Hadoop-MapReduce
Hadoop-MapReduce
- 为什么要使用MapReduce
- 实战篇
- 程序运行模式
- 本地模式
- 集群运行模式
- eclipse提交到集群
- wordCount
- 线段的重合点次数
- 数据去重
- 流量求和
- 共同好友
- 倒排索引
- 求平均值
- 分组求topn
- join篇
- 优化篇
- combiner
- 数据倾斜之数据打散
- 原理篇
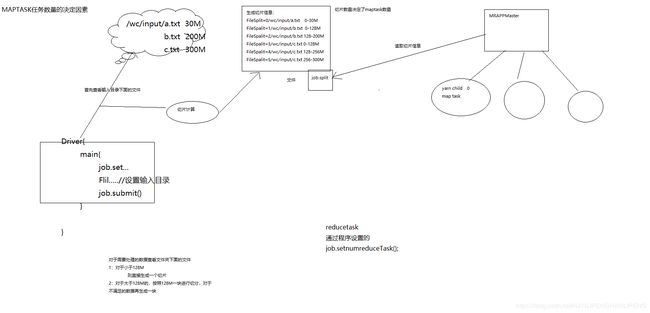
- 数据切块
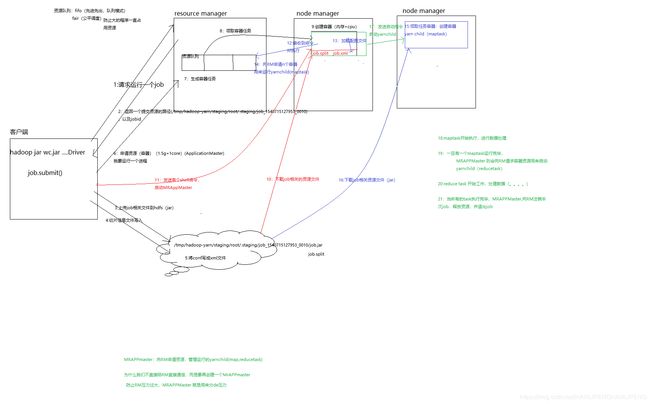
- YARN集群运行流程
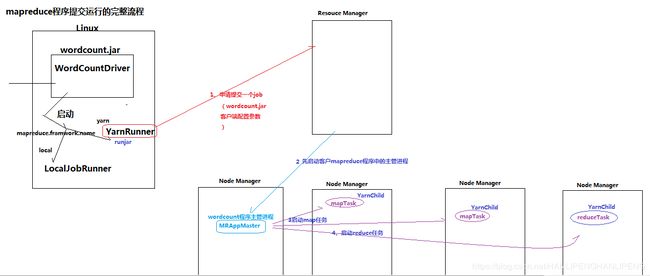
- 完整的任务流程
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;用户不需要考虑分布式的代码。
为什么要使用MapReduce
- 海量数据在单机上处理因为硬件资源限制,无法胜任
- 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
- 引入mapreduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理。
- 自己实现分布式计算会出现大量的公共代码,这些代码会影响开发进度。
实战篇
程序运行模式
本地模式
- mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行
- 而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
- 怎样实现本地运行?写一个程序,不要带集群的配置文件(本质是你的mr程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname参数)
- 本地模式非常便于进行业务逻辑的debug,只要在eclipse中打断点即可
如果在windows下想运行本地模式来测试程序逻辑 ,需要在windows中配置环境变量:
%HADOOP_HOME% = d:/hadoop-2.7.3
%PATH% = %HADOOP_HOME%\bin
并且要将d:/hadoop-2.8.3的lib和bin目录替换成windows平台编译的版本
注意:集群需要进行时间同步,时间差别比较大的时候提交任务的时候会报时间不同步异常
集群运行模式
- 将mapreduce程序提交给yarn集群resourcemanager,分发到很多的节点上并发执行
- 处理的数据和输出结果应该位于hdfs文件系统
- 提交集群的实现步骤:
A、将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
$ hadoop jar wordcount.jar cn.xiaoniu.bigdata.mrsimple.WordCountDriver inputpath outputpath
B、直接在linux的eclipse中运行main方法
(项目中要带参数:mapreduce.framework.name=yarn以及yarn的两个基本配置)
eclipse提交到集群
//配置
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://bigdata01:9000");
conf.set("mapreduce.framework.name","yarn");
conf.set("yarn.resourcemanager.hostname", "bigdata01");
conf.set("mapreduce.app-submission.cross-platform", "true");
wordCount
线段的重合点次数
数据:
1,4
2,5
3,4
2,5
2,4
3,4
2,6
1,4
4,7
5,8
5,9
6,11
7,12
6,10
10,15
11,16
12,18
13,17
需求:
求出这些线段的重合点
数据去重
数据:
134 1341307 广东 惠州 移动 516000 0752 441300
134 1341308 广东 惠州 移动 516000 0752 441300
134 1341309 广东 惠州 移动 516000 0752 441300
134 1341310 广东 惠州 移动 516000 0752 441300
134 1341311 广东 惠州 移动 516000 0752 441300
134 1341312 广东 惠州 移动 516000 0752 441300
134 1341313 广东 惠州 移动 516000 0752 441300
需求:
求取出以上数据手机号前三位以及对应的运营商
流量求和
数据:
15639120688 http://v.baidu.com/movie 3936 12058
13905256439 http://movie.youku.com 10132 538
15192566948 https://image.baidu.com 19789 5238
14542296218 http://v.baidu.com/tv 7504 13253
需求:求取网站流量的上行流量和下行流量,以及总流量
共同好友
数据:
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
需求:求取共同好友
倒排索引
数据:多个文件
a.txt
hello hi…
b.txt
hello java ….
c.txt
hi java Hadoop….
结果
hello -> a.txt 5 b.txt 2 c.txt 1
java -> b.txt 3 c.txt 5
获取文件名的代码:
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String fileName = fileSplit.getPath().getName();
求平均值
数据:
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
需求:
每个电影的得分的平均值
分组求topn
数据同上:
需求:每个电影的评分的前20个数据
需求:求平均值比较高的前20个
join篇
map端的join和reducejoin
优化篇
combiner
数据倾斜之数据打散
原理篇
数据切块
YARN集群运行流程
完整的任务流程

本文由鹏鹏出品
更多文章请访问韩利鹏的博客