R语言——googleplaystore数据和googleplaystore_user_reviews数据描述性统计分析
一、Googleplaystore数据:
这组数据集提供了13个变量——App的名称、Category(分类)、Rating(评分)、Reviews(评论数)、Size(大小)、Installs(下载量)、Type(免费还是付费)、Price(价格)、Content.Rating(内容评级)、Genres(风格)、Last.updated(最近一次更新的时间)、Current.Ver(目前的版本)、Android.Ver(安卓的版本)
其中定类变量为:Category、Type、Content.Rating、Genres。
定序变量为:Rating、Reviews、Size、Installs、Price。
数据预处理:
data<-read.csv("C://Users//Administrator//Desktop//2.csv",na.strings=c("NA","","NAN","NaN"))
#仅保留type中free和paid的数据
a<-which(data$Type!="Free" & data$Type!="Paid")
data=data[-a,]
#判别数据中哪些变量存在缺失值
which(is.na(data$Android.Ver)==TRUE)
#发现Rating、Type、Content Rating、Current Ver、Android Ver含有缺失值
#去除App重复数据
data=data[!duplicated(data[,1]),]
#去除缺失数据
data=na.omit(data)
#将installs中的+,去除
Installs<-gsub("[^[:alnum:]///' ]", "", data[,6])
data=data[,-6]
#将szie中存在'Varies with device',‘M’去除;k在excel中去除并已单位统一
Size<-gsub("[M]", "", data[,5])
Size<-gsub("[Varies with device]", "", Size)
data=data[,-5]
#‘Price'中存在'$',需要去除
Price=gsub("[$]","",data[,6])
data=data[,-6]
#整合数据
da=cbind(data,Installs,Size,Price)
描述性统计并绘图
其中定类变量为:Category、Type、Content.Rating、Genres。
定序变量为:Rating、Reviews、Size、Installs、Price。
【注:游戏版本根据各游戏发布时间有差异,因此不做分析】
(1)先将所有的定序变量做交互分析,寻找数据可能存在的关系
#将变量转换为数值型
Rating=as.numeric(as.character(da$Rating))
Size=as.numeric(as.character(da$Size))
Price=as.numeric(as.character(da$Price))
Reviews=as.numeric(as.character(da$Reviews))
Installs=as.numeric(as.character(da$Installs))
da2=cbind(Rating,Size,Price,Reviews,Installs)
library(corrplot)
da2_cor<-cor(da2)
col3 <- colorRampPalette(c("blue", "white", "red")) #自定义指定梯度颜色
cor.plot <- corrplot(corr = da2_cor,col=col3(10),type="upper",tl.pos="d",tl.cex = 0.75) #画右上方 方法默认“圆形“
cor.plot <- corrplot(corr = da2_cor,add=TRUE, type="lower",col=col3(10),method="color",addCoef.col="black",diag=FALSE,tl.pos="n", cl.pos="n",number.cex = 0.7) #画左下方 方法 “颜色”
得到交互分析图为

可以看出定序变量之间存在一定的相关性。
(2)Google Play Store各类型的app占比:
首先将处理后的数据导出为excel,在excel中,把类型变量中不合适名称的删除。(这一步用R怎么处理我暂时不会,请教大家了)
write.csv(da,"C://Users//Administrator//Desktop//22.csv",row.names = FALSE)
library(readxl)
dataa=read_excel("C://Users//Administrator//Desktop//hhhh.xlsx")
dataa=data.frame(dataa)
library(ggplot2)
dataa = dataa[order(dataa$数量, decreasing = TRUE),] ## 用 order() 让数据框的数据按 A 列数据从大到小排序
myLabel = as.vector(dataa$名字)
myLabel = paste(myLabel, "(", round(dataa$数量 / sum(dataa$数量) * 100, 2), "%) ", sep = "")
p = ggplot(dataa, aes(x = "", y = dataa$数量, fill = dataa$名字)) +
geom_bar(stat = "identity", width = 1) +
coord_polar(theta = "y") +
labs(x = "", y = "", title = "") +
theme(axis.ticks = element_blank()) +
theme(legend.title = element_blank(), legend.position = "top") +
scale_fill_discrete(breaks = dataa$名字, labels = myLabel)
p
图为
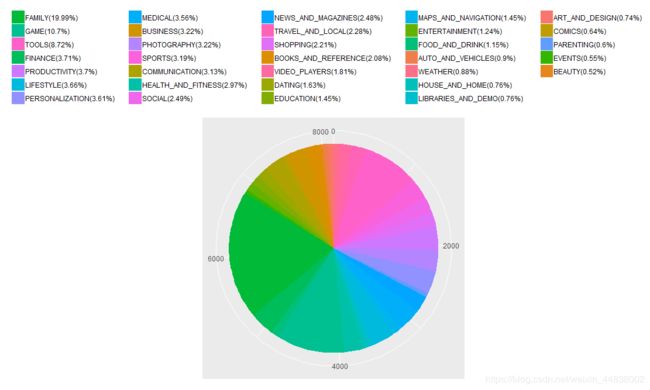
可以看出占据市场份额前五名分别为家庭类、游戏类、工具类、商业类、生产类。
(3)App的评分概览:
接下来对rating(评分)进行分析,首先要去除rating为空值的数据,并结合下载量、评论数、对应人群进行分析。
hist(Rating, breaks=12,col="pink",xlab="Rating")
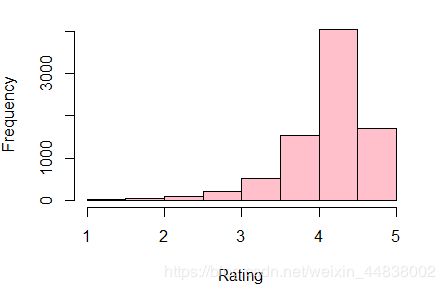
由图可知,大多数app的评分集中在4-5,且平均分为4.17。
(4)为了看每一类型的评分与总评分是否有差异,我们做单因素方差分析
Category=as.character(da$Category)
fit <- aov(Rating ~ Category)
summary(fit)
由于p值<2e-16,结果显示不同类别的app评分分布具有显著差异。
(5)对app大小与评分进行分析
library(ggplot2)
b=cbind(Rating,Size)
b=data.frame(b)
ggplot(b, aes(x = b$Size, y =b$Rating )) +
geom_point()
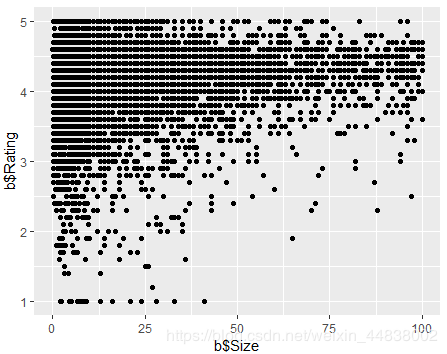
可以发现大部分高分app的内存在2~40MB之间,即不太小也不太大。
(6)接着分析app类型与app内存之间的关系
data1=read_excel("C://Users//Administrator//Desktop//hhh.xlsx")#该数据中只有种类、评分和内存
ggplot(data1, aes(x = data1$Rating, y = data1$Size, colour = data1$Category)) +
# 散点图函数
geom_point()
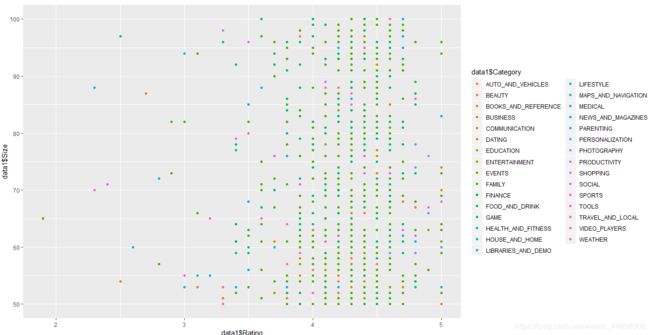 由 图中可知,内存大的apps (> 50MB)属于游戏和家庭类别。并且这些apps的评分相当高,这表明它们内置的功能很丰富。
由 图中可知,内存大的apps (> 50MB)属于游戏和家庭类别。并且这些apps的评分相当高,这表明它们内置的功能很丰富。
(7)分析app选取的价格策略
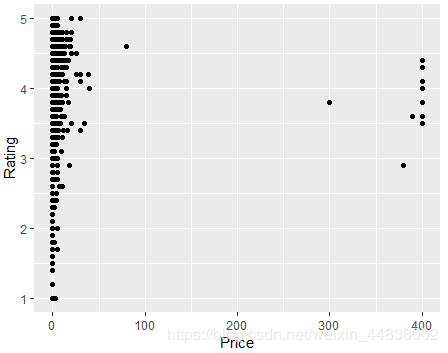
大多数高分app的价格在1~30美元之间,定价超过20的app很少。
(8)将视角转向付费市场,分析不同付费app之间是否有差异
data2=read_excel("C://Users//Administrator//Desktop//hh.xlsx")#该数据中的app均为付费app
ggplot(data2, aes(x = data2$Rating, y = data2$Size),colour=blue) +
# 散点图函数
geom_point()
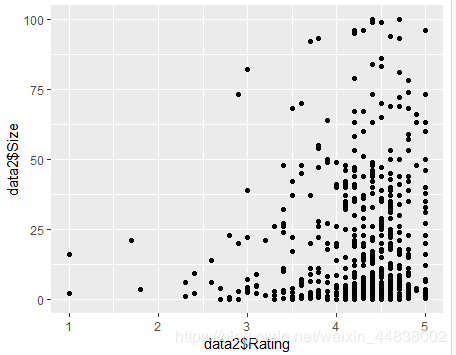
可知大多数高分、付费app占内存很小。这说明大多数付费app是“小而美”的,专注于特定的功能。并且用户更愿意为轻量级的app付费。内存过大的app可能在付费市场中表现不佳。
(9)分析评论数和下载量之间的关系
cor(Reviews,Installs)
评论数和下载量之间存在0.63的中度正相关。这意味越多的人对这个app给出意见,用户越倾向于下载这个app。
总结以上分析,得到以下结论:
1)Google Play Store中app的平均评分为4.17。
2)用户更愿意为内存较小的app付费。大多数高评价app的最佳大小在2MB到40MB之间,既不太大也不太小。
3)大多数评价最高的app的价格介于1~30美元之间-既不太贵也不太便宜。医疗和家庭app是最昂贵的。
4)用户更倾向于下载评论多的app,评论能够促进下载量的提升。
二、Googleplaystore_user_reviews数据
该数据主要分析用户的评论,该数据集提供了5个变量,即APP、Translated_Review(评论)、Sentiment(情感)、Sentiment_Polarity(情绪分级)、Sentiment_Subjectivity(情感主体)
首先清洗数据
dt=read.csv("C://Users//Administrator//Desktop//3.csv",na.strings=c("NA","","NAN","NaN","nan"))
dt=dt[which(is.na(dt$App)==FALSE),]
dt=dt[which(is.na(dt$Translated_Review)==FALSE),]
dt=dt[which(is.na(dt$Sentiment)==FALSE),]
dt=dt[which(is.na(dt$Sentiment_Polarity)==FALSE),]
dt=dt[which(is.na(dt$Sentiment_Subjectivity)==FALSE),]
#将Sentiment中与Positive、Neutral、Negative无关的数据删除
a<-which(dt$Sentiment!="Positive" & dt$Sentiment!="Neutral"& dt$Sentiment!="Negative")
dt=dt[-a,]
write.csv(dt,"C://Users//Administrator//Desktop//h.csv",row.names = FALSE)#将数据读出,并用excel分出好评、中评、差评的数据。
数据描述性统计
(1)绘制好评、差评、中评词云图
dt1=read_excel("C://Users//Administrator//Desktop//positive.xlsx")
#词云图
library(jiebaR)
library(wordcloud2)
review=dt1$Translated_Review
mixseg<-worker(type="mix")
seg<-mixseg[review]#获取分词结果
seg<-seg[nchar(seg)>1] #去除字符长度小于2的词语
num<-table(seg)
reviewp=data.frame(num)
wordcloud2(reviewp)
dt2=read_excel("C://Users//Administrator//Desktop//negative.xlsx")
review1=dt2$Translated_Review
mixseg<-worker(type="mix")
seg<-mixseg[review1]#获取分词结果
seg<-seg[nchar(seg)>1] #去除字符长度小于2的词语
num<-table(seg)
reviewp=data.frame(num)
wordcloud2(reviewp)
dt3=read_excel("C://Users//Administrator//Desktop//neutral.xlsx")
review2=dt3$Translated_Review
mixseg<-worker(type="mix")
seg<-mixseg[review2]#获取分词结果
seg<-seg[nchar(seg)>1] #去除字符长度小于2的词语
num<-table(seg)
reviewp=data.frame(num)
wordcloud2(reviewp)
结果如下:



对比下三张图,可以看到:
跟好评有关的情绪高频词有best,easy,awesome,better,amazing等
跟差评有关的情绪高频词有game,bad,annoying,ads,problem等
跟中评有关的情绪高频词有like,can,want,app等
(2)将数据中的app与googleplaystore数据中的app在excel中查找判断其种类(这一步也不会用R来完成,希望有人指教)。
通过转化成APP占比分析各category中好评,中评,差评的数量多少
dt4=read.csv("C://Users//Administrator//Desktop//h.csv")
library(plyr)
dt4$number <- 1
#占比条形图
dt5 <- ddply(dt4,'Category',transform,percent = 1/sum(number)*100)
ggplot(dt5,aes(Category,percent,fill=Sentiment))+
geom_bar(stat="identity",position="stack")+
ggtitle("")+
theme_bw()+
theme(axis.ticks.length=unit(0.5,'cm'))+
guides(fill=guide_legend(title=NULL))
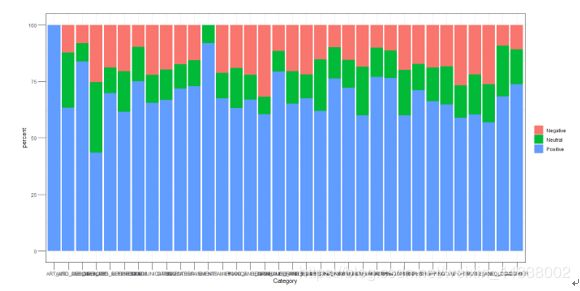
由图可知,好评较高的category有Tools, ,Education, Auto and
vehicles,Commics.