数据工程师必须掌握的7个大数据实战项目
文章导语:
作为一名电影爱好者,我阅片无数,有些片子还经常翻来覆去看个好几遍。小时候因为这事儿,没少被我妈抓耳朵,“看过的片子为啥还要倒二遍?”我也说不上来,就是单纯的爱看。
男人爱看的电影,以武侠,动作,科技为多,也认识了一帮明星,比如尼古拉斯凯奇,史泰龙,李小龙,成龙,李连杰,甄子丹等等。这些人很猛,有男人气。只要是他们的片儿,肯定不落下。在我眼里,他们就是好片代名词。
不知几何时,电影上开始出现一些不认识的男明星了,比如张翰,韩庚,鹿晗等等。看着这些人主演的片子,真是…哎,能不睡着就算是对得起票钱了。
后来我从半佛那里才知道,啥叫鲜肉,啥叫老阿姨审美。假如看到有更嫩的男演员,不用问了,老阿姨审美又变了。注定又是一部烂片。
那么,审美可以变,审词呢?
比如这几年,媒体一直在炒作的大数据,用前卫的词儿来说,Big Data. 听得人耳朵老茧都涨了一层。那么 大家是真把它当做有效的工具呢,还是固执的认为又是换汤不换药的营销噱头呢?
为弄清楚这个问题,我查了很多资料,中文的,外文的,百度文库的, Google 论文。期间的所见所闻可以写 3 部小说还不止。
令我印象最深的还属这件事:
《纽约时报》将 1851 - 1922 之间的 1100 多万篇文章,在24小时内花费3000美金,转成 PDF 供大众搜索查看。
资料背景指出,这些文章已经做好了 TIFF 图档格式,要解决的本质问题就是将 TIFF 转换成 PDF.这件事情,工作量非常大。单纯写代码转换,可行,但对完工时间不好把握。
此时有个工程师,仅凭一人之力完成了这项工作,整个过程,他只做了 4 件事情:
1) 首先他是资深编程爱好者。平常阅读技术Blog,知道 AWS, S3,EC2 等云计算概念,还熟悉 Google 的 MapReduce 论文,并且知道 Hadoop 的功能。
2)于是他自己在他的个人电脑上,搭建了Hadoop,玩起大数据,利用 MapReduce 来试着完成 TIFF 到 PDF 的转换;
3)接着在 Amazon 上申请 4 台 EC2 的主机,搭建了 Hadoop 集群,跑了一批 TIFF 到 PDF 转换程序。发现居然可行。
4)大规模实施批量转换,用了 24 个小时,3000 美金,最终将 1100 万文章的影音图像,转成了 PDF,并对外提供服务。
再举一些经过报道的大数据应用案例:
- Yahoo!使用4000节点的集群运行 Hadoop, 支持广告系统和 Web 搜索;
- Facebook 使用 1000 节点运行 Hadoop, 存储日志数据,支持其上的数据分析和机器学习;
- 百度使用 Hadoop 处理每周 200TB 的数据,进行搜索日志分析和网页数据挖掘工作;
- 中移动基于 Hadoop 开发了 BigCloud 系统,提供对内外的数据支持;
- 淘宝的 Hadoop 则处理电子商务交易数据。
初学者要入门大数据,最好的方式,从了解具体的应用开始。掌握大数据能做哪些事情,完成哪些小数据做不到的功能,学着才有意思。只有学着有意思,才会继续往下学。越学越想学,越学越开心,自然也就学好了。
接下来,我整理一些大数据已经发挥它真正作用的应用场景,如果你要做大数据项目,肯定离不开这7个范畴。
因此,你说大数据离我们远吗,我说肯定很近。不管你信不信,反正我信了。
项目一:数据整合
说到数据整合,我们做数据的人,一般想到的是数据仓库。
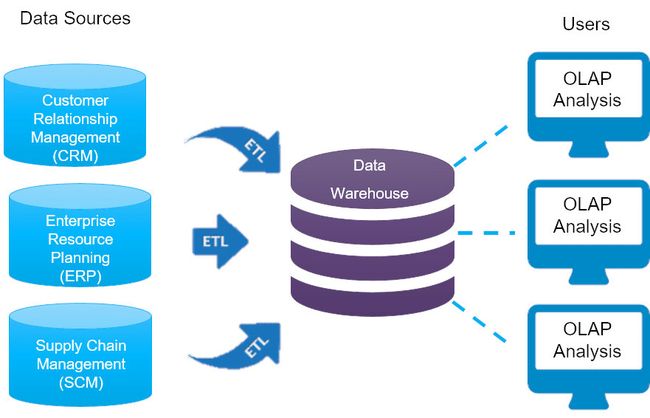
当我们有很多应用,比如 MES, ERP, HR, SALES AND Marketing, CRM 等,每个应用都是一些独立的数据岛,每个使用这些应用的人,都可以从这些应用里面找到自己想要的数据和答案,如果找不到也可以找IT帮你做报表。
但是当我们需要的数据,是整条完整的数据链,这些系统就显得无力了。比如我们要分析每个 ERP 的成本中心,到底分摊到每个车间,每道工序,有多少成本时,仅仅靠ERP就无能为力了,必须将 MES 的数据导入ERP,综合起来分析。此时,ERP数据就会整合部分的MES数据。但本身ERP是排斥这些MES数据的,过于详细,对BOM,PP等的支持粒度不够,需要重新写代码完善。
那么与其把这些数据都导入ERP,再重新编码,那还不如将MES,ERP的数据整合到一个数据库里面,重新出完整的数据字典,供财务或者运营去做分析。这就是数据仓库的作用了。
如果HR也想要从数据中,得到招聘人员的产出,同样也需要整合HR系统。CRM的分析师,可能想知道某个客户的利润,是否与生产成正相关,总不能让利润最少的客户长期霸占工厂的资源吧。因此CRM也可以接入到数据仓库来。
当数据仓库数据量超额时,比如 Oracle 成本已经很高,且计算能力也达不到旺盛的分析需求时,就需要考虑 Hadoop 了。因此 Hadoop 在这里扮演的角色就是数据仓库的落地数据存储和计算。
从传统的数据仓库架构扩展而来,此时企业的数据仓库又多了一层大数据,如下图:

(图来自mastechinfotrellis.com)
但是也有可能,Hadoop 的离线应用完成了聚合,分析师需要从原有的RDBMS获取,那么我们就需要回写到RDBMS里面来,方便分析师的调用。这里需要说明下为什么要回写关系数据库(SQL类数据库),很多分析师还在使用 Excel 和 Tableau 做数据分析,而这类工具最搭配的便是 RDBMS, SQL 的学习成本放在那里,Excel 的易用性摆在那里,还有 Tableau 漂亮的UI。而从 Hadoop 这类分布式数据系统中,取数分析,需要新型的作战武器, Zepplin 或者 IPython Notebook , 当然这类工具,SQL还是必不可少。
总之,数据整合是 Hadoop 的最基础应用,扮演的可能是最终存储,也有可能是整条数据链上的一环,也就是ETL中的任一角色。
在正式的报告中(官方文档或者公司知识库),大家会采用"企业级数据中心"或者"数据湖"来表示 Hadoop 的这类应用。
为什么要用 Hadoop 而不是传统的 Teradata 和 Netezza 呢?
很大的原因,Teradata, Netezza 的成本不是一般的高,如果用来存储一些非交易性的数据,造成很大的资源成本。比如评论,用户行为,这些完全可以存储在 Hadoop 的低成本集群中
项目二:专业分析
在《Spark高级数据分析》这本书里讲到一个实例,就是:
Estimating Financial Risk Through Monte Carlo Simulation
蒙特卡洛模拟分析,用来预测和监控银行流动性风险。这类专业应用,一般的软件公司并不会去考虑如何兼容,如何做的性能更优,比如数据量巨大的情况下,R有什么特别好的方法去处理,T-SQL会怎么处理,恐怕都无能为力?
针对有限的数据量,上述两个工具会 有不错的效果,但如今的数据量堆积下,要将原本一台单机提供的算力,复制到成千上百台计算机,传统的RDBMS和分析工具都会失效。
此时,Hadoop 配合 Spark 的组合,就有用武之地了!
众所周知,Yahoo!已有4000个Hadoop节点,用这4000个节点去计算一次聚合统计,比如有4亿的订单,需要核算每个订单的总金额,成本,和利润,那分配到4000个节点上,每个节点平均处理10万订单,之后汇总即可。
所以 Hadoop 可以处理更多的量,而 Spark 则在更快的计算上满足了需求。
拿 Spark 举个例子,比如推荐系统。喜爱音乐的朋友会用网易云音乐,喜欢看书的朋友经常会去亚马逊。不难发现的事情是,当你打开这些 App 的时候,会有很多音乐或者书推荐给你,你打开这些推荐的音乐或者书,可能还会觉得很好,正是自己喜欢或者需要的。这就是推荐系统。
推荐系统最大的难点在于实时性。我们可以用 Hadoop 聚合全部人的喜好,进一步去做实时推荐。而 Hadoop 的计算框架,要搭配 MapReduce 程序使用,这类程序最大的弱点是中间结果集存盘,而不是存在内存,那么对于推荐中经常使用的 ALS(Alternating Least Squares )算法就不友好了。这类训练算法需要无数次回头重读中间结果集,每次从硬盘读取结果(有可能还要重算),就会浪费极大的时间。
Spark 就是在解决这个问题。
它将所有的数据集封装在 RDD(Resilient Distributed Dataset)中,这个结果集天然就带着分布式特性,也就是每个Spark节点上都有一个小的RDD,针对RDD的计算都会分摊到这些小的RDD上,同步计算。这个特性满足了分布式并行计算的需求,RDD还有个特性就是Cache操作,将RDD的结果缓存到内存保存,之后可以复用RDD结果集。这是Spark区别于MapReduce的重要特点,简单说来,就是整个计算过程变快了,使得实时推荐也变成了可能。
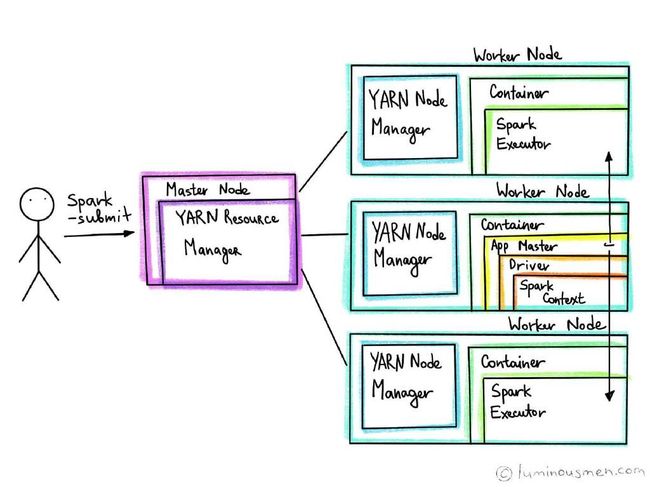
(图来自https://luminousmen.com/post/spark-anatomy-of-spark-application)
看上去,我们只提交了一个Spark Job,完成对输入数据的处理,并且输出结果。没有特别厉害的地方。但背后做了很大的工作,它均衡地在每个数据节点上分配处理算子(Executor),做本地处理,之后将这些中间结果集缓存起来,以提供给其他子程序使用。
项目三:大数据作为服务
通常企业足够大,就会自建 Hadoop 集群用来满足数据整合或者专业分析的需求。当企业拥有自主开发 Hadoop 实力之后,会有多余的计算资源可以分享给其他企业用户,那么这时可以把 Hadoop 作为服务开放给市场。
这就是云计算的力量。
国外的案例有 GCP(Google Cloud Platform), Amazon, Microsoft Azure, 而国内出色的供应商则是HTA(华为云,腾讯云和阿里云).
要说明的是,Hadoop 作为云服务的一种,需要很强的技术性。针对创业型或资源短缺性的中小企业,则可以付费使用大公司提供的服务,大家各得其所。
云计算:基本概念
云计算目前可分为 IAAS,SAAS,PAAS,这三者在使用上有很大区别。
都说云计算有不可替代的成本优势,那么成本到底优化在哪里?
比如公司如果内建一个运维团队,包括硬件,软件与人员,配套的基础设施还有机房,办公楼。假设一个软件公司由一个人,一台服务器,一个办公室组成,软件全部由这个人来编写,采用的全部是开源技术,一年的费用算50万,而这些采用云计算,这个人负责编程没变,但是可以在咖啡馆,图书馆,高铁,飞机,任何只要有网线的地方即可,这样就省去办公楼,硬件与软件的采购费用,主要成本都在云上和应用的开发人员身上。云上有专业的Devops团队,有DBA专业人员保障基础设施,还有可靠的机房双灾备,一切后顾之忧都交给了云服务商。按照腾讯云最新的企业云服务器,一年下来就3,500千块。
即买即用,部署极速
某天公司需要使用 Hadoop 的离线大容量存储来容纳日志,并且用 MapReduce 负责超大规模的计算,那么自建一个大数据团队,负责装机,配置和搭建,可能要花去1个月左右的时间,同时还需要进行业务的梳理和代码的编写,等到系统完毕,上线调试,这样大半时间下去了,效果还出不来。
而使用云计算,接口调试好,今天就可以导入数据,极大节约了时间成本。
如果云服务商对于每次查询都需要结算,而大数据又是公司避不可避的战略,那么内建也不是大问题。但往往公司业务还没成熟呢,就急着去部署大数据系统是不划算的。
云计算:IAAS, SAAS, PAAS 的区别:
通过NYT(NewYorkTimes)的4T TIFF图片数据转PDF的事件,我们来说明这三者的区别,就很容易了:
详细案例:https://t.zsxq.com/QrBmeaY
这个案例中,作者通过购买Amazon EC2 的100台服务器,将S3的4T文件转成PDF,并最终提供给大众搜索。
正好将IAAS,SAAS都涉及到了。比如 EC2,S3就是典型的IAAS,提供服务器操作系统,存储,网络,就是典型的IAAS应用;而最终开发的PDF搜索就是SAAS应用;如果作者不是自己写MapReduce来转换PDF,而是使用AWS提供的编辑软件,且使用了AWS的Hadoop, Spark作业接口实现了转换,那么PAAS也就被用到了。可能当时AWS并没有提供这样整套的开发环境。
如果你是微信小程序开发者,不难理解,小程序的开发就是在PAAS平台上完成的。
项目四:流分析
流和流式计算一直存在于应用场景中,但在大数据未出现之前,一直做的不好。之前业界一直使用低延迟来对流进行处理,但是流的实时性,低延迟编程方法就显得笨拙了。
之前我有文章对流处理做过详细的科普,可以看这里:
http://dwz.win/uCZ
此时虽然看起来与Hadoop没有啥关系了,主要担任重责的是 Storm, Flink, Spark, 但最终落地数据的,还是Hadoop.
举两个实时流分析的例子:
银行风控:如果依据模型检测到有大量小额连续的取款,那么就有可能是洗钱。此时应当场冻结账户,而不是等到整个取款过程结束,通过跑批次去检测某账户洗钱,再进行追溯,冻结。无论是低延迟还是分批处理,都不足以弥补账户的损失,只有实时流分析才可以解决这个场景应用。
库存管控:比如双11,双12的在线秒杀,如果2万件iPhone11半折秒,疯抢的人数达到2000万,那么对于实时库存就要计算很精确。就像有些公司搞的饥饿营销,不到1s,上百万手机一抢而空,造成假象,带给消费者的印象就low了。
以上只是流分析的冰山一角,只要有需求存在就有流分析存在。但也不是所有场景都需要流分析来处理,有些历史统计或者预测分析,还是通过跑批的方式,成本会更小。
项目五:复杂的事件处理
事件有两个维度的属性,时间与时长。
在时间线上保持连续不断发生的事件,形成一个流,就像是水龙头出来的水一样,只有积累多了才能派上用场,针对这类数据做处理,我们称之为流式处理;孤立这段时间,选取当前时间点发生的事件,做单独的处理,那就是实时处理。
这类项目里,复杂度就是针对时间点的细化,可以是 millisecond(毫秒), nanosecond(纳秒:十亿分之一秒), picosecond(皮秒:一万亿分之一秒).
有的领域,比如邮件的收发,评论的发布,在秒级实现是可以接受的。而有些领域,比如量化交易,需要在更精细粒度时间上做挂单和撤单,时间差加上大资金量,能够获得很好的受益。
实际上,我们发评论时,在点击发布到获得显示这段时间,哪怕是1-2秒,中间也可做很多处理,比如限流,关键字与舆情评判,内容分发。
综上,在时间维度上做实时处理,是件复杂的事情。
之前,处理这类实时数据,最有效的方法是加缓存,加消息队列,其原理是假定消息处理不完,就先缓存起来,经由处理方慢慢处理。现在这类需求也可以这样处理,借助 Redis, MessageQ, Kafka 等软件,做到低延迟处理。
但在如今数据呈井喷式暴涨的互联网,使用队列处理显得明显低效,还可能导致数据大量积压而无法处理。所以增加10倍,100倍,甚至1000倍机器来并行处理,变成了当今唯一可解决的方法。
比如在交通灯处,增加传感器,增加摄像头,使用 Spark, Storm, Flink, Apex Project 来实时传导Iot数据,使得交管局可以实时监控路面拥堵情况,违规行为甚至犯罪行为等。
项目六:流式ETL
这是一种特殊的数据整合方法,与传统的批次处理不一样的是,在时间的时长维度上做了无限流的处理。除了做数据的分包转发之外,流式ETL还可以做专业分析,并将分析结果再分包转发。
从宏观来看,ETL既可以有跑批的步骤,还能包含流式计算的步骤。
上述的5种项目中,都可以涉及到这种项目的设计。
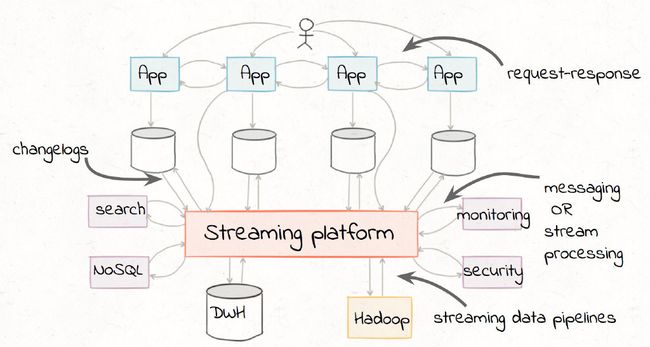
(图来自Confluent公司)
互联网时代,慢,正在成为用户流失的重大因素。在每个数据接口实现流式ETL变得非常有必要,实现数据流动无断点,建立 Streaming Platform 变得越来越重要。
最适合用来搭建流式ETL的工具,Kafka.
一旦消息入库(Kafka),我们要做的事情就像是从水库接水一样,接入管道即可。
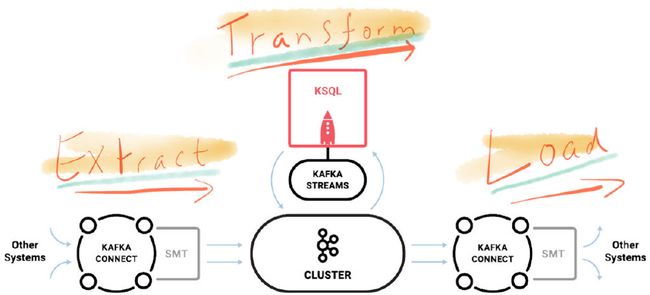
(图来自Confluent公司)
NetFlix公司在Kafka实时流式处理方面有前卫的探索,在这里一窥究竟:

项目七:可视化分析
市面上很多统计分析软件都比较昂贵,他们独有的算法搭配内建的可视化展现组件,经过多年市场检验,越磨越好用。但成本上就是下不去,比如 SAS.
但如今大数据量的市场下,这些传统供应商显得不够友好,因此催生了iPython Notebook, Zeppelin 等一系列可直接用于大数据的可视化分析工具。尤其Python,Spark社群在机器学习,深度学习软件库上的开发,使得整个大数据统计分析生态日臻完美,不仅对数据挖掘算法有友好的支持,对数据可视化组件也提供了开箱即用的软件包。
image
以上来自 Andrew C. Oliver 的文章《the 7 most common Hadoop and Spark projects》以及其他百度文库参考资料 - https://www.javaworld.com/article/2972303/the-7-most-common-hadoop-and-spark-projects.html
Oliver 就是《7周7编程语言》的作者 https://www.techworld.com.au/article/455387/epic_codefest_7_programming_languages_7_days/