笔记总结:Dual Residual Networks Leveraging the Potential of Paired Operations for Image Restoration
Dual Residual Networks五种任务总结和对比
原文: Dual Residual Networks Leveraging the Potential of Paired Operations for Image Restoration
原文代码github
博主的阅读笔记:
- Gaussian&real-world noise removal(去噪任务阅读笔记)
- motion blur removal (去运动模糊任务阅读笔记)
- haze removal (去雾任务阅读笔记)
- raindrop removal (去雨滴任务阅读笔记)
- rain-streak removal (去雨线任务阅读笔记)
文章目录
- 基本块对比
- 网络结构对比
- 优化器和损失函数对比
- 在非目标任务上的DuRB性能
- 实验设置对比
- 代码注释
- 补充:如何查看网络的层数,参数,结构等信息
双残差网络用于五种任务:
| 任务 | 基本块 | 网络 | 数据集 |
|---|---|---|---|
| Gaussian&real-world noise removal | DuRB-P | DuRN-P | BSD-grayscale&Real-World Noisy Image Dataset |
| motion blur removal | DuRB-U | DuRN-U | GoPro Dataset/Car Dataset |
| haze removal | DuRB-US | DuRN-US | Dehaze Dataset/RESIDE dataset |
| raindrop removal | DuRB-S&DuRB-P | DuRN-S-P | RainDrop Dataset |
| rain-streak removal | DuRB-S | DuRN-S | DID-MDN Data/DID-MDN Data |
基本块对比
五种任务所用的基本块结构( the base structure):
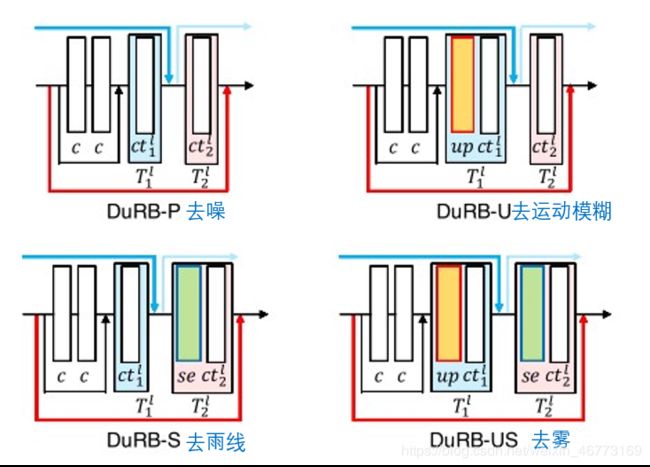
注:去雨滴任务为DuRB-S和DuRB-P的组合
每个基本块的成对操作对比:
| T 1 l T^{l}_{1} T1l | T 2 l T^{l}_{2} T2l | |
|---|---|---|
| DuRB-P | (conv.+ bn) | (conv.+ bn) |
| DuRB-U | (up+conv+insnorm) | (conv+insnorm), stride=2 for down-scaling |
| DuRB-US | (up+conv.) | (se+conv.), stride=2 for down-scaling |
| DuRB-S&DuRB-P | (conv. + bn)&(conv. + bn) | (se + conv. + bn)&(conv. + bn) |
| DuRB-S | (conv. + bn) | (se + conv. + bn) |
bn:batch_norm(批归一化)
insnorm:instance归一化,采用自定义的InsNorm归一化函数(见
N_modules.InsNorm)T 1 l T^{l}_{1} T1l 中的 conv.+ bn 为:up_conv+up_norm
T 2 l T^{l}_{2} T2l 中的 conv.+ bn为:down_conv+down_norm
网络结构对比
五种任务的网络结构:

网络的总层数和总参数对比:
| 网络 | 网络层数 | 网络训练的总参数 |
|---|---|---|
| DuRN-P/DuRN_P_no_norm | 110/56 | 816,225/815,651 |
| DuRN-U | 150 | 12,856,579 |
| DuRN-US | 208 | 9,070,915 |
| DuRN-S-P | 197 | 10,176,964 |
| DuRN-S | 170 | 3,729,923 |
优化器和损失函数对比
-
对所有的DuRNs,使用Adam优化器, β 1 \beta_1 β1 和 β 2 \beta_2 β2分别取默认值0.9和0.999, ϵ = 1.0 × 1 0 − 8 \epsilon=1.0×10^{−8} ϵ=1.0×10−8。
-
对于损失函数Loss,使用SSIM和 l 1 l_1 l1 损失的加权和,即 1.1 × S S I M + 0.75 × l 1 1.1×SSIM+ 0.75×l_1 1.1×SSIM+0.75×l1,用于所有的任务。
但有两个例外:
- 一个是在BSD-grayscale灰度数据集上的高斯噪声去除,在这里使用 L 2 L_2 L2 损失。
- 一个是雨滴去除,对前4000个epoch使用 1.1 x SSIM + 0.75 x l 1 l_1 l1 损失训练网络4000次,然后转化到使用 l 1 l_1 l1 损失训练网络100次。
-
所有任务的初始学习率设置为0.0001。
在非目标任务上的DuRB性能
有读者会问,作者是如何选出对应任务的对应DuRB结构呢?DuRB用于其他的目标任务结果会是如何呢?论文作者也考虑到了这个问题,于是把每个DuRB分别应用于5个任务,用PSNR/SSIM指标观察其性能。具体见补充材料。
本文已经介绍了四个版本的DuRB,每个版本都是为单个任务设计的。为了验证设计选择的有效性,本文检查了每个DuRB在其非目标任务上的性能。具体来说,我们评估了四个版本的DuRB和五个任务的每个组合的性能。对于噪声、运动模糊、雾霾、雨滴和雨线的去除,本文在Real-World Noisy Image Dataset、GoPro Dataset、Dehaze Dataset、RainDrop Dataset 和 DID-MDN Data上对每个版本的DuRB组成的网络进行训练和测试。结果如表5所示。
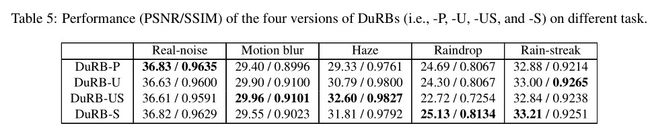
可以看出,一般来说,每个DuRB对于其所设计的任务产生最佳性能。在去除运动模糊方面,DuRB-US的表现与DuRB-U相当,甚至略好于后者,而后者是本文完成这项任务的主要设计。本文认为这是合理的,因为DuRB-US包含与DuRB-U相同的成对操作(即上采样、下采样),性能良好。它们的性能差异几乎可以忽略不计,因此考虑到其效率,DuRB-U是更好的选择。
作者在测试(见test文件夹)阶段使用skimage包自带的PNSR和SSIM作为其模型的评价性能指标:
from skimage.measure import compare_psnr as psnr
from skimage.measure import compare_ssim as ski_ssim
实验设置对比
Note: Please adjust batch_size according to your computational resource
------ Gaussian noise removal -------
dataset = BSD_gray
batch_size = 100
learning_rate = 0.001 (initial learning rate)
total_epochs = 3000
crop_size = 64
noise_level = [30, 50, 70] (randomly chosen)
locally_training_num = 10 (train the model 10 times on a same batch)
learning_rate*= 0.1 at [500, 1000, 1500, 2500] epochs.
loss = L2_loss
--------------------------------------
------- Real-noise removal -------
dataset = RealNoiseHKPoly
batch_size = 30
learning_rate = 0.0001
total_epochs = 3500
crop_size = 128
learning_rate*= 0.1 at [1000, 2000] epochs.
loss = 1.1*ssim_loss + 0.75*L1_loss
----------------------------------
------- Motion blur removal -------
dataset = GoPro
batch_size = 10
learning_rate = 0.0001
total_epochs = 5000
crop_size = 256
resize_to = (640, 360)
learning_rate*= 0.1 at [2000, 4000] epochs.
loss = 1.1*ssim_loss + 0.75*L1_loss
-----------------------------------
------- Haze removal -------
dataset = RESIDE
batch_size = 40
learning_rate = 0.0001
total_epochs = 3000
crop_size = 256
learning_rate*= 0.1 at [700, 1400] epochs.
loss = 1.1*ssim_loss + 0.75*L1_loss
------
dataset = DCPDNData
batch_size = 20
learning_rate = 0.0001
total_epochs = 600
crop_size = 256
learning_rate no change
loss = 1.1*ssim_loss + 0.75*L1_loss
----------------------------
------- rain-streak removal -------
dataset = DIDMDN_Data (or DDN_Data)
batch_size = 40
learning_rate = 0.0001
total_epochs = 2000
crop_size = 64
data_augmentation: Image.FLIP_LEFT_RIGHT (randomly)
learning_rate is adjusted by torch.optim.lr_scheduler.CosineAnnealingLR()
loss = 1.1*ssim_loss + 0.75*L1_loss
-----------------------------------
------- raindrop removal -------
---- step-1
dataset = RainDrop
batch_size = 24
learning_rate = 0.0001
total_epochs = 4000
crop_size = 256
learning_rate*= 0.5 at [2000] epochs.
loss = 1.1*ssim_loss + 0.75*L1_loss
---- step-2
dataset = RainDrop
batch_size = 24
learning_rate = 0.00001
total_epochs = 100
crop_size = 256
learning_rate no change
loss = 1.1*L1_loss
---------------------------------
代码注释
在阅读笔记(一)中已对 Gaussian noise removal(DuRN-P)的代码进行了详细注释,其他的几个任务除了网络结构不一样,其他大体相同,请参考之。
- 数据预处理,见
data_conventors.py - 模型构建,见
DuRN_**.py - 损失函数,见
pytorch_ssim - 训练运行,见
train文件夹下各个任务对应的.py文件
补充:如何查看网络的层数,参数,结构等信息
- 在每个
DuRN_**.py代码末尾加上以下命令
# 统计网络层数与参数
net = cleaner()
print(net)
params = list(net.parameters())
print('网络层数:',len(params))
# 打印每层的详细信息
# k=0
# for i in params:
# l =1
# print("该层的结构:"+ str(list(i.size())))
# for j in i.size():
# l *= j
# print("该层参数和:"+ str(l))
# k = k+l
# print('总参数和:'+ str(k))
举例:查看real-world noise removal任务的网络详细信息,定位到网络模型构建.py文件,即DuRN_P_no_norm.py,在其代码末加上上述命令:
运行该DuRN_P_no_norm.py,输出为:
cleaner(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(block1): DuRB_p(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(up_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((2, 2, 2, 2))
(conv2d): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1))
)
(down_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(relu): ReLU()
)
(block2): DuRB_p(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(up_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((3, 3, 3, 3))
(conv2d): Conv2d(32, 32, kernel_size=(7, 7), stride=(1, 1))
)
(down_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((2, 2, 2, 2))
(conv2d): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1))
)
(relu): ReLU()
)
(block3): DuRB_p(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(up_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((6, 6, 6, 6))
(conv2d): Conv2d(32, 32, kernel_size=(7, 7), stride=(1, 1), dilation=(2, 2))
)
(down_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((2, 2, 2, 2))
(conv2d): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1))
)
(relu): ReLU()
)
(block4): DuRB_p(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(up_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((10, 10, 10, 10))
(conv2d): Conv2d(32, 32, kernel_size=(11, 11), stride=(1, 1), dilation=(2, 2))
)
(down_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((3, 3, 3, 3))
(conv2d): Conv2d(32, 32, kernel_size=(7, 7), stride=(1, 1))
)
(relu): ReLU()
)
(block5): DuRB_p(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(up_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((5, 5, 5, 5))
(conv2d): Conv2d(32, 32, kernel_size=(11, 11), stride=(1, 1))
)
(down_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((2, 2, 2, 2))
(conv2d): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1))
)
(relu): ReLU()
)
(block6): DuRB_p(
(conv1): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv2): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(up_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((15, 15, 15, 15))
(conv2d): Conv2d(32, 32, kernel_size=(11, 11), stride=(1, 1), dilation=(3, 3))
)
(down_conv): ConvLayer(
(reflection_pad): ReflectionPad2d((3, 3, 3, 3))
(conv2d): Conv2d(32, 32, kernel_size=(7, 7), stride=(1, 1))
)
(relu): ReLU()
)
(conv3): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
)
(conv4): ConvLayer(
(reflection_pad): ReflectionPad2d((1, 1, 1, 1))
(conv2d): Conv2d(32, 3, kernel_size=(3, 3), stride=(1, 1))
)
(relu): ReLU()
(tanh): Tanh()
)
网络层数: 56
- 查看网络的每层结构、参数和总参数:
# 查看网络结构以及对应每层的参数
from torchsummary import summary
summary(net, input_size=(3, 64, 64), batch_size=1)
注:使用summary函数,需
pip install torchsummary。
input_size=(3, 64, 64)表示输入图片大小为64x64,通道数为3(即为彩色图片,灰度图片为1),且图片大小不影响网络的参数数量。(为方便,这里博主自己设定为64x64)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
ReflectionPad2d-1 [1, 3, 66, 66] 0
Conv2d-2 [1, 32, 64, 64] 896
ConvLayer-3 [1, 32, 64, 64] 0
ReLU-4 [1, 32, 64, 64] 0
ReflectionPad2d-5 [1, 32, 66, 66] 0
Conv2d-6 [1, 32, 64, 64] 9,248
ConvLayer-7 [1, 32, 64, 64] 0
ReLU-8 [1, 32, 64, 64] 0
ReflectionPad2d-9 [1, 32, 66, 66] 0
Conv2d-10 [1, 32, 64, 64] 9,248
ConvLayer-11 [1, 32, 64, 64] 0
ReLU-12 [1, 32, 64, 64] 0
ReflectionPad2d-13 [1, 32, 66, 66] 0
Conv2d-14 [1, 32, 64, 64] 9,248
ConvLayer-15 [1, 32, 64, 64] 0
ReLU-16 [1, 32, 64, 64] 0
ReflectionPad2d-17 [1, 32, 68, 68] 0
Conv2d-18 [1, 32, 64, 64] 25,632
ConvLayer-19 [1, 32, 64, 64] 0
ReLU-20 [1, 32, 64, 64] 0
ReflectionPad2d-21 [1, 32, 66, 66] 0
Conv2d-22 [1, 32, 64, 64] 9,248
ConvLayer-23 [1, 32, 64, 64] 0
ReLU-24 [1, 32, 64, 64] 0
DuRB_p-25 [[-1, 32, 64, 64], [-1, 32, 64, 64]] 0
ReflectionPad2d-26 [1, 32, 66, 66] 0
Conv2d-27 [1, 32, 64, 64] 9,248
ConvLayer-28 [1, 32, 64, 64] 0
ReLU-29 [1, 32, 64, 64] 0
ReflectionPad2d-30 [1, 32, 66, 66] 0
Conv2d-31 [1, 32, 64, 64] 9,248
ConvLayer-32 [1, 32, 64, 64] 0
ReLU-33 [1, 32, 64, 64] 0
ReflectionPad2d-34 [1, 32, 70, 70] 0
Conv2d-35 [1, 32, 64, 64] 50,208
ConvLayer-36 [1, 32, 64, 64] 0
ReLU-37 [1, 32, 64, 64] 0
ReflectionPad2d-38 [1, 32, 68, 68] 0
Conv2d-39 [1, 32, 64, 64] 25,632
ConvLayer-40 [1, 32, 64, 64] 0
ReLU-41 [1, 32, 64, 64] 0
DuRB_p-42 [[-1, 32, 64, 64], [-1, 32, 64, 64]] 0
ReflectionPad2d-43 [1, 32, 66, 66] 0
Conv2d-44 [1, 32, 64, 64] 9,248
ConvLayer-45 [1, 32, 64, 64] 0
ReLU-46 [1, 32, 64, 64] 0
ReflectionPad2d-47 [1, 32, 66, 66] 0
Conv2d-48 [1, 32, 64, 64] 9,248
ConvLayer-49 [1, 32, 64, 64] 0
ReLU-50 [1, 32, 64, 64] 0
ReflectionPad2d-51 [1, 32, 76, 76] 0
Conv2d-52 [1, 32, 64, 64] 50,208
ConvLayer-53 [1, 32, 64, 64] 0
ReLU-54 [1, 32, 64, 64] 0
ReflectionPad2d-55 [1, 32, 68, 68] 0
Conv2d-56 [1, 32, 64, 64] 25,632
ConvLayer-57 [1, 32, 64, 64] 0
ReLU-58 [1, 32, 64, 64] 0
DuRB_p-59 [[-1, 32, 64, 64], [-1, 32, 64, 64]] 0
ReflectionPad2d-60 [1, 32, 66, 66] 0
Conv2d-61 [1, 32, 64, 64] 9,248
ConvLayer-62 [1, 32, 64, 64] 0
ReLU-63 [1, 32, 64, 64] 0
ReflectionPad2d-64 [1, 32, 66, 66] 0
Conv2d-65 [1, 32, 64, 64] 9,248
ConvLayer-66 [1, 32, 64, 64] 0
ReLU-67 [1, 32, 64, 64] 0
ReflectionPad2d-68 [1, 32, 84, 84] 0
Conv2d-69 [1, 32, 64, 64] 123,936
ConvLayer-70 [1, 32, 64, 64] 0
ReLU-71 [1, 32, 64, 64] 0
ReflectionPad2d-72 [1, 32, 70, 70] 0
Conv2d-73 [1, 32, 64, 64] 50,208
ConvLayer-74 [1, 32, 64, 64] 0
ReLU-75 [1, 32, 64, 64] 0
DuRB_p-76 [[-1, 32, 64, 64], [-1, 32, 64, 64]] 0
ReflectionPad2d-77 [1, 32, 66, 66] 0
Conv2d-78 [1, 32, 64, 64] 9,248
ConvLayer-79 [1, 32, 64, 64] 0
ReLU-80 [1, 32, 64, 64] 0
ReflectionPad2d-81 [1, 32, 66, 66] 0
Conv2d-82 [1, 32, 64, 64] 9,248
ConvLayer-83 [1, 32, 64, 64] 0
ReLU-84 [1, 32, 64, 64] 0
ReflectionPad2d-85 [1, 32, 74, 74] 0
Conv2d-86 [1, 32, 64, 64] 123,936
ConvLayer-87 [1, 32, 64, 64] 0
ReLU-88 [1, 32, 64, 64] 0
ReflectionPad2d-89 [1, 32, 68, 68] 0
Conv2d-90 [1, 32, 64, 64] 25,632
ConvLayer-91 [1, 32, 64, 64] 0
ReLU-92 [1, 32, 64, 64] 0
DuRB_p-93 [[-1, 32, 64, 64], [-1, 32, 64, 64]] 0
ReflectionPad2d-94 [1, 32, 66, 66] 0
Conv2d-95 [1, 32, 64, 64] 9,248
ConvLayer-96 [1, 32, 64, 64] 0
ReLU-97 [1, 32, 64, 64] 0
ReflectionPad2d-98 [1, 32, 66, 66] 0
Conv2d-99 [1, 32, 64, 64] 9,248
ConvLayer-100 [1, 32, 64, 64] 0
ReLU-101 [1, 32, 64, 64] 0
ReflectionPad2d-102 [1, 32, 94, 94] 0
Conv2d-103 [1, 32, 64, 64] 123,936
ConvLayer-104 [1, 32, 64, 64] 0
ReLU-105 [1, 32, 64, 64] 0
ReflectionPad2d-106 [1, 32, 70, 70] 0
Conv2d-107 [1, 32, 64, 64] 50,208
ConvLayer-108 [1, 32, 64, 64] 0
ReLU-109 [1, 32, 64, 64] 0
DuRB_p-110 [[-1, 32, 64, 64], [-1, 32, 64, 64]] 0
ReflectionPad2d-111 [1, 32, 66, 66] 0
Conv2d-112 [1, 32, 64, 64] 9,248
ConvLayer-113 [1, 32, 64, 64] 0
ReLU-114 [1, 32, 64, 64] 0
ReflectionPad2d-115 [1, 32, 66, 66] 0
Conv2d-116 [1, 3, 64, 64] 867
ConvLayer-117 [1, 3, 64, 64] 0
Tanh-118 [1, 3, 64, 64] 0
================================================================
Total params: 815,651
Trainable params: 815,651
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.05
Forward/backward pass size (MB): 113.13
Params size (MB): 3.11
Estimated Total Size (MB): 116.29
----------------------------------------------------------------