论文阅读笔记:Siamese Network Features for Image Matching
Siamese Network Features for Image Matching 阅读笔记
sHybridCNN 孪生网络 AlexNet
1 概要
1.1 研究背景
- 匹配图像查找在许多计算机视觉应用中起着关键作用,从运动结构(SfM)、多视图三维重建、图像检索和基于图像的定位
- 之前Siamese架构已被应用于人脸图像验证和匹配局部图像补丁,但尚未应用于一般图像检索或整体图像匹配
1.2 现有问题与解决方法
- 基于神经网络的特征向量来表示匹配和非匹配的图像对,其相似度由欧氏距离度量
- 利用卷积神经网络,通过对比损失的方法,分别从匹配和非匹配图像对的标记样本中学习特征向量
1.3 文章贡献
- 提出了一种基于深度神经网络的全图像相似度预测方法
- 将我们的方法应用于新的数据,以检查泛化特征,表明它优于最先进的用于图像分类问题的CNN
2 相关工作
- [2] (Learning to match images in large-scale collections, 2012) 使用视觉词袋模型 bag-of-visual-words (BoW) [1] 的学习来预测输入数据集中哪些图像对是匹配的,哪些不是
- [3] (Neural codes for image retrieval), [4] (A practical guide to cnns and fisher vectors for image instance retrieval, 2015) 用预训练的用于图像分类问题的CNN进行图像检索,不是学习单个图像的分类,而是直接对CNN的匹配任务进行学习。类似于人脸验证问题利用Siamese网络[5] (Learning a similarity metric discriminatively, with application to face verification, 2005)预测输入图像对中的人物是否相同[6], [7]
- [8] (Learning deep representations for ground-to-aerial geolocalization, 2015) 可以成功地匹配街道和鸟瞰图图像
- [9] (Learning to compare image patches via convolutional neural networks), [10] (Matchnet: Unifying feature and metric learning for patch-based matching), [11] (Discriminative learning of deep convolutional feature point descriptors) 类似的方法已经被用于匹配小的局部图像块,但还没有用于通用的图像检索或整幅图像匹配
- [3] (Neural codes for image retrieval) 表明,使用特定领域的数据对预先训练好的CNN进行微调可以提高相关数据集的检索性能
- [4] 对Fisher向量提出了一个系统化评估,和CNN用于图像检索的流程,并表明它们的组合在某些数据集上比单独使用具有更好的性能
- [3] 和 [12] 两种方法都是基于CNN的,但是使用的目标和网络结构不同,不能直接处理图像对
- [8] (Learning deep representations for ground-to-aerial geolocalization, 2015) 利用深度网络,通过直接学习将街景图像与航空图像进行匹配,不使用地面参考图像来对照片进行地理定位
- [13] (Discriminant learning of local image descriptors, 2010) 提出了一种学习patch描述符的原创方法和评价描述符性能的通用框架
- [9]、[10]和[11] 使用了深度神经网络,在几个基准测试中都表现出最先进的性能
- [14] 使用比较图像块的方法提取深度信息,利用卷积网络最小化hinge损失函数(hinge loss function),在KITTI立体评估数据集 [15] 上取得了较好的效果。然而由于这种方法在非常小的补丁上运行(9x9像素),限制了适用范围
- [17] 提出了一种预测SfM任务场景重叠的方法,可有效地寻找相似的图像对,从而提高三维重建的精度。两种方法的共同之处是图像数据相同
3 方法
使用HybridCNN [16] 作为我们网络的核心元素,模型结构如图2所示
在训练过程中,一对图像通过一个由两个分支组成的网络。这些分支的输出被馈送到一个损失层。损失层试图最小化正图像对(f(I1)和f(I2))特征之间的欧氏距离的平方,并最大化负图像对之间的欧氏距离

3.1 对比损失
使相似的样本是接近的,而不同的样本的欧氏距离至少为m
使用了[18]中提出的基于边界值(margin)的对比损失函数,其定义如下:
L = 1 2 l D 2 + 1 2 ( 1 − l ) { max ( 0 , m − D ) } 2 L = \frac { 1 } { 2 } l D ^ { 2 } + \frac { 1 } { 2 } ( 1 - l ) \{ \max ( 0 , m - D ) \} ^ { 2 } L=21lD2+21(1−l){max(0,m−D)}2
其中,l是二元标签,输入对中的图像I1和I2是正样本则l=1,负样本则l=0,m>0是不匹配对的边界值,D=||f(I1)-f(I2)||2 是输入图像I1和I2特征向量f(I1)和f(I2)的欧氏距离
只有当距离在m范围内时,不匹配的对才会产生损失函数;距离大于边界值的负样本对不会造成损失
这种损失函数使匹配的对在特征空间中靠近,不匹配的对远离
3.2 网络结构
我们在实验中使用了基于配对的(Siamese)网络结构,我们的方法受到了地-空地理定位方法 [8] (Learning deep representations for ground-to-aerial geolocalization, 2015) 及一个基础工作 [5] (Learning a similarity metric discriminatively, with application to face verification, 2005) 的影响
该结构由两个相同的分支组成,共享权重和参数。每个分支构成一个深度神经网络,并包括一组卷积层、整流线性单元(ReLU)和全连接层
图像I1和I2被输入到两个训练时相同的分支中。网络结构的主要目标是学习输入对的最优特征表示,其中匹配的图像被拉近,不匹配的图像被推远
我们的Siamese网络(sHybridCNN)架构基于HybridCNN [16] (Learning deep features for scene recognition using places database),它被用于对象和场景图像分类,在 MIT Indoor67 数据集 [19] 上超过了最先进的方法
HybridCNN 是在 ImageNet 和 Places 数据集的组合集 [16] 上训练的一个 AlexNet [20]。在Oxford Building数据集 [21] 的图像检索,HybridCNN的表现优于纯AlexNet和OxfordNet [4]
在HybridCNN的顶部是三个全连接层(fc6, fc7, fc8),由于网络的最后一层(fc8)是根据原始训练数据集(1183个类)中的类数设计的,所以我们去掉了它,使用fc7层作为特征表示。该网络共有5800万个参数,共13层
实验发现,边界值m应是学习前训练图像对特征之间的平均欧氏距离的两倍
为进行实验,有必要有一个数据库组成的图像对相关的landmark类型的数据集。这种图像对集的收集是一项重要的任务,通常涉及到通过匹配SIFT特征和执行几何验证来测试多个图像对。
利用5个从Flickr下载的众包图像集,每个都对应一个流行的地标(London Eye (LE) 6856 images, San Marco (SM) 7580 images, Tate Modern ™ 4583 images, Times Square (TS) 6361 images, Trafalgar (T) 6802 images) [2] (Learning to match images in large-scale collections, 2012) ,原始数据集包含颜色和灰度图像。
用于匹配图像对(正样本)的ground truth标签由 [2] 提供,仅考虑前500个最相似的图像,基于BoW向量点积计算相似性度量。利用匹配图像对的信息,生成对应于不匹配对的图像id
4 实验
我们希望找到两个问题的答案:(a) 网络是否能够学会更好地利用这类训练数据来区分相似和不同的配对;(b) 如果我们的网络是可学习的,从它提取的特征是否可以推广到其他数据集?
在每次实验中,都将网络中fc7层的激活值作为特征向量
4.1 图像相似性度量
有很多种衡量图像相似性准确度的方法 [22] (The relationship between precision-recall
and roc curves, 2006)。我们使用receiver operating characteristics(ROC曲线),它通常用于分析机器学习中二元决策问题的结果,ROC曲线下的面积作为定量度量
另外还使用precision-recall(PR)特征
4.2 数据集和预处理
训练数据集采用4个地标的图像对的组合,测试数据集使用剩余的地标的图像对的集合。按照这个过程,得到5个不同的测试和训练数据集
每个地标的图像和正图像对列表由[2]提供,利用相同地标的图像随机生成负对,在测试数据集中匹配和不匹配的对的数量是相等的
训练数据中不相似对的数量是相似图像对数目的1.5倍
如果原图由一个灰度图像和一个彩色图像组成,将RGB图像转换成灰度图像,然后将这些灰度对视为彩色对。每个目标地标的灰度和彩色图像的比例为5%
由于提出的深度网络是对正常方向的图像进行预训练,使用EXIF信息将训练数据集中的图像自动旋转到正常方向
在不裁剪的情况下将图像大小调整为227 x 227像素,将其作为网络的输入
4.3 实验细节
训练网络使用随机梯度下降(SGD)、标准的反向传播方法[23]、AdaDelta[24]
使用在Imagenet和Place数据集[16]上预训练的深度网络(HybridCNN)的权值初始化我们的Siamese方法,使用类似于[8]的技术来完善一个预先训练好的模型
设置学习率,最后的全连接层(fc7)为10-5,其他层为10-6
该模型使用深度学习框架Caffe[25]进行训练、一个NVIDIA TITAN Z GPU,大约40个小时完成了10个epochs训练
5 结果和讨论
比较了以下几种基于深度学习技术的方法的结果:
- **AlexNet:**使用AlexNet在ImageNet上预训练分类,作为特征空间中的图像描述符。直接提取由网络fc7层的4096维输出作为图像匹配的特征。将AlexNet作为实验的基准
- **HybridNet [16]:**HybridNet具有与AlexNet完全相同的架构,但针对的是不同的数据,训练数据是ImageNet和Places数据集的组合。根据[4],HybridNet在对Oxford Building数据集的图像检索方面有很好表现,因此它可以很好地对新数据进行泛化
- **sHybridNet:**从在我们数据库上训练的暹罗深度卷积网络中提取特征,在训练阶段使用预训练HybridNet的参数(权重)初始化sHybridNet的参数。在训练之后,提取网络fc7层的4096维特征向量。
- HybridNet。通过对标记对的训练,进行提取4;096维特征向量来自fc7层的网络结构。
在所有情况下,图像对的评价都是基于图像特征向量之间的欧氏距离
在图3的测试集(Tate Modern地标)上计算了HybridCNN和sHybridCNN的欧氏距离直方图,蓝条表示正对,黄条表示负对。HybridCNN的对距离分布显示了未学习的sHybridCNN的初始距离分布。ybridCNN的训练过程有效地使不同的配对推远,相似的配对拉近:

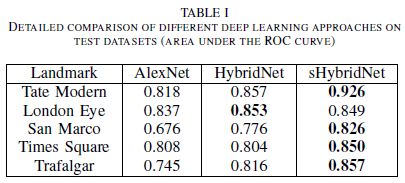
表一总结了不同测试数据集上各方法的分类精度ROC曲线(AUC)。可以看出所提出的方法始终优于其他算法,sHybridNet在平均AUC的表现要比AlexNet和HybridNet分别好11%和5%:
使用更多的图像对(特别是“难的负样本”图像对)进行训练可以进一步改善结果
对测试数据集的算法的详细评估如图4所示。从这组ROC曲线和PR曲线我们可以观察到:
与原来的AlexNet和HybridNet相比,从sHybridCNN中提取的特征在5个案例中有4个有更好的表现。同时验证了图3所示的结果,证明sHybridCNN可以有效的区分正、负对。也就是说,sHybridCNN对于新的地标图片的表现优于HybridCNN
在案例(London Eye)中,三种方法的ROC曲线几乎相似,sHybridNet的PR曲线在容易正样本对中显示出较低的精度(即PR曲线在开始时下降)。更深层的分析表明,在London Eye测试集似乎有特别多不正确的标签

为了说明在伦敦眼测试集上的表现,我们将假阳性和假阴性图像对形象化。为此,我们从两个分支的fc7层中提取特征向量,计算它们在测试数据上的欧氏距离,并对负对按升序排序,对正对按降序排序。可视化结果如图5所示。它显示了sHybridNet在伦敦眼科测试数据上遇到的难负样本和难正样本图像对

难正样本是特征距离最大的正对的例子。类似地,难负样本是距离最小的负对的例子。通过查看图5中的示例,我们可以观察到ground truth标签是不完美的,实际上大多数距离最小的负对代表相同的场景,应该标记为正对(即匹配);正对与最大的距离似乎有不正确的标签
因此我们推断用于计算ground truth标签的原始算法[2] (基于bag-of-visual-words)并不完美,这可能是许多错误分类的测试对以及PR曲线开始时下降的原因
尽管训练和测试数据的标签存在错误,可以得出这样的结论:在区分相似和不相似对方面,该网络已经得到了改进,因为我们仍然可以现实地假设,[2]提供的大多数正/负标签都是正确的
5 总结
我们评估了用于地标数据集图像匹配的孪生网络特征的性能
此网络架构能够从这样的数据中学习,使用预训练的CNN从一个相关的图像分类问题作为起点
证明了我们的方法在新地标数据集上具有很好的泛化效果
我们还观察到,潜在地不完善的地面真值标签在训练中是阻止网络学习和推广的最佳
此外,在训练中使用额外的相关数据集[26] (Visual landmark recognition from internet photo collections: A large-scale evaluation, 2014)、[27] (Lost in quantization: Improving particular object retrieval in large scale image databases, 2008) 可能会进一步提高该方法的准确性和性能