干货 | 通透理解Elasticsearch聚合
使用Elasticsearch的过程中,除了全文检索,或多或少会做统计操作,而做统计操作势必会使用Elasticsearch聚合操作。
类似mysql中group by的terms聚合用的最多,但当遇到复杂的聚合操作时,往往会捉襟见肘、不知所措…
这也是社区中聚合操作几乎每天都会被提问的原因。
本文基于官方文档,梳理出聚合的以下几个核心问题,目的:将Elasticsearch的聚合结合实际场景说透。
1、Elasticsearch聚合最直观展示
区别于倒排索引的key value的全文检索,聚合两个示例如下:
如下图,是基于某特定分类的聚合统计结果。

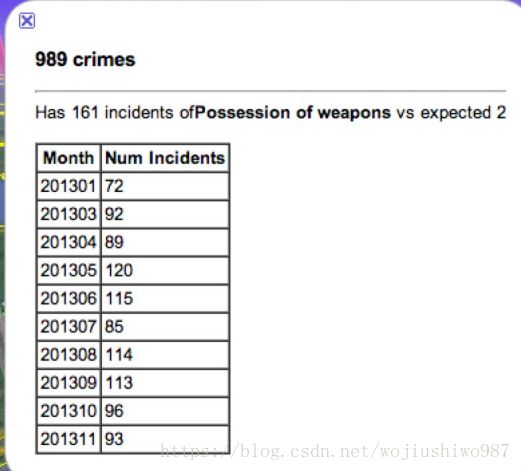
如下图:是基于月份的聚合统计结果。
2、Elasticsearch聚合定义
聚合有助于基于搜索查询提供聚合数据。 它基于称为聚合的简单构建块,可以组合以构建复杂的数据。
基本语法结构如下:
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}
3、Elasticsearch聚合分类

3.1 分类1:Metric聚合
基于一组文档进行聚合。所有的文档在一个检索集合里,文档被分成逻辑的分组。
类比Mysql中的: MIN(), MAX(), STDDEV(), SUM() 操作。
单值Metric
|
v
SELECT AVG(price) FROM products
多值Metric
| |
v v
SELECT MIN(price), MAX(price) FROM products
Metric聚合的DSL类比实现:
{
"aggs":{
"avg_price":{
"avg":{
"field":"price"
}
}
}
}
Metric聚合操作对比:
| Aggregation | Elasticsearch | MySQL |
|---|---|---|
| Avg | Yes | Yes |
| Cardinality——去重唯一值 | Yes (Sample based) | Yes (Exact)——类似:distinct |
| Extended Stats | Yes | StdDev bounds missing |
| Geo Bounds | Yes | for future blog post |
| Geo Centroid | Yes | for future blog post |
| Max | Yes | Yes |
| Percentiles | Yes | Complex SQL or UDF |
| Percentile Ranks | Yes | Complex SQL or UDF |
| Scripted | Yes | No |
| Stats | Yes | Yes |
| Top Hits——很重要,易被忽视 | Yes | Complex |
| Value Count | Yes | Yes |
其中,Top hits子聚合用于返回分组中Top X匹配结果集,且支持通过source过滤选定字段值。
分类2:Bucketing聚合
基于检索构成了逻辑文档组,满足特定规则的文档放置到一个桶里,每一个桶关联一个key。
类比Mysql中的group by操作,
Mysql使用举例:
基于size 分桶 ...、
SELECT size COUNT(*) FROM products GROUP BY size
+----------------------+
| size | COUNT(*) |
+----------------------+
| S | 123 | <--- set of rows with size = S
| M | 456 |
| ... | ... |
bucket聚合的DSL类比实现:
{
"query": {
"match": {
"title": "Beach"
}
},
"aggs": {
"by_size": {
"terms": {
"field": "size"
}
},
"by_material": {
"terms": {
"field": "material"
}
}
}
}
Bucketing聚合对比
| Aggregation | Elasticsearch | MySQL |
|---|---|---|
| Childen——父子文档 | Yes | for future blog post |
| Date Histogram——基于时间分桶 | Yes | Complex |
| Date Range | Yes | Complex |
| Filter | Yes | n/a (yes) |
| Filters | Yes | n/a (yes) |
| Geo Distance | Yes | for future blog post |
| GeoHash grid | Yes | for future blog post |
| Global | Yes | n/a (yes) |
| Histogram | Yes | Complex |
| IPv4 Range | Yes | Complex |
| Missing | Yes | Yes |
| Nested | Yes | for future blog post |
| Range | Yes | Complex |
| Reverse Nested | Yes | for future blog post |
| Sampler | Yes | Complex |
| Significant Terms | Yes | No |
| Terms——最常用 | Yes | Yes |
分类3:Pipeline聚合
对聚合的结果而不是原始数据集进行操作。
想象一下,你有一个日间交易的网上商店,想要了解所有产品的按照库存日期分组的平均价格。
在SQL中你可以写:
SELECT in_stock_since, AVG(price) FROM products GROUP BY in_stock_since。
ES使用举例:
以下Demo实现更复杂,按月统计销售额,并统计出月销售额>200的信息。
下一节详细给出DSL,不再重复。
分类4:Matrix聚合
ES6.4官网释义:此功能是实验性的,可在将来的版本中完全更改或删除。
3、Elasticsearch聚合完整举例
3.1 步骤1:动态Mapping,导入完整数据
POST _bulk
{"index":{"_index":"cars","_type":"doc","_id":"1"}}
{"name":"bmw","date":"2017-06-01", "color":"red", "price":30000}
{"index":{"_index":"cars","_type":"doc","_id":"2"}}
{"name":"bmw","date":"2017-06-30", "color":"blue", "price":50000}
{"index":{"_index":"cars","_type":"doc","_id":"3"}}
{"name":"bmw","date":"2017-08-11", "color":"red", "price":90000}
{"index":{"_index":"cars","_type":"doc","_id":"4"}}
{"name":"ford","date":"2017-07-15", "color":"red", "price":20000}
{"index":{"_index":"cars","_type":"doc","_id":"5"}}
{"name":"ford","date":"2017-07-01", "color":"blue", "price":40000}
{"index":{"_index":"cars","_type":"doc","_id":"6"}}
{"name":"bmw","date":"2017-08-01", "color":"green", "price":10000}
{"index":{"_index":"cars","_type":"doc","_id":"7"}}
{"name":"jeep","date":"2017-07-08", "color":"red", "price":110000}
{"index":{"_index":"cars","_type":"doc","_id":"8"}}
{"name":"jeep","date":"2017-08-25", "color":"red", "price":230000}
3.2 步骤2:确认Mapping
GET cars/_mapping
3.3 步骤3:Matric聚合实现
求车的平均价钱。
POST cars/_search
{
"size": 0,
"aggs": {
"avg_grade": {
"avg": {
"field": "price"
}
}
}
}
3.4 步骤4:bucket聚合与子聚合实现
按照车品牌分组,组间按照车颜色再二次分组。
POST cars/_search
{
"size": 0,
"aggs": {
"name_aggs": {
"terms": {
"field": "name.keyword"
},
"aggs": {
"color_aggs": {
"terms": {
"field": "color.keyword"
}
}
}
}
}
}
3.5 步骤5:Pipeline聚合实现
按月统计销售额,并统计出总销售额大于200000的月份信息。
POST /cars/_search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "price"
}
},
"sales_bucket_filter": {
"bucket_selector": {
"buckets_path": {
"totalSales": "total_sales"
},
"script": "params.totalSales > 200000"
}
}
}
}
}
}
4、Elasticsearch聚合使用指南
认知前提:知道Elasticsearch聚合远比Mysql中种类要多,可实现的功能点要多。
遇到聚合问题,基于4个分类,查询对应的官网API信息。
以最常见场景为例:
- 确定是否是分组group by 操作,如果是,使用bucket聚合中的terms聚合实现;
- 确定是否是按照时间分组操作,如果是,使用bucket聚合中date_histogram的聚合实现;
- 确定是否是分组,组间再分组操作,如果是,使用bucket聚合中terms聚合内部再terms或者内部top_hits子聚合实现;
- 确定是否是求最大值、最小值、平均值等,如果是,使用Metric聚合对应的Max, Min,AVG等聚合实现;
- 确定是否是基于聚合的结果条件进行判定后取结果,如果是,使用pipline聚合结合其他聚合综合实现;
多尝试,多在kibana的 dev tool部分多验证。
参考:
1、https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
2、http://blog.ulf-wendel.de/2016/aggregation-features-elasticsearch-vs-mysql-vs-mongodb/
3、https://elasticsearch.cn/article/629

打造Elasticsearch基础、进阶、实战第一公众号!