cascade自己训练级联分类器(人脸检测)
cascade训练简介
后面有详细解释,和步骤代码的实现,可能需要简单修改,建议代码自己先写着试试
训练步骤
-
下载文件包
opencv。这里的opencv是指编译好的.exe文件,不是需要编译的source源码文件。建议下载3.4版本的,最新版可能训练步骤不同,这里我没有做仔细学习,毕竟新手,等以后熟练了再做解释。
windows版本:官网下载
iOS版本:官网下载
Android版本:官网下载
官网地址:https://opencv.org/releases/
但是有一点,官网嘛,外网比较慢,我下载了一晚上,也可以去csdn下载,就是需要金币,不太值。 -
样本收集
样本收集是个费时费力的活,当时在朋友圈喊了一声,同学把淘宝弄来的给我了,实际上符合条件的还是不够用的,所以大家可以找找其他图片。
样本分为正负样本集。
**正样本:**人脸图像,数量在一般在2k以上
**负样本:**非人脸任何图像,数量一般在5k以上
正负样本越多越好,当然,负样本要远大于正样本数量。网上对正负样本数量比没有详细阐释,我认为 1 : 3 1:3 1:3的样本比例就可以 -
准备文件夹
这一步好说,让准备文件夹,主要是命令和文件夹有关,所以这一步要求大家和我准备一样的文件夹,如果你熟悉命令可以另说。
- cascade文件夹:这是整个环境的文件夹,下面的文件夹和文件除非特殊特殊声明,都存放在这个文件夹下
- neg文件夹:用于存放负样本集
- pos文件夹:用于存放正样本集
- opencv_world341.dll:该文件存放在步骤1下载好的文件夹中:
G:\opencv\build\x64\vc15\bin,把它复制粘贴到cascade文件夹下 - opencv_creaesamples.exe:该文件存放路径同上
- opencv_traincascade.exe:该文件存放路径同上
- xml文件夹:用于存放训练好的
.xml文件 - 人脸图像一张:用于后期测试
- 修改正负样本照片
- 正样本:
- 没必要修改成灰度图
- 大小:有一致性的要求,比如都设置成 256 ∗ 256 256*256 256∗256的,但是注意一定要一致。
- 数量:2000以上
- 图片类型,选择 . B M P .BMP .BMP格式的图片(因为我找不到那么多 . b m p .bmp .bmp格式的图片,所以只能用 . j p g .jpg .jpg格式。没试过二者区别,论文中说“ . j p g .jpg .jpg格式的图片压缩有‘伪影’”,建议有条件的童鞋搞点 . b m p .bmp .bmp格式的图片)
- 负样本:
- 大小:一定要超过正样本大小,因为我们要将负样本作为背景的,所以负样本一定比正样本尺寸大
- 数量:5000以上
- 分别在
pos文件夹和neg文件夹下添加.txt文件pos.txt和neg.txt。然后,八仙过海,各显神通,将文件填充如下:
neg.txt:文件路径+图像名写入文件中(相对路径)
可以用ddos的命令:
dir /b /s > neg.txt
pos.txt:将图像名和检测人脸尺寸写入文件

这里我是取巧,选择的正样本都是经过官方的xml文件检测过的人脸区域。
即用官方训练好的 x m l xml xml文件对正样本进行筛选和人脸检测,再写入 p o s . t x t pos.txt pos.txt文件中,代码一会给。
现在对上述参数进行解释:
1.jpg 1 69 66 113 113
- 1.jpg: 图片名称,当然,如果你是bmp图片就用bmp后缀
- 1: 图片中人脸的个数,由于我的人脸图片选取了 l f w lfw lfw训练集,里面有各种图片,不好分类,于是我用代码把没有检测到人脸的图片和检测出多人脸的图片进行筛选剔除,剩下的只有一张人脸了 。如果图片中有两张人脸就写2,三张就写3,以此类推。
- 69: 我们需要把人脸圈出来,因此69是人脸的x坐标
- 66: 同样,66是人脸的y坐标
- 113:人脸的宽度
- 113:人脸的高度
以上则确定了人脸的范围
如果是两张人脸,那就在后面加上第二张脸的范围就行,如下图。

注意:将文件末尾的多余字符neg.txt和pos.txt删掉
- 开始生成
pos.vec文件,进入cascade文件夹中,输入命令:
opencv_createsamples -info pos/pos.txt -vec pos.vec -bg neg/neg.txt -num 2000 -w 24 -h 24
这是vec文件的生成。
- 后面的参数 − n u m 2000 -num 2000 −num2000就是你的正样本集的数量
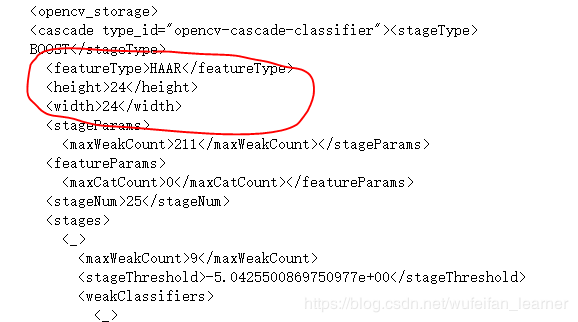
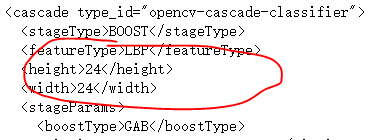
- − w , − h -w,-h −w,−h是滑动窗口的大小,滑动窗口的大小会影响效率。网上说,HAAR特征用 20 ∗ 20 20*20 20∗20, LBP特征用 24 ∗ 24 24*24 24∗24,HOG特征用 64 ∗ 64 64*64 64∗64,但是我翻看了官方训练好的文件,发现LBP和HAAR都用的是 24 ∗ 24 24*24 24∗24的窗口尺寸。“不要看他说了什么,要看他做了什么”,那咱们就按照24来.
- -info pos/pos.txt 正样本位置
- -vec pos.vec 生成的 . v e c .vec .vec文件名与位置,默认就是本文件夹下
- -bg neg/neg.txt 负样本集的位置
- 开始训练:
opencv_traincascade -data xml -vec pos.vec -bg neg/neg.txt -numPos 1800 -numNeg 5000 -numStages 20 -featureType HAAR -w 24 -h 24 -mode ALL
- -data xml 生成文件放置的位置
- -vec pos.vec 创造的vec文件的位置
- 简单的就不说了
- -numSatges 20 训练的阶段数量,我常常因为已经达到了预定值而提前结束
- -featureType HAAR 就是选择HAAR特征、LBP特征或者HOG特征
- -w -h和上面生成的要一样
- -mode ALL 只有HAAR特征需要,其他不需要添加此参数
我电脑没有显卡,不知道这个训练吃显卡还是cpu,但是训练够慢的。
这里注意一下,pos.vec文件的图片数量一定要大于训练的数量。比如我有2000张正样本,但是在训练的时候最好放1800张左右进去,如果训练的样本接近或者超过.vec文件中声明的数量,会报错,说样本不够。我的经验是图片数量的90%。即10000张正样本,写9000.
命令解释
opencv_createsamples.exe -info pos\pos.txt -vec pos.vec -bg neg\neg.txt -num 2000 -w 24 -h 24
- -info 输入正样本描述文件,默认NULL
- -img 输入图像文件名,默认NULL
- -bg 负样本描述文件,文件中包含一系列的被随机选作物体背景的图像文件名,默认NULL
- -num 生成正样本的数目,默认1000
- -bgcolor 背景颜色,表示透明颜色,默认0
- -bgthresh 颜色容差,所有处于bgcolor-bgthresh和bgcolor+bgthresh之间的像素被置为透明像 素,也就是将白噪声加到前景图像上,默认80
- -inv 前景图像颜色翻转标志,如果指定颜色翻转,默认0(不翻转)
- -randinv 如果指定颜色将随机翻转,默认0
- -maxidev 前景图像中像素的亮度梯度最大值,默认40
- -maxxangle X轴最大旋转角度,以弧度为单位,默认1.1
- -maxyangle Y轴最大旋转角度,以弧度为单位,默认1.1
- -maxzangle Z轴最大旋转角度,以弧度为单位,默认0.5
输入图像沿着三个轴进行旋转,旋转角度由上述3个值限定。- -num 训练的正样本图片数
- -show 如果指定,每个样本都将被显示,按下Esc键,程序将继续创建样本而不在显示,默认为0(不显示)
- -scale 显示图像的缩放比例,默认4.0
- -w 输出样本宽度,默认24
- -h 输出样本高度,默认24
- -vec 输出用于训练的.vec文件,默认NULL
我们也看到了,许多命令都是默认的
opencv_traincascade -data xml -vec pos.vec -bg neg\neg.txt -numPos 2000 -numNeg 5000 -numStages 20 -featureType HAAR -w 24 -h 24
- -data 目录名xml,存放训练好的分类器,如果不存在训练程序自行创建
- -vec pos.vec文件,由opencv_createsamples生成
- -bg 负样本描述文件, neg\neg.txt
- -numPos 每级分类器训练时所用到的正样本数目
- -numNeg 每级分类器训练时所用到的负样本数目,可以大于-bg指定的图片数目
- -numStages 训练分类器的级数,默认20级,一般在14-25层之间均可。 如果层数过多,分类器的fals alarm就更小,但是产生级联分类器的时间更长,分类器的hitrate就更小,检测速度就慢。如果正负样本较少,层数没必要设置很多。
- -precalcValBufSize 缓存大小,用于存储预先计算的特征值,单位MB
- -precalcIdxBufSize 缓存大小,用于存储预先计算的特征索引,单位M币
- -baseFormatSave 仅在使用Haar特征时有效,如果指定,级联分类器将以老格式存储
- -stageType 级联类型,staticconst char* stageTypes[] = { CC_BOOST };
- -featureType 特征类型,staticconst char* featureTypes[] = { CC_HAAR, CC_LBP, CC_HOG };
- -w
- -h 训练样本的尺寸,必须跟使用opencv_createsamples创建的训练样本尺寸保持一致
- -bt Boosted分类器类型 DAB-discrete Adaboost, RAB-RealAdaboost, LB-LogiBoost, GAB-Gentle Adaboost
- -minHitRate 分类器的每一级希望得到的最小检测率,总的最大检测率大约为min_hit_rate^number_of_stages
- -maxFalseAlarmRate 分类器的每一级希望得到的最大误检率,总的误检率大约为max_false_rate^number_of_stages
- -weightTrimRate Specifies whether trimming should beused and its weight. 一个还不错的数值是0.95
- -maxDepth 弱分类器的最大深度,一个不错数值是1,二叉树
- -maxWeightCount 每一级中弱分类器的最大数目
更多内容请搜索:opencv_createsamples源码剖析
python代码-测试
import cv2
# 实例化人脸分类器
face_cascade = cv2.CascadeClassifier('G:\\face_regconition\\haarshare\\haarcascade_frontalface_default.xml')
# 读取测试图片
img = cv2.imread('G:\\face_regconition\\opencv_5\\self_trian_cascade\\123.jpg', cv2.IMREAD_COLOR)
# 将原彩色图转换成灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 开始在灰度图上检测人脸,输出是人脸区域的外接矩形框
faces = face_cascade.detectMultiScale(gray, 1.2, 8)
# 遍历人脸检测结果
for (x, y, w, h) in faces:
# 在原彩色图上画人脸矩形框
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 显示画好矩形框的图片
cv2.namedWindow('faces', 0)
cv2.imshow('faces', img)
# 等待退出键
cv2.waitKey(0)
# 销毁显示窗口
cv2.destroyAllWindows()
由于写总结的时候这篇文章还没写完,所以用的.xml文件是opencv自己训练好的。等训练好,用xml文件夹下的非stages文件即可。
得到图片地址写入txt文件中
import cv2
import os
face_cascade = cv2.CascadeClassifier('G:\\face_regconition\\haarshare\\haarcascade_frontalface_default.xml')
pics = os.listdir("G:\\face_regconition\\opencv_5\\self_trian_cascade\\pos")
dir = os.path.dirname("G:\\face_regconition\\opencv_5\\self_trian_cascade\\pos\\")
filename = "G:\\face_regconition\\opencv_5\\self_trian_cascade\\pos\\pos.txt"
for imgs in pics:
img = cv2.imread(dir +"\\" + imgs, cv2.IMREAD_COLOR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.2, 8)
flag = 0
x=0
y=0
w=0
h=0
for (x, y, w, h) in faces:
flag = flag + 1
if flag > 1:
print(dir +"\\" + imgs + " has more than 2 faces, deleted...")
os.rename(dir +"\\" + imgs, "G:\\face_regconition\\opencv_5\\self_trian_cascade\\llll\\"+imgs)
if flag == 0:
print(dir +"\\" + imgs + " has no face, deleted...")
os.remove(dir +"\\" + imgs)
if flag == 1:
with open(filename, 'a') as file_object:
file_object.write(imgs + " 1 " + str(x) + " " + str(y) + " " + str(w) + " " + str(h) + "\n")
print("over")
注意:我的代码将2张及以上的人脸存在了另一张文件夹中,所以要先创建该文件夹。无人脸的直接删除该照片。
剩下的,就是数据了。数据我放在csdn的网站上,请依情况自行参考。开源,不要金币。
数据集不完善,大家按照自己的情况下载把。最好建议用官方的数据集库。
训练结果

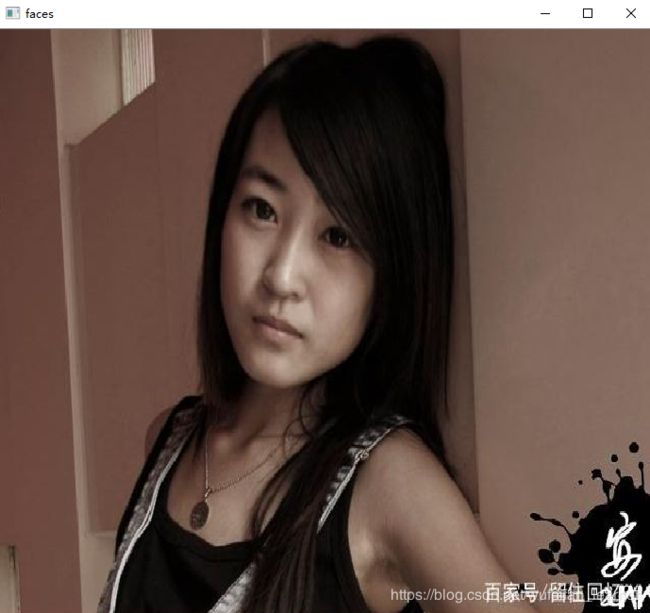
上图是安宁-红咔嚓,hhhhhhh《毛骗》女主,推广下女神
但是我们可以看到,训练结果很不尽人意,仅能检测出部分人脸,下图甚至检测不出人脸。
此后,我以为原因可能是:
- 训练欧美人脸居多,却检测亚洲人脸,有些差异。
- 使用官方提供的文件可以很好的检测出人脸。因此我怀疑可能是图片集没找好,但是也没有其他方法了,训练一次花费了3天,时间熬不起,就到这吧!
如果哪位高手知道具体原因或者解决方法,请联系我:[email protected]
可能的解决方案或思路
- 重新找更规范正负样本图片集,负样本尽量多样化
- 修改训练参数
参考:
https://blog.csdn.net/lql0716/article/details/72566839
https://blog.csdn.net/weixin_41799483/article/details/80567909