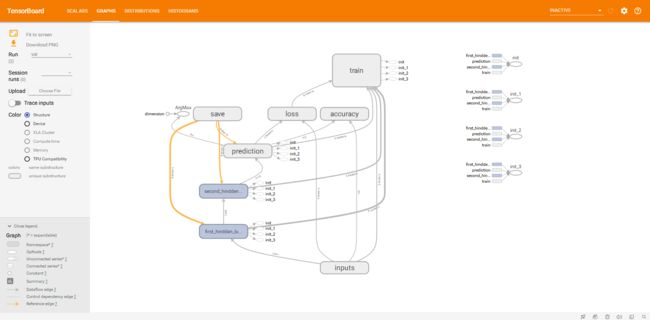
一、什么是tensorboard
让tensor可视化地flow起来。(来来来,让tensor先flow一会。)
二、入门-如何打开
首先,tensorflow自带了tensorboard,不用安装了。其次整体分为两步
- 先在程序中加入语句,跑一遍,生成summary文件。
- 再通过tensorboard打开文件。查看相关数据的变化。
1、添加语句,生成summary文件
- name_scope:命名空间,就是把X_input和y_true打包进inputs这个节点。双击inputs就可以拆包看到里面的X_input和y_true。
# 指定X(输入层)Y(输出层)的大小,占坑
with tf.name_scope("inputs"):
X_input = tf.placeholder(tf.float32, shape = [None, features],name="X_input")
y_true = tf.placeholder(tf.float32, shape = [None, numClasses],name="y_true")
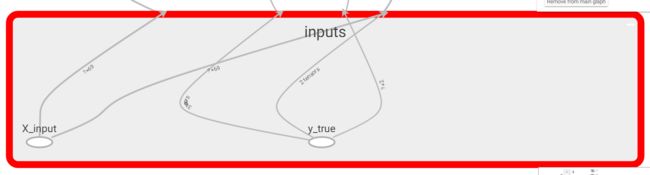
多说一句:有些节点,没有定义,tensorboard也会自动形成节点,智能啊。
- tf.summary.merge_all() 和 tf.summary.FileWriter(留意是在迭代train之前)
sess = tf.Session()
merged = tf.summary.merge_all() #Merges all summaries collected in the default graph.
# 定义训练过程中的参数(比如loss,weight,baises)保存到哪里
writer_val = tf.summary.FileWriter("logs/val", sess.graph)
sess.run(tf.global_variables_initializer())
- add_summary,在迭代训练的时候把参数记录进去(留意是在迭代train过程中),运行后,在目标目录下,会多了一个文件,如下图。
merged_rs, = sess.run(merged, feed_dict = feed_dict)
# 记录参数
writer_val.add_summary(merged_rs, Iterations)

2、再通过tensorboard打开文件
在 logs 所在目录(不用点进去),按住 shift 键,点击右键选择在此处打开cmd
-
在 cmd 中,输入以下命令启动 “tensorboard --logdir=logs”
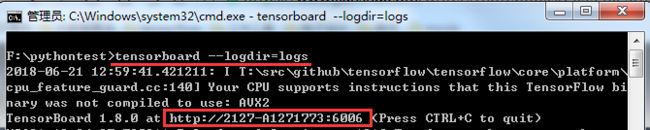 image.png
image.png -
把浏览器中打开http://localhost:6006或者截图中显示的网址即可。
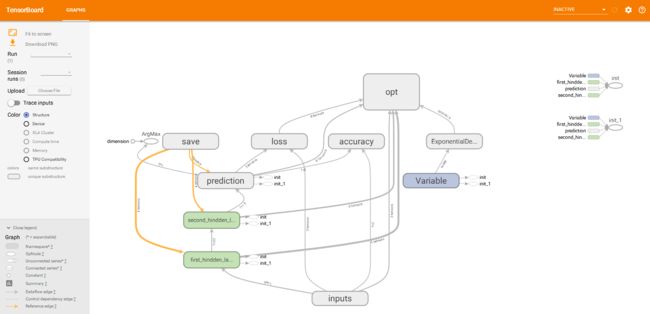 image.png
image.png
tensorboard出来了,tensor终于flow起来了,但是跟封面图片对比找茬,橙色导航栏少了几个按钮,进入下一个环节了。
三、进阶-监控参数
先以监控loss、weights、baises在迭代train中的变化为例介绍一下:
1. 还是要在代码中加入语句进行记录:
- 对loss的记录:除了上文中提及的name_scope,还有tf.summary.scalar('loss',loss)。
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels = y_true, logits = y_prediction))
tf.summary.scalar('loss',loss)
- 对weights和baises的记录,用语句tf.summary.histogram。
with tf.name_scope('weights'):
Weights=tf.Variable(tf.random_normal([in_size,out_size], stddev=0.1),name='W')
tf.summary.histogram('Weights',Weights)
with tf.name_scope('biases'):
biases = tf.Variable(tf.constant(0.1, shape=[out_size]), name='b')
tf.summary.histogram('Biases',biases)
2.运行后的效果
-
tf.summary.scalar('loss',loss)对应的图。漂亮的loss收敛。
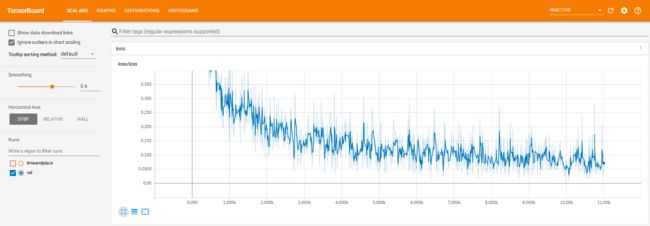 image.png
image.png
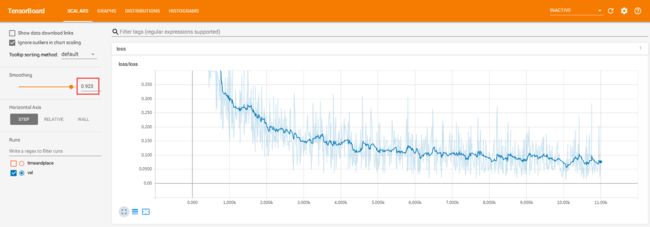 image.png
image.png
-
histogram柱状图:tf.summary.histogram('Weights',Weights)和tf.summary.histogram('Biases',biases)
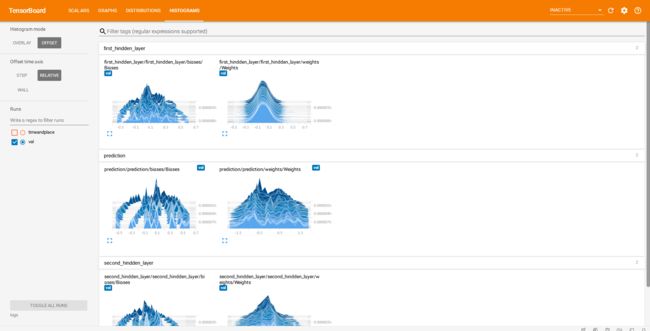 image.png
image.png
四、进阶2-监控内存和训练时间
如果你想看看各个环节在训练过程中使用的内存和消耗的时间,可以用这个看看。
1.还是加入代码先
在原有的基础上,加入writer_timeandplace = tf.summary.FileWriter("logs/timeandplace", sess.graph)
# sess
sess = tf.Session()
merged = tf.summary.merge_all() #Merges all summaries collected in the default graph.
# 定义训练过程中的参数(比如loss,weight,baises)保存到哪里
writer_val = tf.summary.FileWriter("logs/val", sess.graph)
# 保存训练过程中各个环节消耗的时间和内存
writer_timeandplace = tf.summary.FileWriter("logs/timeandplace", sess.graph)
sess.run(tf.global_variables_initializer())
每1000次迭代记录一次,关键语句:
run_options = tf.RunOptions(trace_level = tf.RunOptions.FULL_TRACE) # 配置运行时需要记录的信息
run_metadata = tf.RunMetadata() # 运行时记录运行信息的proto
writer_timeandplace.add_run_metadata(run_metadata, 'Iterations%03d' % Iterations)
# 迭代 必须注意batch_iter是yield→generator,所以for语句有特别
for (batchInput, batchLabels) in batch_iter(X_train_n, y_train_one_hot_n, batchSize, epoch_count, shuffle=True):
if Iterations%1000 == 0:
# --------------------------------训练并纪律-----------------------------------------------
run_options = tf.RunOptions(trace_level = tf.RunOptions.FULL_TRACE) # 配置运行时需要记录的信息
run_metadata = tf.RunMetadata() # 运行时记录运行信息的proto
# train
trainingopt,trainingLoss,merged_rs= sess.run([opt,loss,merged], feed_dict={X_input:batchInput, y_true:batchLabels}, options =run_options, run_metadata = run_metadata)
# 记录参数
writer_val.add_summary(merged_r, Iterations)
# 将节点在运行时的信息写入日志文件
writer_timeandplace.add_run_metadata(run_metadata, 'Iterations%03d' % Iterations)
else:
# train
trainingopt, trainingLoss, merged_r = sess.run([opt,loss,merged], feed_dict = {X_input: batchInput, y_true:batchLabels})
# 记录参数
writer_val.add_summary(merged_r, Iterations)
2.运行后的效果
颜色与消耗的时间和占用的内存相关,越深色使用越多。

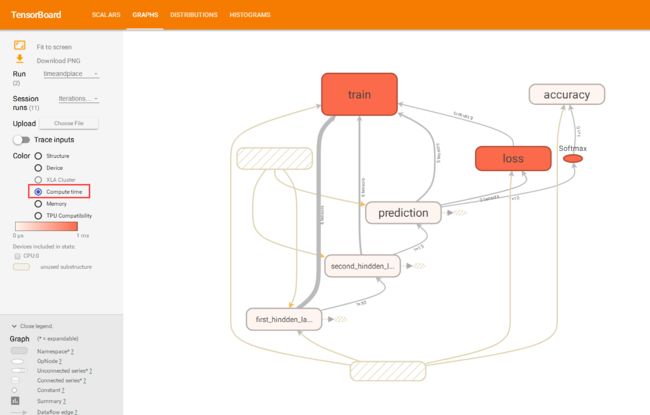
粗略梳理下tensorboard的使用,如果有疏漏,请留言修正。