
- 提供语音识别基准实验

THCHS-30 : A Free Chinese Speech Corpus 2015 THCHS-30
3.4 数据堂:aidatatang_1505zh
时长1505小时,16kHz,16bits
安静室内或低噪室外,手机设备
采集区域覆盖全国34个省级行政区域
参与录音人数达6408人
录音内容超30万条口语化句子
标注准确率超过98%
数据堂1505小时中文普通话数据集
www.datatang.com
3.5 数据堂:aidatatang_200zh
时长200小时,16kHz,16bits
安静室内或低噪室外,手机设备
600位来自不同地区的说话人
标注准确率超过98%
训练集:验证集:测试集 = 7:1:2


http://www.openslr.org/62/

https://github.com/datatang-ailab/aidatatang_200zh

https://github.com/kaldi-asr/kaldi/tree/master/egs/aidatatang_200zh
3.6 其他

AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline
CommonVoice数据集 Primewords
四、算法归纳
4.1 算法归纳
统计学习模型
- 在1990年~2010年,GMM-HMM长期主导着语音识别的框架
统计-深度学习混合模型
- 在2011年~2014年,DNN-HMM成为声学模型的主流框架
端到端深度学习模型
-从2015年至今,RNN、注意力模型、记忆网络、CTC等模型又掀起了第三次浪潮
-几乎所有语音研究都已转向深度学习
4.1.1 GMM-HMM
高斯混合模型-隐马尔科夫模型
模型参数:
- 转移概率
- 观测概率(GMM)
模型特点:
- 隐藏状态为发音音素,观察值为语音特征
- 马尔科夫性:状态转移概率与观测概率都仅与当前状态有关

三大问题:
- 求值:给定模型参数和语音数据,求P(语音|模型) —— 前向后向算法
- 解码:给定模型参数和语音,求最佳对齐方式 —— 维特比算法
- 训练:给定语音和模型结构,求模型参数 —— EM算法
a. 采用均匀分割方式生成初始对齐结果
b. 由此求出模型参数(M步)
c. 更新对齐方式(E步)
d. 循环直至收敛
训练方式:MLE,最大似然估计法
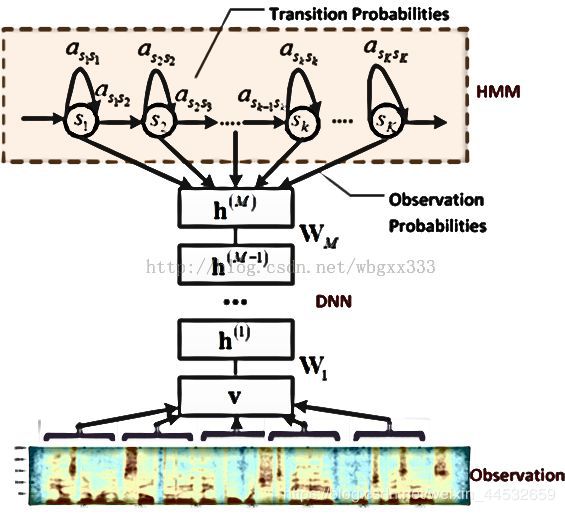
4.1.2 DNN-HMM
深度神经网络-隐马尔科夫模型
前馈神经网络
采用DNN替换GMM模型对语音的观察概率建模
特点:
- DNN的输入特征为滤波器组输出
- DNN不需要对语音数据分布进行假设
- DNN输入连续相邻语音帧以上下文建模
4.1.3 TDNN
时延神经网络
最早基于CNN的语音识别方法
沿着频率轴和时间轴同时进行卷积,能利用可变长度的语境信息
由于HMM能够处理可变长度表述问题,因此该模型能有效处理LVCSR问题
对隐层也做了上下文扩展
权重共享
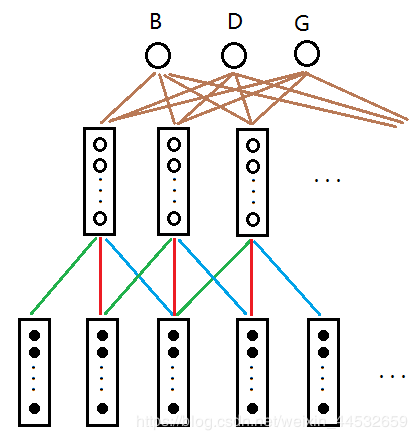
4.1.4 DFCNN
全序列卷积神经网络
科大讯飞于2016年提出
将语谱图看做带有特定模式的图像,而有经验的语音学家能够从中看出语音内容。

4.1.5 LSTM
具有长短时记忆能力
更加契合时序建模问题
缓解了RNN的梯度消散和梯度爆炸问题
计算复杂度增加,难以并行
BLSTM
- 还考虑了反向时序信息的影响,模型具有更好的建模能力
- 复杂度进一步加大,实时性差
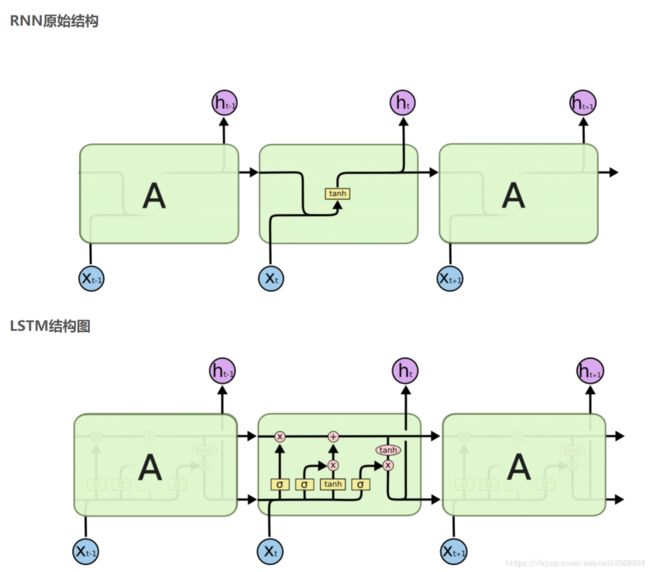
4.1.6 CTC
不再进行逐帧判别
- 大部分帧输出为空,小部分帧输出为音素
- 只要求输出音素串与标答相同,不要求位置
目标函数:所有能缩成标答音素串的输出的总概率
舍弃了HMM

4.1.7 Chain Model
链式模型
- 低帧率输出:DNN每三帧输出一次,解码速度更快
- 优化后的HMM拓扑结构:使用单状态的biphone,建模粒度更大
- 改进了MMI,提出了LF-MMI训练方法,训练速度更快
- 使用区分性训练,准确度更高
相较于主流的交叉熵,Chain Model搭配TDNN,在语音识别系统的准确率和解码速度上都有显著提高。
五、深度实战

5.1 单音子HMM训练
1.初始化单音素系统(快速启动,利用少量数据快速得到一个初始化的HMM-GMM模型和决策树)

2.构造训练网络,对每个句子构造一个phone level的fst网络,输入是音素,输出是整个句子

3.对每一个训练特征做均匀对齐,根据标注数目对特征序列进行等间隔切分;
根据对齐信息,获得HMM和GMM训练相关的统计量。
根据得到的统计量,更新每个GMM模型。


4.迭代更新模型

5.2 与上下文相关的三音素HMM训练
1.计算决策树统计量

2.生成问题集

3.生成决策树

4.三音素模型初始化

5.将单音素的对齐转换成三音素的对齐

6.三音素模型训练

5.3 线性判别分析和最大似然线性变换模型训练
MFCC—》 CMVN —》Splice —》 LDA—》 MLLT—》final.mat
1.生成先验概率,统计计算LDA计算所需统计量

2.估计LDA矩阵
![]()
3.通过对转换后的特征重新估计,用于生成决策树

4.三音素绑定、决策树三音素聚类、生成决策树

5.用转换后的特征重新训练GMM
6.计算MLLT的统计量,更新MLLT矩阵T

5.4 说话人自适应模型训练
Kaldi的特征空间变换方法: LDA、MLLT和fMLLR,其本质都是在训练过程中估计变换矩阵,然后构造变换后的特征,再迭代训练新的声学模型参数。
LDA+MLLT针对环境特性,拼接上下文多帧数据,再通过特征变换进行降维处理,因为与说话人无关,所以估计的是全局矩阵。
fMLLR针对说话人特性,基于每个说话人或每条语句进行变换矩阵估计。

5.5 TDNN模型训练
特征:
- 高分辨率MFCC+online pitch特征
- ivector特征:表征说话人和环境
数据增广:
- 对训练数据进行3种速度变换:0.9, 1.0, 1.1
网络结构:
输入层:100维ivector特征,43维mfcc+pitch特征
TDNN隐层:6层,分别具有不同的时延长度
输出层:决策树叶子个数,本例为2952
5.6 Chain+TDNN模型训练
-
iVector计算和特征提取部分与基准TDNN处理相同
-
LF-MMI(Lattice-Free Maximum Mutual Information)训练
-
生成更简单的HMM拓扑结构
-
根据新的拓扑结构生成决策树
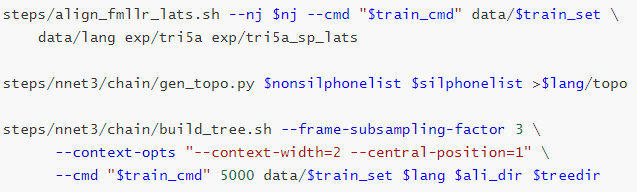
5.7 实验结果

六、未来挑战

以上是此次数据堂 基于《Kaldi语音识别》技术及开源语音语料库分享会上的主要内容,共六章内容:语音识别技术、语音识别引擎框架、开源语音语料库、算法归纳、模型训练实战演示、语音识别技术未来的挑战。
分享人:数据堂AI-Lab——王丽媛
原文链接:https://www.datatang.com/news/info/laboratory/203
本文已整理为pdf文件,需要的请私信联系。