高级操作系统——XV6进程管理
源代码阅读:
type.h:用于声明一些数据类型的简化名称,和声明页表指针的数据类型。
param.h:主要用于声明基本的一些常量,包括内核栈大小等。
memlayout.h:主要用于声明一些和内存与地址相关的常量与方法,包括虚拟内存转物理内存的方法以及物理内存转虚拟内存的方法等。
defs.h:声明在之后文件中要用到的函数。
x86.h:让c代码使用特殊的x86汇编的一些函数包括outb等,并声明trapframe。
asm.h:一些汇编上的宏定义
mmu.h:定义x86内存管理单元,包括控制寄存器CR上的不同位代表的含义。
elf.hELF:可执行文件的格式,包括ELF头的数据结构等。
vm.c:一些cpu虚拟内存管理的函数
proc.h:声明了CPU在内核中的数据结构表示struct cpu,进程在内核中的数据结构struct proc,上下文在内核中的数据结构struct context。
swtch.S声明用于上下文切换的swtch函数,汇编语言生成
kalloc.c声明一些物理内存分配的函数,包括分配的kalloc()和用于free的kfree()。
Proc.c:
Ptable:进程索引表
Nextpid:进程的ID
Allocproc:分配进程的内核栈和一些寄存器,将进程状态UNUSED改写为EMBRYO
Userinit:第一个进程的初始化操作
Growproc:增加或者减少所占用的内存空间
Fork():创建进程
Exit():退出当前进程,并将其父进程唤醒
Wait();等待子进程退出的
scheduler():内核运行时用于进程调度的循环
sched():切换到内核的
yield():放弃cpu占用
sleep();换成SLEEPING状态,并通过chan标志进程
wakeup();唤醒chan上所有的进程
kill():杀死进程
procdump;向控制台上打印当前进程状态的
(一) 什么是进程,什么是线程?操作系统的资源分配单位和调度单位分别是什么?XV6 中的
进程和线程分别是什么,都实现了吗?
答案:
(1)什么是进程:
1:操作系统由单道处理转向多道处理,传统的静态程序已经不能描述执行的并发性,所以由动态的进程对多道并发进行描述。
2:进程是程序,数据,程序控制块的集合
(2)什么是线程:
(3):进程占用空间多,切换时空消耗大。而为了降低时空消耗,引入了线程
引入线程前:资源分配单位和调度为进程
引入线程后:资源分配的单位是进程,调度的单位是线程
(4)XV6中只实现了进程proc,具体内容在proc.c中
(二) 进程管理的数据结构是什么?在 Windows,Linux,XV6 中分别叫什么名字?其中包含哪些内容?操作系统是如何进行管理进程管理数据结构的?它们是如何初始化的?
(1):进程管理的数据结构是进程控制块。
(2):Linux:task_struct
Windows:EPROCESS、KPROCESS、PEB
XV6:proc .h,proc.c
(3):包含 进程描述信息,进程控制信息,所拥有的资源和使用情况,CPU现场信息
1:Linux下为/include/linux/sched.h内部的struct task_struct,其中包括管理进程所需的各种信息。创建一个新进程时,系统在内存中申请一个空的task_struct ,并填入所需信息。同时将指向该结构的指针填入到task[]数组中。
2:Windows下拥有两个相关的对象,EPROCESS(执行体进程对象) KPROCESS(内核进程对象 )其中KPROCESS又称为PCB
EPEOCESS位于内核层之上它侧重于提供各种管理策略,同时为上层应用程序提供基本的功能接口。所以,在执行体层的进程和线程数据结构中,有些成员直接对应于上层应用程序中所看到的功能实体。
KPROCESS结构体位于内核层,存储着进程的必要信息
3:XV6下在proc .h内声明,包括进程 ID ,进程状态 ,父进程,context,cpu记录了内存地址和栈指针等
xv6的PCB就是proc.h中的proc结构体。其内容包括:
uint sz:进程的内存空间大小。
pde_t* pgdir:进程的页表。
char *kstack:进程的内核栈指针
enum procstate state:进程的状态(包括六种UNUSED, EMBRYO, SLEEPING, RUNNABLE, RUNNING, ZOMBIE)
int pid:进程的pid
struct proc *parent:进程的父进程指针。
struct trapframe *tf:位于x86.h,是中断进程后,需要恢复进程继续执行所保存的寄存器内容。
struct context *context:切换进程所需要保存的进程状态。切换进程需要维护的寄存器内容,定义在proc.h中。
void *chan:不为0时,保存该进程睡眠时的队列。
int killed:不为0时,则该进程被杀死。
struct file *ofile[NOFILE]:打开文件的组。
struct inode *cwd:进程当前的目录。
char name[16]:进程名。
(4):Xv6通过数据结构ptable对进程进行管理,代码如下:
struct {
struct spinlock lock;
struct proc proc[NPROC];
} ptable;
(5):Xv6的初始化操作:
1:第一个进程初始化:自举程序bootmain.c,调用主方法main.c,调用proc.c中的userinit()建立
2:第一个用户进程(分配了一个物理页,并将这个物理地址页映射到虚拟地址为0处,将原来的加载到物理地址为0处的initcode.S的代码加载到这个虚拟地址对应的物理页中。另外还设置进程的trapframe,以便能从内核态返回到用户态)
3:之后的进程初始化:调用fork()
4:无论是userinit()还是fork()都会调用allocproc()函数
5:allocproc的工作是在页表中分配一个槽(即结构体 struct proc),并初始化进程的状态,为其内核线程的运行做准备。简而言之,即设置好一个特别准备的内核栈和一系列内核寄存器,并将进程状态由UNUSED改写为EMBRYO
(三) 进程有哪些状态?请画出 XV6 的进程状态转化图。在 Linux,XV6 中,进程的状态分别 包括哪些?你认为操作系统的设计者为什么会有这样的设计思路?
(1):进程状态分别有:UNUSED,EMBRYO,RUNNABLE,RUNNING,SLEEPING,ZOMBIE
1:UNUSED:进程的初始化状态(enum枚举特性决定)
2:fork()或者userinit()中调用allocproc()即分配内核栈后改为EMBRYO
3:fork()或者userinit()进行一系列初始化操作后改为RUNNABLE
4:scheduler()会一直执行选择进程改为RUNNING,进程调用yield()改为RUNNABLE, 调用sleep()改为SLEEPING,而wakeup()由SLEEPING改为RUNNABLE
5:程序调用exit()和wait()会将其变为ZOMBIE
(2):Linux进程状态:创建,就绪,执行,阻塞,就绪挂起,阻塞挂起,结束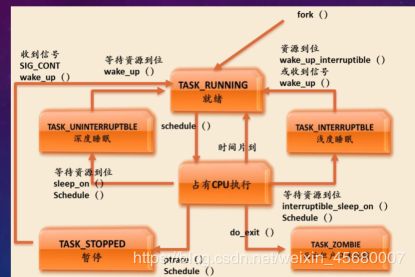
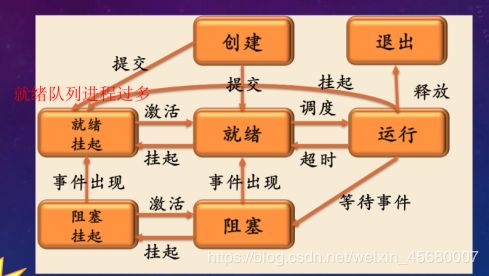
(3):提高CPU的利用率,增加并发能力
(四) 如何启动多进程(创建子进程)?如何调度多进程?调度算法有哪些?操作系统为何要 限制一个 CPU 最大支持的进程数?XV6 中的最大进程数是多少?如何执行进程的切换?什么是进程上下文?多进程和多 CPU 有什么关系?
(1):利用操作系统创建或者父进程创建,在xv6中,第一个进程是由Userinit()创建初始化,之后通过fork()创建初始化
(2):利用调度算法进行调度
(3):先来先服务,短作业先服务,时间片轮转发,优先级调度法,多级反馈轮转法,高响应比优先法
(4):一是考虑内存空间,进程数量过多占用大量内存 二是增加了缺页中断的可能性,会导致cpu不断的执行页面换入换出,浪费大量时间
(5):XV6的最大进程数见param.h文件中的#define NPROC 64,最大64;
#define NPROC 64 // maximum number of processes
(6):切换上下文:
1:当前进程通过调用yield()(可能是时间片用完),进行进程切换。yield函数调用sched函数,sched函数启动switch函数完成进程切换,而switch又会触发scheduler(void),scheduler(void)中会选择一个进程切换上下文,仍调用swtch(&cpu->scheduler, proc->context);
2:整个流程是这样的:yield->sched->switch->scheduler->switch
3:其中switch的函数原型void swtch(struct context **old, struct context *new);
4:它的工作主要包括:1. 保存当前(old)进程的上下文。 2. 加载新进程(new)的上下文到机器寄存器中。可以理解为是汇编实现
(7):进程运行时,其硬件状态保存在CPU 上的寄存器中,寄存器:程序计数器、程序状态寄存器、栈指针、通用寄存器、其他控制寄存器的值。进程不运行时,这些寄存器的值保存在PCB 中。将CPU 硬件状态从一个进程换到另一个进程的过程称为
上下文切换
(8):没有必然联系。一个CPU在某一时刻只能运行一个进程,宏观上并行,微观上串行。而多个CPU可以同时运行多个程序
(五) 内核态进程是什么?用户态进程是什么?它们有什么区别?
(1):系统分为内核态和用户态。在内核里产生的进程称为内核级进程,在用户态上产生的进程称为用户态进程。
(2)区别:
1)运行在不同的系统状态,用户态进程执行在用户态,内核态进程执行在内核态
2)进入方式不同,用户态进程可直接进入,内核态必须通过运行系统调用命令
3)返回方式不同,用户态进程直接返回,内核态进程有重新调度过程
4)内核态进程优先级要高于用户态进程,并且内核态进程特权级别最高,它可以执行系统级别的代码
联系:
用户级进程和内核级进程存在一对一,多对一,多对多的关系
(六) 首先看一个简略的进程在内存中的布局

再看一个详细的部分
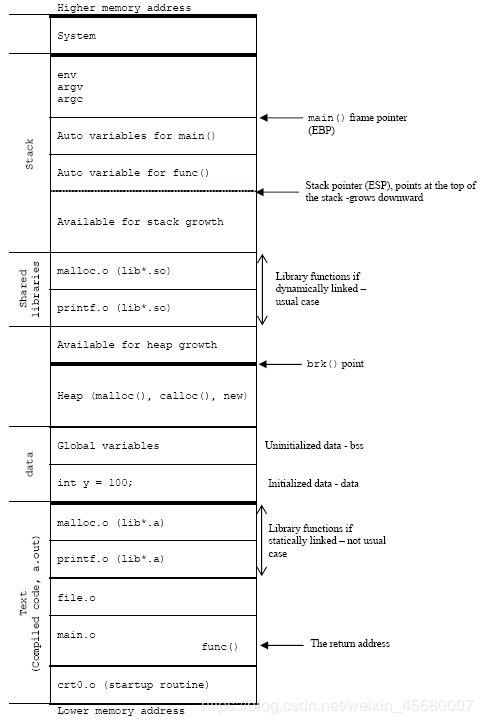
在内存中分为五部分:
(1)代码区(Code segment):存放程序的二进制代码文件
(2)常量区(Constant segment):所有常量均存放在常量区。程序结束后由OS释放通常是字符串常量
(3)全局数据区(Global data segment):全局变量和静态数据,函数内部的静态局部变量。程序结束有OS释放
(4)堆区(Heap segment):new,malloc产生的动态数据。由程序员分配和释放 一般一个new就要对应一个delete
有时候堆区又分为 自由存储区,就是那些由malloc等分配的内存块,他和堆是十分相似的,不过它是用free来结束自己的生命的。
(5)栈区(Stack segment):局部变量,函数参数。由编译器自动分配和释放
一个例子,大概介绍各个常量和变量的对应区关系
//main.cpp
int a = 0; 全局初始化区
char *p1; 全局未初始化区
main()
{
int b; 栈
char s[] = “123”; 栈
char *p2 = “abcdefg”;abcdefg\0在常量区,p3在栈上。
char *p3; 栈
static int c =0; 全局(静态)初始化区
p1 = (char *)malloc(10);
p2 = (char *)malloc(20);
分配得来得10和20字节的区域就在堆区。
strcpy(p1, “123456”); 123456\0放在常量区,编译器可能会将它与2所指向的"abcdefg"
优化成一个地方。
}
栈和堆的区别
(1)申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:堆中空闲内存地址是以链表方式进行存储的。当需要申请分配时,遍历链表寻找第一个大于所申请空间的堆结点,将此节点的空间分配给程序并且记录本次分配的大小,以便于之后delete程序释放内存空间。
若找到的堆节点大于申请的大小,系统会将多余的部分重新放入空闲链表
(2)申请大小的限度
栈:在Windows下,栈是向低地址扩展的数据结构, 是一块连续的内存的区域。栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,用链表来存储,是不连续的内存区域。而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较
(3)申请效率的比较:
栈:系统自动分配,速度较快。但程序员是无法控制的
堆:由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
(4)堆和栈中的存储内容
栈: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的,会进入全局数据区当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
参考资源:
https://www.jianshu.com/p/e01680c00de4
https://blog.csdn.net/zhanglei8893/article/details/6101076
https://blog.csdn.net/qq_36347375/article/details/91354349
https://www.cnblogs.com/LittleHann/p/3454748.html
https://www.cnblogs.com/itzxy/p/9293677.html