TF2.0深度学习实战(八):搭建DenseNet稠密神经网络
写在前面:大家好!我是【AI 菌】,一枚爱弹吉他的程序员。我
热爱AI、热爱分享、热爱开源! 这博客是我对学习的一点总结与思考。如果您也对深度学习、机器视觉、算法、Python、C++感兴趣,可以关注我的动态,我们一起学习,一起进步~
我的博客地址为:【AI 菌】的博客
我的Github项目地址是:【AI 菌】的Github
前言:
本专栏将分享我从零开始搭建神经网络的学习过程,注重理论与实战相结合,力争打造最易上手的小白教程。在这过程中,我将使用谷歌TensorFlow2.0框架逐一复现经典的卷积神经网络:LeNet、AlexNet、VGG系列、GooLeNet、ResNet 系列、DenseNet 系列,以及现在比较流行的:RCNN系列、SSD、YOLO系列等。
这一次我将复现非常经典的稠密神经网络DenseNet。首先在理论部分,我会依据论文对DenseNet进行一个简要的讲解。然后在实战部分,我会手把手带你搭建第一个稠密神经网络DenseNet,对Fashion MNIST数据集进行训练与分类预测。
系列教程:
实战教程:《TF2.0深度学习实战:图像分类/目标检测》
理论教程:《深度学习笔记》
资源传送门:
论文原文下载地址:《Densely Connected Convolutional Networks》
原项目地址:https://github.com/liuzhuang13/DenseNet
论文详解:DenseNet论文详解:《Densely Connected Convolutional Networks》
TensorFlow2.0实现地址:【AI 菌】的Github
温馨提示:这一篇是《TF2.0深度学习实战:图像分类》的收关之作。从下一期开始,我将开始探索《TF2.0深度学习实战:目标检测》。如果这对你有所帮助的话,可以关注我的动态!我们一起学习,一起进步!
文章目录
- 一、DenseNet详解
- 1.1 DenseNet简介
- 1.2 DenseNet创新之处
- 1.3 DenseNet网络结构
- (1) 稠密连接
- (2) 瓶颈层
- (3) 过渡层
- (4) 整体结构
- 1.4 DenseNet的性能
- (1) CIFAR 和 SVHN上的分类结果
- (2) ImageNet上的分类结果
- 二、TensorFlow2.0搭建DenseNet实战
- 2.1 数据集准备
- (1) 数据集介绍
- (2) 数据集加载
- 2.2 网络结构搭建
- (1) 搭建瓶颈层
- (2) 搭建稠密块
- (3) 搭建过渡层
- (4) 搭建整体结构
- 2.3 模型的装配与训练
- (1) 模型的装配
- (2) 模型的训练
- 2.4 测试结果与可视化
一、DenseNet详解
1.1 DenseNet简介
DenseNet来源于《Densely Connected Convolutional Networks》这篇论文,是由华人Gao Huang(康奈尔大学)、Zhuang Liu(清华大学)Laurens(Facebook人工智能研究院)等共同发表。其研究成果在2017年计算机视觉顶级会议CVPR上获得“Best Paper Awards”,而同时期的YOLOv2也只获得最佳论文鼓励奖,可见其影响力非同一般。
DenseNet在ResNet的Skip Connection的基础上进行了很大的改进,提出了稠密连接的思想,DenseNet稠密神经网络的名称也是由此而来。DenseNet在四个竞争激烈的数据集(CIFAR-10,CIFAR-100,SVHN和ImageNet)上进行了评估,证明了其在大多数方面都比最新技术有显著地改进,同时只需要较少的计算即可实现高性能。
1.2 DenseNet创新之处
- 提出了稠密连接的思想。将一个稠密块中的所有层直接相互连接,确保了网络中各层之间最大的信息流。同时减轻了梯度弥散的问题,增强了特征传播,鼓励了特征重用。
- 采用了过渡层进行下采样。这一点和ResNet有明显的区别。
- 提出了增长率k,指的是每个瓶颈层 H l H_l Hl产生的特征图个数。相对较小的增长率(比如K=12)就足以在测试的数据集上获得最先进的结果。
- 每个稠密块之后,使用压缩因子 θ \theta θ对特征图通道数进行压缩。
1.3 DenseNet网络结构
(1) 稠密连接
首先,我们将稠密连接与传统的连接方式和ResNet中的跳层连接方式做一个对比:
传统的卷积神经网络:将第 l − 1 l-1 l−1层的输出作为第 l l l层的输入,用公式可表示为: x l = H ( x l − 1 ) x_l=H(x_{l-1}) xl=H(xl−1)
深度残差网络ResNet:ResNets添加了一个捷径连接,该连接使用恒等映射绕过了非线性变换 H l H_l Hl。用公式可表示为: x l = H ( x l − 1 ) + x l − 1 x_l=H(x_{l-1})+x_{l-1} xl=H(xl−1)+xl−1
稠密卷积网络DenseNet:为了进一步改善各层之间的信息流,提出了一种不同的连接模式——稠密连接:引入了从任何层到所有后续层的直接连接。 下面图1说明了DenseNet的布局,第 l l l层接收所有先前的层 x 0 , x 1 , . . . , x l − 1 x_0, x_1,..., x_{l-1} x0,x1,...,xl−1的特征图作为输入。用公式可表示为: x l = H l ( [ x 0 , x 1 , . . . , x l − 1 ] ) x_l=H_l([x_0,x_1,...,x_ {l-1}]) xl=Hl([x0,x1,...,xl−1])
其中, [ x 0 , x 1 , . . . , x l − 1 ] [x_0,x_1,...,x_ {l-1}] [x0,x1,...,xl−1]表示将 x 0 , x 1 , . . . , x l − 1 x_0, x_1,..., x_{l-1} x0,x1,...,xl−1的特征图在通道维度上进行堆叠。
因此,一般而言,对于L层的传统卷积网络具有L个连接(每一层与其后一层之间一个连接),而稠密神经网络具有 L ( L + 1 ) / 2 L(L + 1)/ 2 L(L+1)/2 个直接连接。

DenseNet与ResNet的连接方式的差异:
ResNet的连接方式是,将通道数相同的主路输出 F ( x ) F(x) F(x)与支路恒等映射x identify连接,即对应通道上的像素值进行相加。详见:TF2.0深度学习实战(七):手撕深度残差网络ResNet
DenseNet的连接方式是,将size相同的feature maps直接在通道维度上进行堆叠。
稠密连接的特点:
该网络以前馈方式将每一层连接到其他每一层。对于每一层,所有先前层的特征图都用作输入,而其自身的特征图则用作所有后续层的输入。这种连接方式确保了网络中各层之间最大的信息流。
稠密连接的优点:
- 它减轻了梯度弥散的问题,增强了特征传播,鼓励了特征重用,并大大减少了参数数量。
- 同时它在整个网络中改善了信息流和梯度,使得模型更易于训练。
- 除此之外,还观察到稠密连接具有正则化效果,从而减少了训练集较小的任务的过度拟合。
(2) 瓶颈层
瓶颈结构BottleNeck的思想其实在ResNet中已经提到过,这里使用是一种降维的思想。具体可参见:TF2.0深度学习实战(七):手撕深度残差网络ResNet
那么在DenseNet中瓶颈层的具体形式是怎样的呢?
最直观地表述,其实瓶颈层可看作是图1中的 H l H_l Hl,它是由批量归一化BN层、ReLU激活函数、3×3卷积层构成。如果对于传统的BN-ReLU-Conv的神经网络结构还不清楚,建议先加个餐:深度学习笔记(一):卷积层+激活函数+池化层+全连接层
为了减少输入特征图的数量,从而提高计算效率,于是在每个3×3卷积之前引入1×1卷积作为瓶颈层。改进之后的瓶颈结构 H l H_l Hl就变成了:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)。其中,1×1卷积核个数是4k,3×3卷积核个数是k。在实验中,我们称这种结构为DenseNet-B。
注:k在论文中是增长率,指的是每个瓶颈层 H l H_l Hl产生的特征图个数。具体细节,可参见:DenseNet论文详解:《Densely Connected Convolutional Networks》
(3) 过渡层

如上图2所示,是图像预测网络结构的整体示意简图。其中,Dense Block表示的就是由若干个瓶颈层经过稠密连接而成的稠密块;每两个稠密块之间,用红色方框标识的部分就是过渡层。
过渡层的结构很简单,它包括:批量归一化BN、1×1卷积层,然后是2×2平均池化层。
过渡层的作用是下采样。下采样层是卷积神经网络的重要组成部分,这些层可以用来更改特征图的大小。由于稠密块中各层输入要保持相同的size才能进行稠密连接,所以不便进行下采样;因此过渡层主要用作下采样,采取的方式是:通过步长为2的2×2平均池化层,进行2倍下采样。
为了进一步提高模型的紧凑性,可以通过压缩减少过渡层的特征图数量。如果一个周密块包含m个特征图,则让以下过渡层生成θm个输出特征图,也就是让过渡层中的1×1卷积核个数为θm,其中0 <θ≤1称为压缩因子。 当θ= 1时,跨过渡层的特征图数量保持不变。 我们将θ<1的DenseNet称为DenseNet-C,并在实验中将θ= 0.5;当同时使用θ<1的瓶颈和过渡层时,我们将模型称为DenseNet-BC。
(4) 整体结构

上表表示的是,应对ImageNe数据集t的DenseNet系列的整体网络结构。表中给出了DenseNet-121、DenseNet-169、DenseNet-201、DenseNet-264四种网络结构。这四种网络结构框架相同,仅有的差异在于:每个Dense Block中瓶颈层的个数不一样。
下面,我以DenseNet-121为例,对其结构进行分析:
- 网络输入:224×224×3的彩色图像
- 第一层:BN-ReLU-Conv(7×7)-MaxPooling(3×3)
- 中间层:稠密块(1)-过渡层(1)-稠密块(2)-过渡层(2)-稠密块(3)-过渡层(3)-稠密块(4)
- 分类层:全局平均池化(7×7)-全连接层(1000个节点)-softmax
1.4 DenseNet的性能
(1) CIFAR 和 SVHN上的分类结果
该实验训练具有不同深度L和增长率k的DenseNet。表2中显示了CIFAR和SVHN的主要结果。为了突出总体趋势,用粗体标记所有优于现有技术水平的结果,用蓝色标记总体最佳结果。

从上表可得出以下优点:
- 精确度明显提升。最明显的趋势来自表2的最下面一行,该表表明L=190和k = 40的DenseNet-BC在所有CIFAR数据集上的性能始终优于现有的最新技术。它在C10 +上的错误率是3.46%,在C100 +上的错误率是17.18%,远低于Wide ResNet结构所实现的错误率。在SVHN上,具有Dropout的L = 100和k = 24的DenseNet也超过了Wide ResNet所获得的当前最佳结果。
- DenseNet可以利用更大和更深层模型来增强表示能力。C10 +和C100 +的实验结果栏对此进行了最好的说明。在C10 +上,随着参数数量从1.0M增加到7.0M到27.2M,误差从5.24%降至4.10%,最后降至3.74%。在C100 +上,我们观察到了类似的趋势。
注:C10 +、C100 +分别表示Cifar10和Cifar100经过数据增强后的数据集。
除此之外,DenseNet在参数有效性和防止过拟合方面也有更多的优势。具体可见:DenseNet论文详解:《Densely Connected Convolutional Networks》
(2) ImageNet上的分类结果
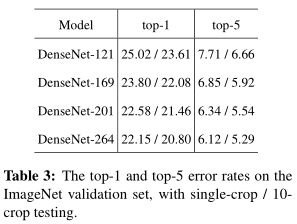
表3中表示ImageNet上DenseNet的single-crop和10-crop验证错误率。
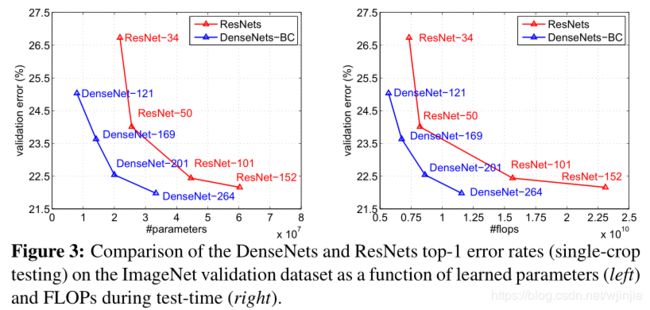
图3显示了DenseNet和ResNet的single-crop top-1验证错误与参数数量(左)和FLOPs(右)的函数关系。
结果表明,DenseNet可以与最先进的ResNet媲美,而所需的参数和计算量却要少得多,以实现可比的性能。
例如,如图3(左)所示,具有20M参数的DenseNet-201模型产生的验证错误与具有40M以上参数的101层ResNet产生类似的验证错误。从图3(右)也可以看到类似的趋势,该图将验证误差绘制为FLOP数量的函数:DenseNet-201使用与ResNet-50等同的参数量能到达ResNet-101的性能,而ResNet-101需要的计算量是DenseNet-201的两倍。
二、TensorFlow2.0搭建DenseNet实战
2.1 数据集准备
(1) 数据集介绍
本次实验采用的是Fashion MNIST数据集。Fashion MNIST是一个定位在比MNIST识别问题更复杂的数据集,它的设定与MNIST几乎完全一样,包含了 10 类不同类型的衣服、鞋子、包等灰度图片,图片大小为28x28,共 70000 张图片,其中 60000 张用于训练集,10000 张用于测试集,如图下图所示,每行对应一种类别。
对MNIST数据集还不太了解的同学,可以参考这篇博文中的介绍:TF2.0深度学习实战(一):分类问题之手写数字识别

(2) 数据集加载
在tensorflow2.0官方API中提供了自动加载Fashion MNIST数据集的函数,我们直接使用即可。
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = x_train.reshape((60000, 28, 28, 1)).astype('float32') / 255
x_test = x_test.reshape((10000, 28, 28, 1)).astype('float32') / 255
如果你想对论文中提到的cifar10数据集进行实验,则改用如下代码:
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train = x_train.reshape((50000, 32, 32, 1)).astype('float32') / 255
x_test = x_test.reshape((10000, 32, 32, 1)).astype('float32') / 255
由于cifar10数据集中是3通道彩色图片,所以训练的时间会更久一些。
2.2 网络结构搭建
(1) 搭建瓶颈层
# 瓶颈层,相当于每一个稠密块中若干个相同的H函数
class BottleNeck(layers.Layer):
# growth_rate对应的是论文中的增长率k,指经过一个BottleNet输出的特征图的通道数;drop_rate指失活率。
def __init__(self, growth_rate, drop_rate):
super(BottleNeck, self).__init__()
self.bn1 = layers.BatchNormalization()
self.conv1 = layers.Conv2D(filters=4 * growth_rate, # 使用1*1卷积核将通道数降维到4*k
kernel_size=(1, 1),
strides=1,
padding="same")
self.bn2 = layers.BatchNormalization()
self.conv2 = layers.Conv2D(filters=growth_rate, # 使用3*3卷积核,使得输出维度(通道数)为k
kernel_size=(3, 3),
strides=1,
padding="same")
self.dropout = layers.Dropout(rate=drop_rate)
# 将网络层存入一个列表中
self.listLayers = [self.bn1,
layers.Activation("relu"),
self.conv1,
self.bn2,
layers.Activation("relu"),
self.conv2,
self.dropout]
def call(self, x):
y = x
for layer in self.listLayers.layers:
y = layer(y)
# 每经过一个BottleNet,将输入和输出按通道连结。作用是:将前l层的输入连结起来,作为下一个BottleNet的输入。
y = layers.concatenate([x, y], axis=-1)
return y
(2) 搭建稠密块
# 稠密块,由若干个相同的瓶颈层构成
class DenseBlock(layers.Layer):
# num_layers表示该稠密块存在BottleNet的个数,也就是一个稠密块的层数L
def __init__(self, num_layers, growth_rate, drop_rate=0.5):
super(DenseBlock, self).__init__()
self.num_layers = num_layers
self.growth_rate = growth_rate
self.drop_rate = drop_rate
self.listLayers = []
# 一个DenseBlock由多个相同的BottleNeck构成,我们将它们放入一个列表中。
for _ in range(num_layers):
self.listLayers.append(BottleNeck(growth_rate=self.growth_rate, drop_rate=self.drop_rate))
def call(self, x):
for layer in self.listLayers.layers:
x = layer(x)
return x
(3) 搭建过渡层
class TransitionLayer(layers.Layer):
# out_channels代表输出通道数
def __init__(self, out_channels):
super(TransitionLayer, self).__init__()
self.bn = layers.BatchNormalization()
self.conv = layers.Conv2D(filters=out_channels,
kernel_size=(1, 1),
strides=1,
padding="same")
self.pool = layers.MaxPool2D(pool_size=(2, 2), # 2倍下采样
strides=2,
padding="same")
def call(self, inputs):
x = self.bn(inputs)
x = tf.keras.activations.relu(x)
x = self.conv(x)
x = self.pool(x)
return x
(4) 搭建整体结构
# DenseNet整体网络结构
class DenseNet(tf.keras.Model):
# num_init_features:代表初始的通道数,即输入第一个稠密块时的通道数
# growth_rate:对应的是论文中的增长率k,指经过一个BottleNet输出的特征图的通道数
# block_layers:每个稠密块中的BottleNet的个数
# compression_rate:压缩因子,其值在(0,1]范围内
# drop_rate:失活率
def __init__(self, num_init_features, growth_rate, block_layers, compression_rate, drop_rate):
super(DenseNet, self).__init__()
# 第一层,7*7的卷积层,2倍下采样。
self.conv = layers.Conv2D(filters=num_init_features,
kernel_size=(7, 7),
strides=2,
padding="same")
self.bn = layers.BatchNormalization()
# 最大池化层,3*3卷积核,2倍下采样
self.pool = layers.MaxPool2D(pool_size=(3, 3), strides=2, padding="same")
# 稠密块 Dense Block(1)
self.num_channels = num_init_features
self.dense_block_1 = DenseBlock(num_layers=block_layers[0], growth_rate=growth_rate, drop_rate=drop_rate)
# 该稠密块总的输出的通道数
self.num_channels += growth_rate * block_layers[0]
# 对特征图的通道数进行压缩
self.num_channels = compression_rate * self.num_channels
# 过渡层1,过渡层进行下采样
self.transition_1 = TransitionLayer(out_channels=int(self.num_channels))
# 稠密块 Dense Block(2)
self.dense_block_2 = DenseBlock(num_layers=block_layers[1], growth_rate=growth_rate, drop_rate=drop_rate)
self.num_channels += growth_rate * block_layers[1]
self.num_channels = compression_rate * self.num_channels
# 过渡层2,2倍下采样,输出:14*14
self.transition_2 = TransitionLayer(out_channels=int(self.num_channels))
# 稠密块 Dense Block(3)
self.dense_block_3 = DenseBlock(num_layers=block_layers[2], growth_rate=growth_rate, drop_rate=drop_rate)
self.num_channels += growth_rate * block_layers[2]
self.num_channels = compression_rate * self.num_channels
# 过渡层3,2倍下采样
self.transition_3 = TransitionLayer(out_channels=int(self.num_channels))
# 稠密块 Dense Block(4)
self.dense_block_4 = DenseBlock(num_layers=block_layers[3], growth_rate=growth_rate, drop_rate=drop_rate)
# 全局平均池化,输出size:1*1
self.avgpool = layers.GlobalAveragePooling2D()
# 全连接层,进行10分类
self.fc = layers.Dense(units=10, activation=tf.keras.activations.softmax)
def call(self, inputs):
x = self.conv(inputs)
x = self.bn(x)
x = tf.keras.activations.relu(x)
x = self.pool(x)
x = self.dense_block_1(x)
x = self.transition_1(x)
x = self.dense_block_2(x)
x = self.transition_2(x)
x = self.dense_block_3(x)
x = self.transition_3(x,)
x = self.dense_block_4(x)
x = self.avgpool(x)
x = self.fc(x)
return x
2.3 模型的装配与训练
(1) 模型的装配
在模型装配过程中,采用的是随机梯度下降法SGD,sparse_categorical_crossentropy交叉熵损失函数,以及accuracy测试精确度。
mynet.compile(loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.SGD(),
metrics=['accuracy'])
(2) 模型的训练
在模型的训练过程中,一次喂入64张图片进行训练,对整个数据集训练5遍。
history = mynet.fit(x_train, y_train,
batch_size=64,
epochs=5,
validation_split=0.2)
2.4 测试结果与可视化
由于时间关系这里只训练了5个epochs,在训练集和验证集上分别达到如下测试精度:

大家可以改变多训练几个epochs,应该可以达到更好的效果。
如果想得到在测试集和训练集上训练精确度的变化曲线,可加入如下可视化操作:
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
等训练完后,可自动绘出测试集/训练集上的测试精确度随训练轮数epochs的变化曲线:

本次教程就到这里啦,代码已上传Github。想实战的盆友,可以戳戳我的github项目地址:【AI 菌】的Github
最后就要和大家说再见啦!如果这篇文章对您有帮助的话,请点个赞支持一下呗,谢谢!