Celery分布式爬虫牛刀小试
本案例目标为爬取知乎网站的推荐问题列表的信息,旨在展示celery的功能。爬取知乎的原理此处不 作太多说明,详见如下代码。
zhihu.py
from celery import Celery
import json
import time
import requests
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36','referer': 'https://www.zhihu.com/'}
cookies={'zap':'da8ecdcd-d34f-4a63-b3d1-359c9bac8b39','xsrf':'13d0d229-8dcb-433f-b9d7-0915f123a85d','d_c0':"AIDvme8HYhCPTkMTA2o7iEEo-wjVcXhxhHE=|1574236655",
'l_n_c':'1','o_act':'login','ref_source':"zhuanlan",'n_c':'1','z_c0':"2|1:0|10:1575538804|4:z_c0|92:Mi4xbzFhekRRQUFBQUFBZ08tWjd3ZGlFQ1lBQUFCZ0FsVk5kQjdXWGdDVjdPYWJjd19qYzVFZ2VmaG9CLUk1N2g3Qm9n|429fa560ec2c44f45d04e07115865de1c924457fcc036dc5ffc6ab09396ddbe0",
'Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49':'1580886183,1582197434,1582555670,1582556436', 'tst':'r', 'q_c1':'14a6c46b4b1b4bb6a33b13a47f75dbb5|1582763822000|1575538817000',
'KLBRSID':'4843ceb2c0de43091e0ff7c22eadca8c|1582768246|1582762619', 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49':'1582768257'}
url='https://www.zhihu.com/api/v3/feed/topstory/recommend'
app=Celery('slave',broker = 'redis://:XXXXX@127.0.0.1:6379/14',backend = 'redis://:XXXXXX@127.0.0.1:6379/15') #xxxxx代表redis访问密码
@app.task()
def downloader(page): #下载函数
params = {'session_token': '6efd64f3eb88474475e2314d0703846c',
'desktop': 'true',
'page_number': page,
'limit': '6',
'action': 'down',
'after_id': 2*(page-1)-1}
print("开始下载")
html = requests.get(url, params=params, headers=headers,cookies=cookies)
time.sleep(1)
# print(html.text)
get_data(html.json())
# return html.json()
def get_data(resp):#数据解析函数
d=resp['data']
for i in d:
if 'target' in i and i['target']['type']=='answer': #知乎的列表里有些不是常规的问题回答,所以这里要判断,以免出错comment_count=i['target']['comment_count']
author=i['target']['author']['name']
content=i['target']['content']
voteup_count = i['target']['voteup_count']
answer_count = i['target']['question']['answer_count']
id = i['target']['question']['id']
title = i['target']['question']['title']
url = 'https://www.zhihu.com/question/' + str(id) + '/answer/' + str(i['target']['id'])
print("作者",':',author,'发布时间:',time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(i['created_time'])),"问题:",title,'问题编号:',id,"评价数:",comment_count,"回答数:",answer_count,"赞同数:",voteup_count,'问题链接:',url)
在windows和Unbantu虚拟机中分别部署一个爬虫结点(即安装celery库,并将上述爬虫文件拷贝至所需路径),然后在windows和Unbantu的命令行中输入如下命令,分别启动爬虫结点(worker)
celery -A zhizhu worker --loglevel=info
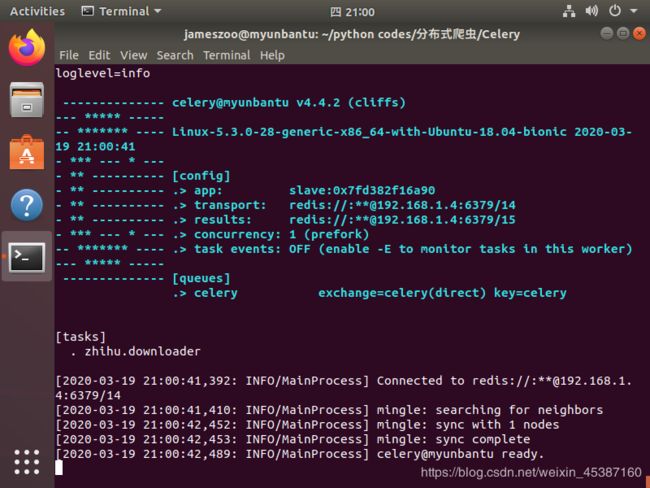
成功启动后界面如下图,爬虫结点等待celery的爬虫任务。
接下来,在windows命令行中进入zhihu.py所在目录,打开python交互界面,
再输入命令:
from zhihu import downloader
for i in range(200):
downloader.delay(i)
windows和ubantu两个爬虫结点爬取效果如下图所示:

坑点:
1、ubantu中启动爬虫结点时,系统提示Error 111 connecting to 192.168.1.4: 6379,connection refused.访问被拒绝。即虚拟机无法访问windos宿主机中的redis数据库。
解决方案:
在windows系统redis安装目录中的conf文件中,取消本机访问的限制。即前面加一个"#"号。
bind 127.0.0.1
然后重新启动redis服务即可。
欢迎交流学习!