python:利用scrapy爬取图片
python:利用scrapy爬取图片,爬取的图片为福利图片,程序都带有详细注释,就不再过多码字
1.创建工程
scrapy startproject beautifulgirl
2.在spiders文件里创建属于属于自己的spider文件
![]()
3.设置item
import scrapy
#图片下载管道
class BeautifulgirlItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_name=scrapy.Field()
image_urls=scrapy.Field()
images=scrapy.Field()
referer=scrapy.Field()
pass
先去网页踩点
找到图片所在的类
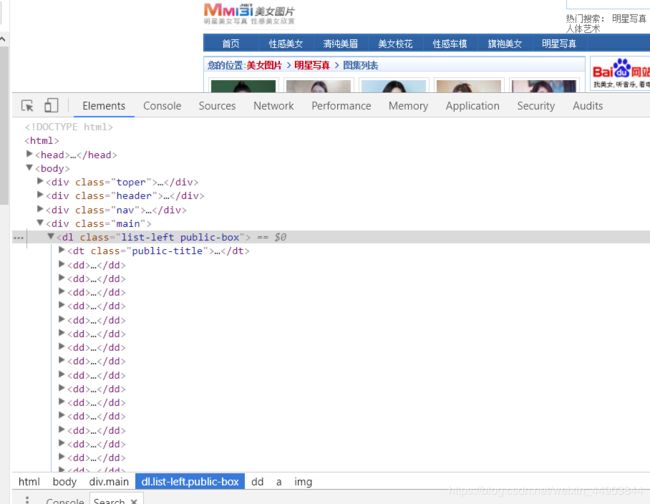
4.编写Spiders
import scrapy
from beautifulgirl.items import BeautifulgirlItem
class ImgspiderSpider(scrapy.Spider):
name='girl' #名字唯一,用于爬取
allowed_domains=['www.mm131.net'] #设置过滤爬取的域名,插件OffsiteMiddleware启用的情况下(默认是启用的),不在此允许范围内的域名就会被过滤,而不会进行爬取
start_urls=['https://www.mm131.net/xinggan/', #爬取的链接,这里将首页一行的标题链接都放进去了
'https://www.mm131.net/qingchun/',
'https://www.mm131.net/xiaohua/',
'https://www.mm131.net/chemo/',
'https://www.mm131.net/qipao/',
'https://www.mm131.net/mingxing/'
]
def parse(self,response): #编写回调函数
list=response.css('.main dd:not(.page)') #获取图片列表,css表达式 :not(p) 表示选择非p元素的每一个元素 ,即获取本页面所有图片
for image in list:
image_name=image.css('a::text').extract_first() #获取图片名字 text提取文本,extract_first选取第一个元素
image_url=image.css('a::attr(href)').extract_first()
image_url2=str(image_url) #网址字符串化
print(image_url2)
next_page=response.css('.page-en:nth-last-child(2)::attr(href)').extract_first() #下一页 :nth-last-child(2)选择其父元素的最后一元素开始计数
if next_page is not None:
yield response.follow(next_page,callback=self.parse) #返回Request实例
yield scrapy.Request(image_url2,callback=self.downloadImage) #返回请求地址imgur12 callback指定请求返回的response 由那个函数来处理
def downloadImage(self,response): #获取网页点进去后的网页图像 上一行返回的请求地址,其响应就是这个函数
item=BeautifulgirlItem()
item['image_name']=response.css('.content h5::text').extract_first() #获取名字
item['image_urls']=response.css('.content-pic img::attr(src)').extract() #获取地址 extract 序列化该节点位unicode字符串并返回list
print('---------------image_urls---------',item['image_urls'])
item['referer']=response.url #将请求的链接,放在URL携带的referer中 用于验证请求的合法性
yield item
next_url =response.css('.page-ch:last-child::attr(href)').extract_first() #获取下一页
if next_url is not None:
yield response.follow(next_url,callback=self.downloadImage,dont_filter=True) #若没到最后一页,则返回下一页请求
5.编写pipeline处理下载的图片分组
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy.http import Request
import re
class My_Pipeline(ImagesPipeline): #继承ImagesPipeline 类,重写pipeline
def get_media_requests(self,item,info): #获取图片请求 item,这个就是通过spiders传递过来的item ,info,是一个保存了图片的名字和下载链接的列表
for image_url in item['image_urls']:
print('-------------image_url---------%s',image_url)
yield Request(image_url,meta={'name':item['image_name']},headers={'referer':item['referer']}) #返回获取的链接,图片名字和referer
def file_path(self,request,response=None,info=None): #重命名图片名字,定义下载分类
img_name=request.url.split('/')[-1] #图片分片,将获取的图片遇/进行分割
name=request.meta['name'] #接受meta传递过来的名字
name=re.sub(r'[?\\*|"<>:/()0123456789]','',name) #过滤windows字符串 不然会乱码
filename=u'pic/{0}/{1}'.format(name,img_name) #创建文件夹,便于观看
return filename
def item_completed(self,results,item,info): #所有图片处理完毕后(不管下载成功或失败),会调用item_completed进行处理
image_paths=[x['path']for ok,x in results if ok] #简写 for ok,x in results:
if not image_paths: # if ok:
raise DropItem('Item contains no images') # prink(x['path'])
item['image_urls']=image_paths #将保存路径保存于 item 中
return item #item_completed参数中包含 item ,有我们抓取的所有信息,参数 results 为下载图片的结果数组,包含下载后的路径以及是否成功下载
6.最后设置setting文件
BOT_NAME = 'beautifulgirl'
SPIDER_MODULES = ['beautifulgirl.spiders']
NEWSPIDER_MODULE = 'beautifulgirl.spiders'
IMAGES_STORE = 'D:\office' #保存路径
IMAGES_EXPIRES = 90 #90天内抓取的都不会被重抓
ITEM_PIPELINES = {
'beautifulgirl.pipelines.My_Pipeline': 300,
}
爬取后可以看到文件已被下载
图片名字过于敏感,打了马赛克,图片还行
