(一)打开我们存为csv文件的数据:

(二)运用上次的sqlite学习的知识,把上述csv文件的数据都写进数据库中。
1 import csv 2 import sqlite3 3 import csv 4 import sqlite3 5 def writedate(roadpath): 6 csv_file = csv.reader(open("E:\Spyder\2019中国最好大学排名.csv", "r")) 7 lst_all = [] 8 for i in csv_file: 9 lst_all.append(i) 10 con = sqlite3.connect("10张颖慧.db") 11 cur = con.cursor() 12 cur.execute("create table ad(a,b,c,d,e,f,g,h,i,j,k,l,m,n)") #创建一个表 13 for j in range(len(lst_all)): 14 cur.execute("insert into ad values(?,?,?,?,?,?,?,?,?,?,?,?,?,?)", (lst_all[j][0], lst_all[j][1], lst_all[j][2], lst_all[j][3], lst_all[j][4], lst_all[j][5], lst_all[j][6], lst_all[j][7], lst_all[j][8], lst_all[j][9], lst_all[j][10], lst_all[j][11], lst_all[j][12], lst_all[j][13])) 15 cur.execute("select * from ad ") 16 #显示写进数据库中的所有内容 17 #print(cur.fetchall()) 18 con.commit() 19 con.close() 20 def destroyTable(dbName): 21 # 连接数据库 22 connect = sqlite3.connect(dbName) 23 # 删除表 24 connect.execute("DROP TABLE {}".format("ad")) 25 # 提交事务 26 connect.commit() 27 # 断开连接 28 connect.close() 29 def searchData(roadpath): 30 con = sqlite3.connect("10张颖慧.db") 31 cur = con.cursor() 32 cur.execute("select * from ad where b= '广东技术师范大学'") 33 print(cur.fetchall()) 34 con.commit() 35 con.close() 36 def main(): 37 writedate("E:\Spyder\2019中国最好大学排名.csv") 38 searchData("E:\Spyder\2019中国最好大学排名.csv") 39 destroyTable("10张颖慧.db") 40 main()
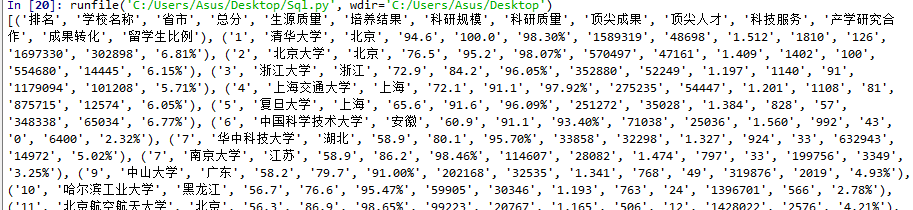
(三)查询并显示广东省学校的排名和科技服务得分
1 import requests 2 from bs4 import BeautifulSoup 3 allUniv=[] 4 def getHTMLText(url): 5 try: 6 r=requests.get(url,timeout=30) 7 r.raise_for_status() 8 r.encoding = 'utf-8' 9 return r.text 10 except: 11 return "" 12 def fillUnivList(soup): 13 data = soup.find_all('tr') 14 for tr in data: 15 ltd = tr.find_all('td') 16 if len(ltd)==0: 17 continue 18 singleUniv = [] 19 for td in ltd: 20 singleUniv.append(td.string) 21 allUniv.append(singleUniv) 22 def printUnivList(num): 23 a="广东" 24 print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","科技服务")) 25 for i in range(num): 26 u=allUniv[i] 27 #print(u[1]) 28 if a in u: 29 print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^8.1f}{5:{0}^10}".format(chr(12288),i+1,u[1],u[2],eval(u[3]),u[7])) 30 def main(): 31 url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' 32 html = getHTMLText(url) 33 soup = BeautifulSoup(html,"html.parser") 34 fillUnivList(soup) 35 num=len(allUniv) 36 printUnivList(num) 37 main()

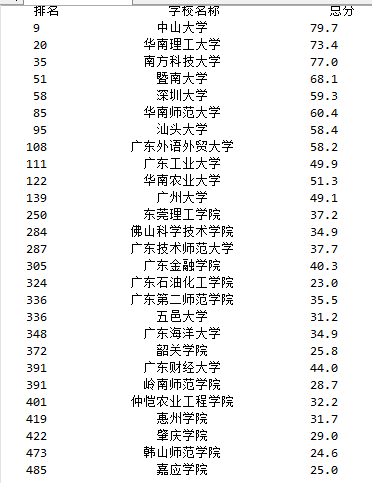
(四)广东省学校排名和得分
1 import csv 2 import os 3 import requests 4 import pandas 5 from bs4 import BeautifulSoup 6 allUniv = [] 7 def getHTMLText(url): 8 try: 9 r = requests.get(url, timeout=30) 10 r.raise_for_status() 11 r.encoding = 'utf-8' 12 return r.text 13 except: 14 return "" 15 def fillUnivList(soup): 16 data = soup.find_all('tr') 17 for tr in data: 18 ltd = tr.find_all('td') 19 if len(ltd)==0: 20 continue 21 singleUniv = [] 22 for td in ltd: 23 singleUniv.append(td.string) 24 allUniv.append(singleUniv) 25 def findUnivData(num): 26 a="广东" 27 print("{0:^10}\t{1:{3}^10}\t{2:^10}".format("排名","学校名称","总分",chr(12288))) 28 for i in range(num): 29 u=allUniv[i] 30 if a in u: 31 print("{0:^10}\t{1:{3}^10}\t{2:^10}".format(u[0],u[1],eval(u[4]),chr(12288))) 32 def main(): 33 url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html' 34 html = getHTMLText(url) 35 soup = BeautifulSoup(html, "html.parser") 36 fillUnivList(soup) 37 num=len(allUniv) 38 findUnivData(num) 39 main()