语义分割车道线,来自两篇论文的融合算法
语义分割车道线,来自两篇论文的融合算法
IEEE IV 2018论文《LaneNet: Real-Time Lane Networks for Autonomous Driving》。这篇文章主要内容是,如何克服车道切换和车道数的限制。
关于Software Loss,另外一篇文章《Semantic Instance Segmentation with a
Discriminative loss function》。
原理是:提出了Lannet网络结构,即通过训练神经网络进行端到端的车道检查,将车道作为实例分割来实现。
下面是Lannet网络结构图:
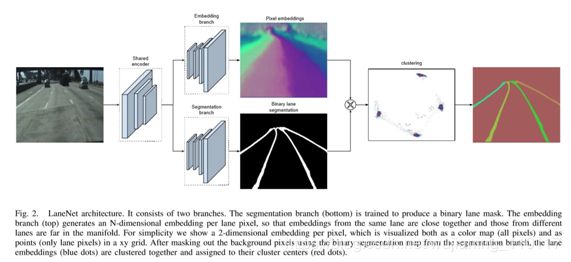
-
Lanenet使用一个共享的encoder,对输入图像进行处理,得到2个branch:嵌入式和语义分割的branch。嵌入branch可以将不同的车道线区分为不同的instance;因为只需要考虑车道线,因此语义分割的结果是二值化图像;然后对2个branch做聚类,最终得到结果。
-
通常情况下,车道线像素被投影成“鸟瞰图”。使用一个固定的转换矩阵。可是,因为变换参数对所有图像都是固定的,所以,当遇到非地面例如,在斜坡上,会有问题。为了解决类似问题,提出了H-Network可以估算输入图像上的“理想”透视变换的参数。
-
投影方法H-Net
将输入的RGB图像作为输入,使用LaneNet得到输出的实例分割结果,然后将车道线像素使用H-Net输出得到的透视变换矩阵进行变换,对变换后的车道线像素在变化后的空间中进行拟合,再将拟合结果经过逆投影,最终得到原始视野中的车道线拟合结果。
H-Net将RGB作为输入,输出为基于该图像的透视变换系数矩阵,优化目标为车道线拟合效果。
- Software
Loss计算
与主流的基于proposal的实例分割(instance segementation)方法不同,本文受metric learning(测量学习)和(triplet loss)的启发,提出了一种基于pixel embending的方法。与deep watered network一样,本文方法也依赖于现成的语义分割结果,可以将本文方法视作语义分割结果的post processing以产生instance-level的结果。
One
key factor that complicates the baive application of the popular software
cross-entropy loss function to instance segmentation, is the fact that an image
can contain an arbitrary number of instances and that the labeling is
permutation-invariant: it does not matter which specific label an instance
gets, as long as it is different from all other instance labels.
上面指出,software loss用于实例分割的两个缺点:
第一, an image can contain an arbitrary number of instances(一幅图像可包含任意数量的实例)。
第二, the labeling is permution-invariant(实例标签具有permutation-invariant的性质)。
将本用于语义分割的software loss用于图像的实例分割,图像包含多少个实例,就有多少个“类”。这里的类,并不是语义分割中的class-label的含义,而是指不同的insatnce的instance id label。
应用software loss的网络,最后输出层的channel数等于类别数,因为图像中的实例数目不定,所以网络最后层的结果无法确定。
如果网络每个像素的预测输出和ground truth的id-label不一致。
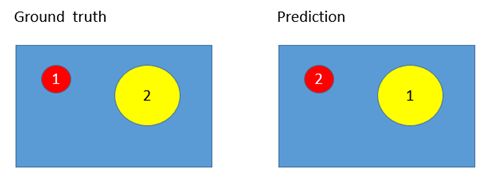
Softmax Loss会惩罚这种预测错误。但这种预测结果其实是对的,只要不同实例之间的id-label不同就行。即instance id label满足permutation-invariant的性质。
Pixel embedding:mapping each pixel to a point in n-d feature space
Cluster:a group of pixel embendings sharing the same label
Cluster
center:the mean embebding of a char
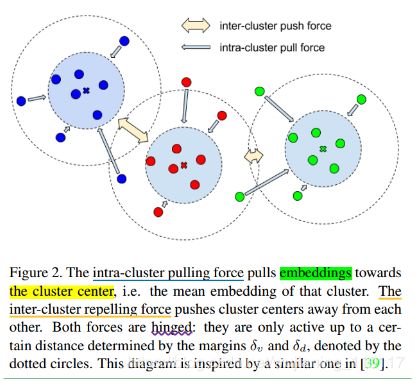

Variance term:an intra-cluster pull-force that draws embeddings towards the mean
embedding, i.e. the cluster center.
Distance term:an inter-cluster push-force that pushes clusters away from each
other, increasing the distance between the cluster centers.
Regularization term:a small puul-force that draws all clusters towards the origin, to
keep the activations bounded.
The loss function encourages the network to map each pixel to a point in feature
space (pixel embedding) so that pixels belonging to the same instance lie close
together while different instances are separated by a wide margin.
用本文提出的 loss function对现有网络进行训练。优化的目标是:网络将图像每个像素投影到n-d特征空间(n是个随机数据集变化二变化的超参),是的同属一个实例的像素尽量靠近,形成一个cluster,每一个实例对应一个cluster,不同的cluster尽量远离。
如果loss降为零,显然:

5. 在多语义类别的实例分割场景中:
Therefore, we run our loss function independently on every semantic class, so that
instances belonging to the same class are far apart in feature space, whereas
instances from different classes can occupy tha same space. For example, the
cluster centers of a pedestrian and a car that appear in the same image are not
pushed away from each other.
概括起来,不同语义类别的实例像素潜入相互独立,分开进行。