MAML-Tracker: 目标跟踪分析:CVPR 2020(Oral)
MAML-Tracker:
目标跟踪分析:CVPR 2020(Oral)
Tracking by Instance Detection: A Meta-Learning Approach
论文链接:https://arxiv.org/abs/2004.00830
摘要
把跟踪问题看作一类特殊的目标检测问题,称之为实例检测。通过适当的初始化,通过从单个图像中学习新实例,可以将检测快速转换为跟踪。发现模型不可知元学习(MAML)提供了一种策略来初始化满足需求的检测。提出一个原则性的三步方法来建立一个高性能的跟踪。首先,选择任何经过梯度下降训练的现代目标检测。其次,使用MAML进行离线训练(或初始化)。第三,使用初始帧执行域自适应。按照这个过程建立了两个跟踪,名为Retina MAML和FCOS-MAML,基于两个现代跟踪RetinaNet和FCOS。对四个基准的评估表明,这两个跟踪都是最先进的跟踪的竞争对手。在OTB-100上,Retina MAML达到了有史以来最高的AUC 0.712。在TrackingNet上,FCOS-MAML的AUC为0.757,标准化精度为0.822,在排行榜上排名第一。两个跟踪都以每秒40帧的速度实时运行。
目标跟踪(Object tracking)与目标检测(Object detection)是计算机视觉中两个经典的基础任务。跟踪任务需要由用户指定跟踪目标,然后在视频的每一帧中给出该目标所在的位置,通常由一系列的矩形边界框表示。而检测任务旨在定位图片中某几类物体的坐标位置。对物体的检测、识别和跟踪能够有效地帮助机器理解图片视频的内容,为后续的进一步分析打下基础。

图1:目标检测与目标跟踪
跟踪任务与检测任务有着密切的关系。从输入输出的形式上来看,这两个任务是极为相似的。它们均以图片(或者视频帧)作为模型的输入,经过处理后,输出一堆代表目标物体位置的矩形框。它们之间最大的区别体现在对“目标物体”的定义上。对于检测任务来说,目标物体属于预先定义好的某几个类别,如图1左图所示;而对于跟踪任务来说,目标物体指的是在第一帧中所指定的跟踪个体,如图1右图所示。实际上,如果将每一个跟踪的个体当成是独立的一个类别的话,跟踪任务甚至能被当成是一种特殊的检测任务,称为个体检测(Instance Detection)。
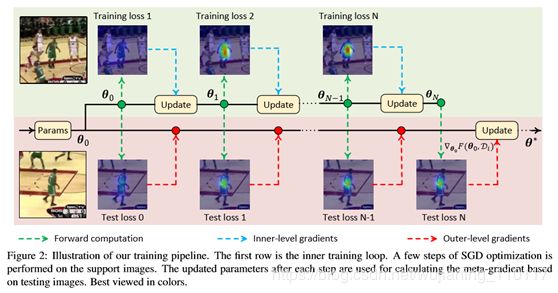
外层梯度通过内层计算图反向传播。因此,这种方法很容易适用于大多数基于深度学习的检测器。图2示出了该训练管道。在训练阶段,只从数据集中抽取一对图像。按照DaSiamRPN[45]的实践,这两幅图像可能来自同一序列或不同序列。第一幅图像将放大/缩小一个常数因子(在的实验中为1.08),这样就可以构建一个包含三幅图像的支持集来进行内部优化。将第二图像视为具有单个图像的目标集,用于计算外电平损耗。使用4步GD进行内部级优化,Adam解算器[18]用于外部级优化。为了稳定训练,增强检测器的检测能力,对原始的MAML算法进行了如下修改。
由于这种紧密的关系,近年来,许多目标检测的技术同样能在目标跟踪领域大放异彩。例如检测中的区域推荐网络(RPN)模块,就被双路网络跟踪框架 SiamRPN 所借鉴;基于优化的 IoUNet 检测模块,也在 ATOM 等跟踪框架中取得了非常惊艳的效果。这些成功的应用启发:与其在跟踪器中使用一些检测器的模块,能否直接将检测器直接应用于目标跟踪任务?
解决小样本问题
用检测器模型去解决跟踪问题,遇到的最大问题是训练数据不足。普通的检测任务中,因为检测物体的类别是已知的,可以收集大量数据来训练。例如 VOC、COCO 等检测数据集,都有着上万张图片用于训练。而如果将跟踪视为一个特殊的检测任务,检测物体的类别是由用户在第一帧的时候所指定的。这意味着能够用来训练的数据仅仅只有少数几张图片。这给检测器带来了很大的障碍。
在深度学习中,解决训练数据不足常用的一个技巧是“预训练-微调”(Pretraining-finetune),即大数据集上面预训练模型,然后在小数据集上去微调权重。但是,在训练数据极其稀少的时候(仅有个位数的训练图片),这个技巧是无法奏效的。图2展示了一个检测模型预训练过后,在单张训练图片上微调的过程:尽管训练集上逐渐收敛,但是检测器仍无法检测出测试图片中的物体。这反映出了“预训练-微调”框架的泛化能力不足。

图2:“预训练-微调”框架的泛化能力不足
为了解决训练数据不足的问题,引入了“与模型无关的元学习”(Model-agnostic meta-learning, MAML)。这个算法是近年来比较主流的小样本学习(few-shot learning)算法。它的核心思想是,学习一个好的模型初始化权重,使得模型能够在极少量的数据上面做几步更新就收敛到一个非常好的结果。
在大数据集上预训练网络权重的时候,MAML 算法采用了双层优化(Bilevel optimization)的策略。在每一轮迭代中,将一组训练样本分为支撑集(Support set)以及目标集(Target set)。检测器模型先在支撑集上面去进行固定次数的梯度下降迭代(一般为5步),再将更新过后的模型参数应用在目标集上,计算目标集上的误差。整体流程如图3所示。在支撑集上,固定次数的梯度下降过程称为里层优化(Inner-level optimization);由目标集上的误差去更新模型参数的过程,称为外层优化(Outer-level optimization)。与普通的 SGD 方法相比,MAML 算法并不要求找到一组参数,直接使得目标集上误差最小;相反的,它希望找到一组参数,使其经过几步梯度下降迭代之后,在目标集上误差最小。这种双层优化的方式,迫使检测器能够通过在支撑集上的训练,泛化到目标集上。
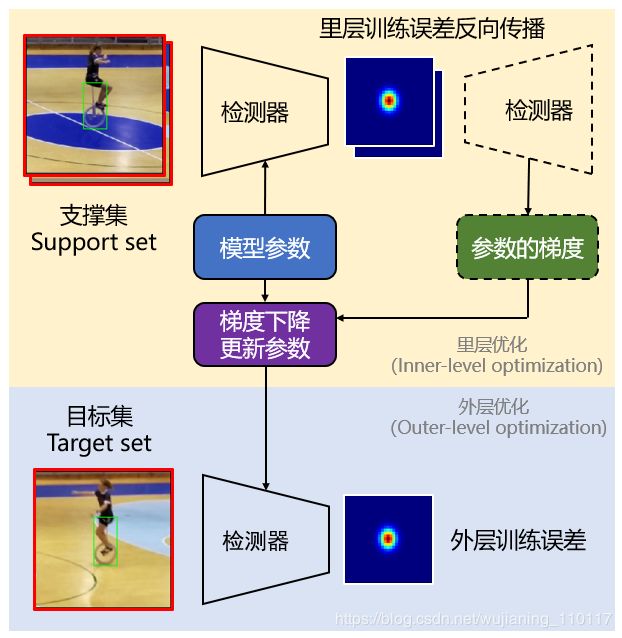
图3:算法流程
通过 MAML 算法训练出来的初始化参数具有收敛快、泛化性能好的优点。图4的可视化结果充分说明了这一点:仅仅经过1步梯度下降的更新,检测器就能收敛到一个不错的结果;更重要的是,它在测试图片上仍然能够工作得很好。
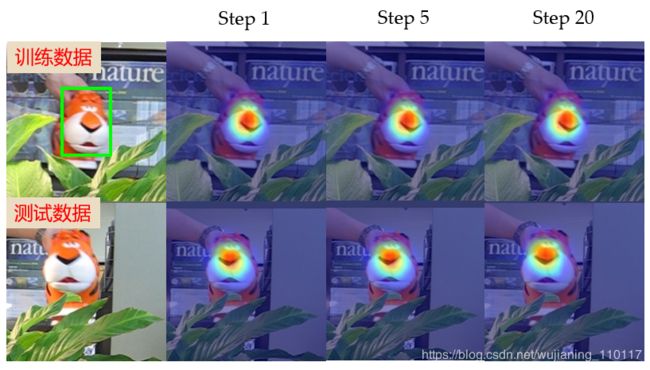
图4:测试结果
训练过程与实验结果
解决了小样本学习的问题,检测器模型就能够自然地应用在跟踪任务上。
第一步,挑选一个目标检测模型。MAML 算法对具体模型是没有要求的,只需要满足可用梯度下降更新的条件即可。
第二步,使用 MAML 算法,对该目标检测模型进行预训练,找到一组较好的初始化的参数。
第三步,每输入一段视频,根据用户在第一帧上指定的跟踪目标,构造训练数据,并用这个训练数据来训练目标检测模型。把这一步称之为域适应(Domain adaptation).
第四步,对于后续的每一帧图片,用训练好的检测器去预测跟踪目标的位置。
在实验的过程中,选择了 RetinaNet 和 FCOS 作为目标检测模型。它们分别是 Anchor-based 以及 Anchor-free 两种类型检测器的代表性工作。在 MAML 预训练初始化参数的过程中,还加入了一些额外的技巧来辅助训练。例如可学的学习率(Learnable learning rate)、多步梯度优化(Multi-step
loss optimization)、梯度一阶近似(First-order approximation)等等。这些技巧能够有效地稳定训练过程,提高模型的表达能力。感兴趣的读者可以参阅原始论文中的细节部分。
在实验中惊讶地发现,通过这种简单的方式将检测器应用于目标跟踪,已经能够取得不错的效果。在 OTB-100、VOT-18 等多个数据集上,MAML 预训练的检测器与普通 SGD 预训练的检测器(记为 Baseline)进行了详细的对比,结果如表1所示。在做 Domain adaptation 之前, Baseline 和 MAML 的性能都比较低,这是因为此时还没有学到任何跟目标物体相关的信息。经过
Domain adaptation 之后,baseline 的检测器性能有了小幅度的改善,而用 MAML 预训练的检测器则远远优于 domain adaptation 之前的结果。这充分说明了元学习的有效性。
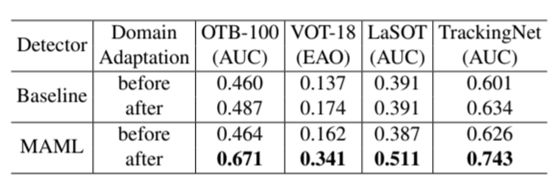
表1:MAML 预训练的检测器与 Baseline 的对比结果
在实验中,还进一步探索了在线更新(online
updating)策略的有效性。所谓在线更新,即利用之前跟踪的结果,收集训练数据,用来再次训练检测器。发现,通过在线更新的方式,能够进一步地提升跟踪的准确度。当然,正如表2所示,当在线更新检测器的分类分支(cls)或者回归分支(reg)的时候,均会带来效率上的降低。

表2:在线更新策略有效性的验证结果
将检测器模型应用于跟踪任务上,得到的准确率并不逊色于一些经过精心设计的跟踪器。在多个主流数据集上,均取得了超过或者接近当时最好跟踪器的性能。这些结果充分展示了“目标检测+小样本学习”这个框架的威力。
近年来,目标跟踪技术的发展突飞猛进,在各大数据集的性能评测中有了长足的进步。一方面,目标检测技术的进步给跟踪器带来了不小的帮助,许多目标检测的优秀设计被应用到了跟踪领域,使物体坐标的预测更加精确,如 SiamRPN、SPM、SiamFC++等等。另一方面,不少工作深入研究了如何利用少量样本去学习一个可靠的目标物体表征,如 MDNet,MetaTracker,ATOM 等等。在这篇文章中,借鉴了这两个方向的研究,提出了一个简洁、统一而高效的框架“目标检测+小样本学习≈目标跟踪”,希望能为目标跟踪的研究提供一个不一样的视角。在这个框架下,还有许多问题仍值得探索,例如采用更好的小样本学习算法、实例分割结合小样本学习等等。也将在未来的工作进一步发掘这一框架的潜能,打造一个更好、更快的目标跟踪算法。