爬虫实例-----用scrapy框架和xpath爬取豆瓣多页面电影信息
同类链接:爬虫实例-----用请求的框架和XPath的爬取道琼斯指数信息并保存为CSV文件
所需环境:python3.7
Scrapy引擎(引擎):负责蜘蛛,ItemPipeline,下载,调度中间的通
讯,信号,数据传递等
调度器(调度器):它负责接受引擎发送过来的请求请求,并按照一定的方式进行整
作者:个结果排列, 。入队,当引擎需要时,交还给引擎
下载(下载器):负责下载Scrapy引擎(引擎)发送的所有请求请求,并
将其电子杂志到的响应交还给Scrapy引擎(引擎),由引擎交给蜘蛛来处理,
蜘蛛(爬虫):它负责处理所有的反应,从中分析提取数据,获取项目需要字段数的
据,并将需要跟进的网址提交给引擎,再次进入调度器(调度器),
项目管道(管道):它负责处理蜘蛛中获取到的项目,并进行进行后期处理(分详细
析,过滤,存储等)的地方。
下载中间件(下载中间件):一个可以自定义扩展下载功能的组件。
蜘蛛中间件(蜘蛛中间件):可以扩展操作引擎和蜘蛛通信中间的功能组
件
制作Scrapy爬虫步骤
1.新建项目(scrapy startproject xxx):新建一个新的爬虫项目
2。明确目标(编写items.py):明确你想要抓取的目标
3。制作爬虫(spiders / xxspider.py):制作爬虫开始爬取网页
4。存储内容(pipelines.py):设计管道存储爬取内容
安装配置
Windows平台
pip install --upgrade pip
pip install twisted
pip install lxml
pip pywin32
pip install Scrapy
- 注意:一定安装scrapy的依赖库,否则可能会遇到诸多错误:
- Scrapy错误:需要Microsoft Visual C ++ 10.0。
- lxml的构建轮失败
- 建筑扭曲失败
- 无法找到vcvarsall.bat
Ubuntu平台
安装非Python的依赖
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev
libffi-dev libssl-dev
安装Scrapy框架
pip install --upgrade pip
sudo pip install scrapy
创建项目:
进入配置好的虚拟环境中,输入程序pycharm和cmd都行,下面用pycharm举例说明
#scrapy startproject +项目名
scrapy startproject DouBanSpider

目录结构:
scrapy.cfg:项目的配置文件DouBan
/:项目的Python模块,将会从这里引用代码
DouBan /items.py:项目的目标文件
DouBan /pipelines.py:项目的管道文件DouBan
/settings.py :项目的设置文件
DouBan / spiders /:存储爬虫代码目录
DouBan / middlewares /:中间件
DouBan / pipelines /:项目爬取信息的保存
其中run.py需要自己手动创建

创建爬虫:DouBanProject.py

首先分析网站链接:
'https://movie.douban.com/top250?start=0&filter='#第一页:
'https://movie.douban.com/top250?start=25&filter='#第二页:
'https://movie.douban.com/top250?start=50&filter='#第三页:
发现每页在start = 0处不同,每页变化25,所以可以确定起始url为:
list = [] # 空列表,存储多个起始url ,进行多页面爬取
for page in range(0, 226, 25): # 0, 226 爬取第一页到第46页数据, 每次切换25
url = 'start=' + str(page) + '&filter=' # 进行url更改,实现页面切换
start_urls = 'https://movie.douban.com/top250?' + url # 进行url拼接
list.append(start_urls) #将url存入list列表
start_urls = list # 将list列表赋值给start_urls, 所有的url都在start_urls里,名字不可更改其次进入要爬取的网页查看源码,找到精准定位准备爬取信息

DouBanProject.py全部代码
# -*- coding: utf-8 -*-
import scrapy
from items import DoubanItem
# from DouBan.items import DoubanItem # 定位更精确,上行代码报错可以尝试用这行代码
class DoubanprojectSpider(scrapy.Spider):
name = 'DouBanProject'
allowed_domains = ['douban.com']
# start_urls = ['https://movie.douban.com/top250?start=0&filter=']
list = []
for page in range(0, 226, 25):
url = 'start=' + str(page) + '&filter='
start_urls = 'https://movie.douban.com/top250?' + url
list.append(start_urls)
start_urls = list
# 定位需要信息的范围,整体div块,下载这部分源码,方便下面进行具体的爬取
def parse(self, response):
movelist = response.xpath("//div[@class='article']/ol[@class='grid_view']/li")
print(len(movelist))
item = DoubanItem()
for each in movelist:
# 爬取电影名
name = each.xpath('./div[@class="item"]/div[@class="info"]/div/a/span/text()').extract()[0]
# 爬取综合评分
score = each.xpath('./div[@class="item"]/div[@class="info"]/div/div/span[@class="rating_num"]/text()').extract()[0]
print(name)
print("==============================")
print(score)
item["name"] = name
item["score"] = score
yield item
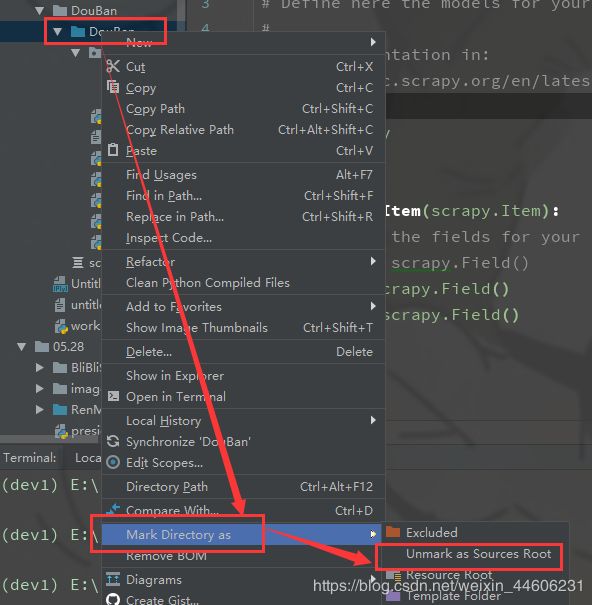
如果从项目导入DoubanItem报错则可以尝试修改根目录文件夹,如下图所示:
修改后文件夹变为蓝色
items.py全部代码
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
score = scrapy.Field()
pipelines.py全部代码
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import csv
class DoubanPipeline(object):
def __init__(self):
print("初始化")
self.file = codecs.open('DouBan.csv', 'w', 'utf-8')
self.wr = csv.writer(self.file, dialect='excel')
self.wr.writerow(['name', 'score'])
def process_item(self, item, spider):
print("获取电影名", item['name'])
print("获取电影评分", item['score'])
self.wr.writerow([item['name'], item['score']])
return item
def close_spider(self, spider):
print("关闭DouBan")
self.file.close()
run.py全部代码
"""编写爬虫爬取豆瓣电影排行榜(电影名称,评分),保存为csv文件"""
from scrapy import cmdline
name = "DouBanProject" # 不同的项目修改名字即可
# cmd = "scrapy crawl {0}".format(name)
cmd = "scrapy crawl DouBanProject"
cmdline.execute(cmd.split())setting.py部分代码
ROBOTSTXT_OBEY = False #机器人协议,把True改为False,不遵守协议,否则很多网站信息无法爬取
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
# UA头自己设置,随便进入一个网站F12源码都可以查看UA头,反反扒需要修改UA头
}
SPIDER_MIDDLEWARES = {
'DouBan.middlewares.DoubanSpiderMiddleware': 543, # 中间件 自定义中间件时需要打开
}
DOWNLOADER_MIDDLEWARES = {
'DouBan.middlewares.DoubanDownloaderMiddleware': 543, # 下载图片需要打开,配合最底部几行代码同时使用
}
ITEM_PIPELINES = {
'DouBan.pipelines.DoubanPipeline': 300, # 下载文件到本地需要打开
}
# 保存图片使用,自己设置添加代码
IMAGES_STORE = "./Image"
IMAGES_THUMBS = {
"big": (100, 100),
"small": (50, 50),
}