PixelRNN—VAE—GAN/cGAN/WGAN
-
-
- 一、PixelRNN
-
- 1.1 根据图像生成像素
-
- 二、Variational Auto-encoder (VAE)
- 三、Generative Adversarial Network(GAN)
-
- 3.1 Conditional Adversarial Nets
- 3.2 深度卷积对抗生成网络(DCGAN)
- DCGAN 模型结构
- 3.3 WGAN
- 3.4 WGAN-GP (improved wgan)
-
- 一、PixelRNN
-
一、PixelRNN
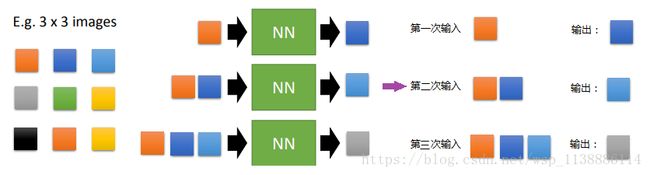
1.1 根据图像生成像素

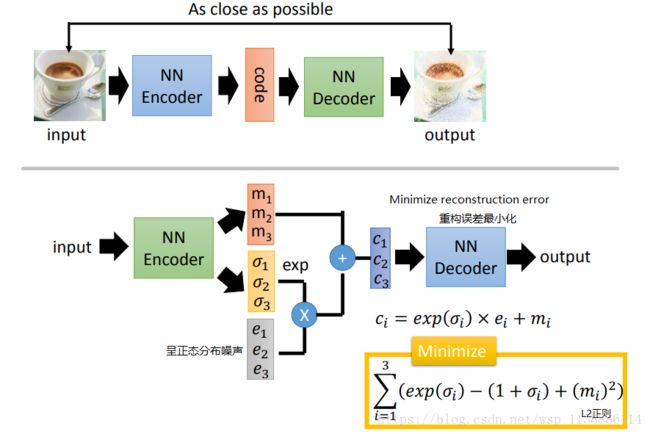
二、Variational Auto-encoder (VAE)
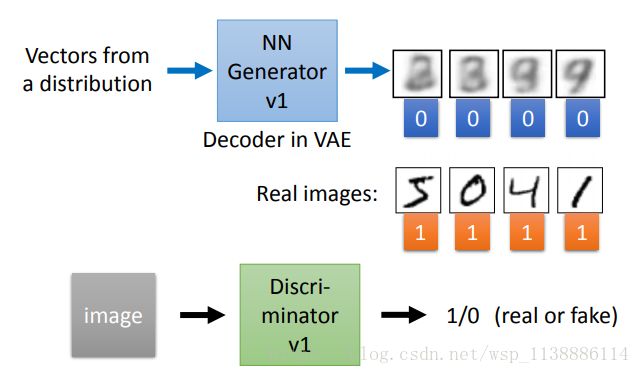
三、Generative Adversarial Network(GAN)
Generative Adversarial Nets是由Goodfellow提出的一种训练生成式模型的新方法。
- 包含了两个“对抗”的模型:
-
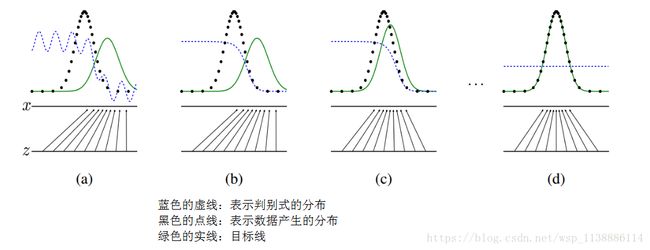
生成模型(G)用于捕捉数据分布,
判别模型(D)用于估计一个样本来自与真实数据而非生成样本的概率。
为了学习在真实数据集x上的生成分布 Pg P g :
生成模型 G 构建一个从先验分布 Pz(z) P z ( z ) 到数据空间的映射函数 G(z;θg) G ( z ; θ g ) 。
判别模型 D 的输入是真实图像或者生成图像, D(x;θd) D ( x ; θ d ) 输出一个标量,表示输入样本来自训练样本(而非生成样本)的概率。
- 训练过程:
-
模型G和D同时训练:
固定判别模型D,调整G的参数使得 log(1−D(G(z)) l o g ( 1 − D ( G ( z ) ) 的期望最小化;
固定生成模型G,调整D的参数使得 logD(X)+log(1−D(G(z))) l o g D ( X ) + l o g ( 1 − D ( G ( z ) ) ) 的期望最大化。
这个优化过程可以归结为一个“二元极小极大博弈(minimax two-player game)”问题

3.1 Conditional Adversarial Nets
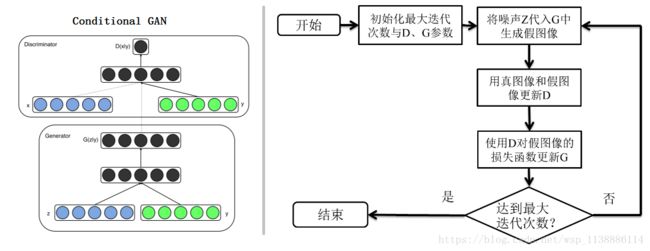
- 条件生成式对抗网络(CGAN)是对原始GAN的一个扩展。
- 生成器和判别器都增加额外信息y为条件, y可以使任意信息,例如类别信息,或者其他模态的数据。
- 如Figure 1所示,通过将额外信息y输送给判别模型和生成模型,作为输入层的一部分,从而实现条件GAN。
-
在生成模型中,先验输入噪声 p(z) 和条件信息y联合组成了联合隐层表征。对抗训练框架在隐层表征的组成方式方面相当地灵活。 类似地,条件GAN的目标函数是带有条件概率的二人极小极大值博弈(two-player minimax game ):
minGmaxGV(D,G)=Ex∼pdata(x))[logD(x|y)]+Ez∼pz(z))[log(1−D(G(z|y)))] min G max G V ( D , G ) = E x ∼ p d a t a ( x ) ) [ l o g D ( x | y ) ] + E z ∼ p z ( z ) ) [ l o g ( 1 − D ( G ( z | y ) ) ) ]
3.2 深度卷积对抗生成网络(DCGAN)
DCGAN的原理和GAN是一样的,它只是把上述的G和D换成了两个卷积神经网络(CNN)。
但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变如下:
取消所有pooling层。G网络中使用反卷积(Deconvolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
D和G中均使用batch normalization
去掉FC层,使网络变为全卷积网络
G网络中使用ReLU作为激活函数,最后一层使用tanh
D网络中使用LeakyReLU作为激活函数,最后一层使用softmax
DCGANs的基本架构就是使用几层“反卷积”(Deconvolution)网络。“反卷积”类似于一种反向卷积,这跟用反向传播算法训练监督的卷积神经网络(CNN)是类似的操作。
DCGAN贡献就在于:
- 为CNN的网络拓扑结构设置了一系列的限制来使得它可以稳定的训练。
- 使用得到的特征表示来进行图像分类,得到比较好的效果来验证生成的图像特征表示的表达能力
- 对GAN学习到的filter进行了定性的分析。
- 展示了生成的特征表示的向量计算特性。
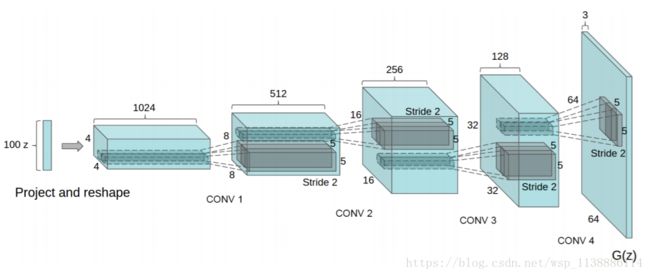
DCGAN 模型结构
模型结构上需要做如下几点变化:
- 将pooling层convolutions替代,其中,在discriminator上用strided convolutions替代,在generator上用fractional-strided convolutions替代。
- 在generator和discriminator上都使用batchnorm。
- 解决初始化差的问题
- 帮助梯度传播到每一层
- 防止generator把所有的样本都收敛到同一个点。
- 直接将BN应用到所有层会导致样本震荡和模型不稳定,通过在generator输出层和-discriminator输入层不采用BN可以防止这种现象。
- 移除全连接层
global pooling增加了模型的稳定性,但伤害了收敛速度。 - 在generator的除了输出层外的所有层使用ReLU,输出层采用tanh。
- 在discriminator的所有层上使用LeakyReLU。
训练细节
- 预处理环节,将图像scale到tanh的[-1, 1]。
- mini-batch训练,batch size是128.
- 所有的参数初始化由(0, 0.02)的正态分布中随即得到
- LeakyReLU的斜率是0.2.
- 虽然之前的GAN使用momentum来加速训练,DCGAN使用调好超参的Adam optimizer。
- learning rate=0.0002
- 将momentum参数beta从0.9降为0.5来防止震荡和不稳定。
3.3 WGAN
【paper】: https://arxiv.org/abs/1701.07875
【GitHub】:
https://github.com/hwalsuklee/tensorflow-generative-model-collections
https://github.com/Zardinality/WGAN-tensorflow
与DCGAN不同,WGAN主要从损失函数的角度对GAN做了改进,损失函数改进之后的WGAN即使在全链接层上也能得到很好的表现结果,
- WGAN对GAN的改进主要有:
-
◆ 判别器最后一层去掉sigmoid
◆ 生成器和判别器的loss不取log
◆ 对更新后的权重强制截断到一定范围内,比如[-0.01,0.01],以满足论文中提到的 lipschitz 连续性条件。
◆ 论文中也推荐使用SGD, RMSprop等优化器,不要基于使用动量的优化算法,比如adam,但是就我目前来说,训练GAN时,我还是adam用的多一些。
从上面看来,WGAN好像在代码上很好实现,基本上在原始GAN的代码上不用更改什么,但是它的作用是巨大的
◆ WGAN理论上给出了GAN训练不稳定的原因,即交叉熵(JS散度)不适合衡量具有不相交部分的分布之间的距离,转而使用wassertein距离去衡量生成数据分布和真实数据分布之间的距离,理论上解决了训练不稳定的问题。
◆ 解决了模式崩溃的(collapse mode)问题,生成结果多样性更丰富。
◆ 对GAN的训练提供了一个指标,此指标数值越小,表示GAN训练的越差,反之越好。可以说之前训练GAN完全就和买彩票一样,训练好了算你中奖,没中奖也不要气馁,多买几注吧。
有关GAN和WGAN的解释,可以参考链接:https://zhuanlan.zhihu.com/p/25071913
总的来说,GAN中交叉熵(JS散度)不适合衡量生成数据分布和真实数据分布的距离,如果通过优化JS散度训练GAN会导致找不到正确的优化目标,所以,WGAN提出使用wassertein距离作为优化方式训练GAN,但是数学上和真正代码实现上还是有区别的,使用Wasserteion距离需要满足很强的连续性条件—lipschitz连续性,为了满足这个条件,作者使用了将权重限制到一个范围的方式强制满足lipschitz连续性,但是这也造成了隐患,接下来会详细说。另外说实话,虽然理论证明很漂亮,但是实际上训练起来,以及生成结果并没有期待的那么好。
注:Lipschitz限制是在样本空间中,要求判别器函数D(x)梯度值不大于一个有限的常数K,通过权重值限制的方式保证了权重参数的有界性,间接限制了其梯度信息。
3.4 WGAN-GP (improved wgan)
【paper】:https://arxiv.org/abs/1704.00028
【GitHub】:
https://link.zhihu.com/?target=https%3A//github.com/igul222/improved_wgan_training
https://github.com/caogang/wgan-gp
WGAN-GP是WGAN之后的改进版,主要还是改进了连续性限制的条件,因为,作者也发现将权重剪切到一定范围之后,比如剪切到[-0.01,+0.01]后,发生了这样的情况,如下图左边表示。
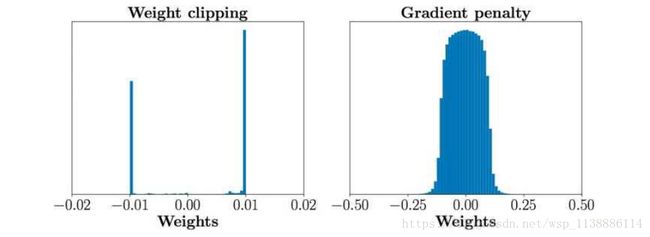
发现大多数的权重都在-0.01 和0.01上,这就意味了网络的大部分权重只有两个可能数,对于深度神经网络来说不能充分发挥深度神经网络的拟合能力,简直是极大的浪费。并且,也发现强制剪切权重容易导致梯度消失或者梯度爆炸,梯度消失很好理解,就是权重得不到更新信息,梯度爆炸就是更新过猛了,权重每次更新都变化很大,很容易导致训练不稳定。梯度消失与梯度爆炸原因均在于剪切范围的选择,选择过小的话会导致梯度消失,如果设得稍微大了一点,每经过一层网络,梯度变大一点点,多层之后就会发生梯度爆炸 。为了解决这个问题,并且找一个合适的方式满足lipschitz连续性条件,作者提出了使用梯度惩罚(gradient penalty)的方式以满足此连续性条件,其结果如上图右边所示。
- WGAN-GP的贡献是:
-
◆ 提出了一种新的lipschitz连续性限制手法—梯度惩罚,解决了训练梯度消失梯度爆炸的问题。
◆ 比标准WGAN拥有更快的收敛速度,并能生成更高质量的样本
◆ 提供稳定的GAN训练方式,几乎不需要怎么调参,成功训练多种针对图片生成和语言模型的GAN架构。
鸣谢与详情
GAN论文研读(一)—–GAN与cGAN:https://blog.csdn.net/opensuse1995/article/details/79233101
http://blog.otoro.net/2016/04/01/generating-large-images-from-latent-vectors/
https://blog.csdn.net/opensuse1995/article/details/79233101
https://www.cnblogs.com/wangxiaocvpr/p/5744947.html
深度卷积对抗生成网络(DCGAN):https://blog.csdn.net/stdcoutzyx/article/details/53872121
DCGAN文献:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS