目标检测中特征融合技术(YOLO v4)(下)
目标检测中特征融合技术(YOLO v4)(下)
ASFF:自适应特征融合方式
ASFF来自论文:《Learning Spatial Fusion for Single-Shot Object Detection》,也就是著名的yolov3-asff。
金字塔特征表示法(FPN)是解决目标检测尺度变化挑战的常用方法。但是,对于基于FPN的单级检测器来说,不同特征尺度之间的不一致是其主要限制。因此这篇论文提出了一种新的数据驱动的金字塔特征融合方式,称之为自适应空间特征融合(ASFF)。它学习了在空间上过滤冲突信息以抑制梯度反传的时候不一致的方法,从而改善了特征的比例不变性,并且推理开销降低。借助ASFF策略和可靠的YOLOV3 BaseLine,在COCO数据集上实现了45FPS/42.4%AP以及29FPS/43.9%AP。
ASFF简要思想就是:原来的FPN add方式现在变成了add基础上多了一个可学习系数,该参数是自动学习的,可以实现自适应融合效果,类似于全连接参数。
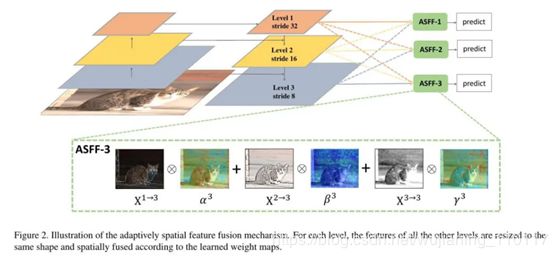
以ASFF-3为例,图中的绿色框描述了如何将特征进行融合,其中X1,X2,X3分别为来自level,level2,level3的特征,与为来自不同层的特征乘上权重参数α3,β3和γ3并相加,就能得到新的融合特征ASFF-3,如下面公式所示:
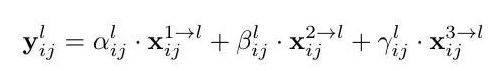
因为采用相加的方式,所以需要相加时的level1~3层输出的特征大小相同,且通道数也要相同,需要对不同层的feature做upsample或downsample并调整通道数。对于需要upsample的层,比如想得到ASFF3,需要将level1调整至和level3尺寸一致,采用的方式是先通过1×1卷积调整到与level3通道数一致,再用插值的方式resize到相同大小;而对于需要downsample的层,比如想得到ASFF1,此时对于level2到level1只需要用一个3×3,stride=2的卷积就可以了,如果是level3到level1则需要在3×3卷积的基础上再加一个stride=2的maxpooling,这样就能调整level3和level1尺寸一致。
对于权重参数α,β和γ,则是通过resize后的level1~level3的特征图经过1×1的卷积得到的。并且参数α,β和γ经过concat之后通过softmax使得他们的范围都在[0,1]内并且和为1:
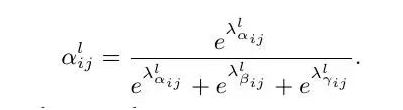
具体步骤可以概况为:
1、首先对于第l级特征图输出cxhxw,对其余特征图进行上下采样操作,得到同样大小和channel的特征图,方便后续融合
2、对处理后的3个层级特征图输出,输入到1x1xn的卷积中(n是预先设定的),得到3个空间权重向量,每个大小是nxhxw
3、然后通道方向拼接得到3nxhxw的权重融合图
4、为了得到通道为3的权重图,对上述特征图采用1x1x3的卷积,得到3xhxw的权重向量
5、在通道方向softmax操作,进行归一化,将3个向量乘加到3个特征图上面,得到融合后的cxhxw特征图
6、采用3x3卷积得到输出通道为256的预测输出层
为什么ASFF有效?
文章通过梯度和反向传播来解释为什么ASFF会有效。首先以最基本的YOLOv3为例,加入FPN后通过链式法则我们知道在backward的时候梯度是这样计算的:
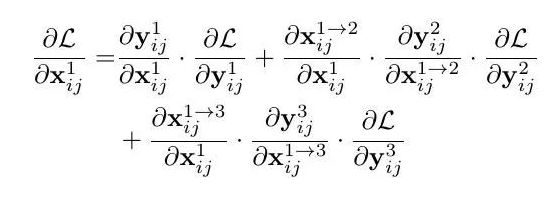
其中因为不同尺度的层之间的尺度变换无非就是up-sampling或者down-sampling,因此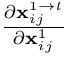 这一项通常为固定值,为了简化表达式我们可以设置为1,,则上面的式子变成了:
这一项通常为固定值,为了简化表达式我们可以设置为1,,则上面的式子变成了:
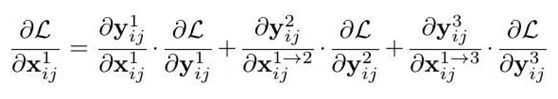
进一步的,![]() 这一项相当于对输出特征的activation操作,其导数也将为固定值,同理,我们可以将他们的值简化为1,则表达式进一步简化成了:
这一项相当于对输出特征的activation操作,其导数也将为固定值,同理,我们可以将他们的值简化为1,则表达式进一步简化成了:

假设level1(i,j)对应位置feature map上刚好有物体并且为正样本,那其他level上对应(i,j)位置上可能刚好为负样本,这样反传过程中梯度既包含了正样本又包含了负样本,这种不连续性会对梯度结果造成干扰,并且降低训练的效率。而通过ASFF的方式,反传的梯度表达式就变成了:
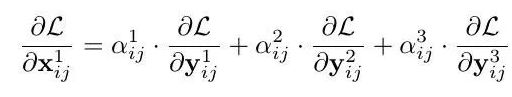
可以通过权重参数来控制,比如刚才那种情况,另α2和α3=0,则负样本的梯度不会结果造成干扰。另外这也解释了为什么特征融合的权重参数来源于输出特征+卷积,因为融合的权重参数和特征是息息相关的。
Bi-FPN
BiFPN来自论文:《EfficientDet: Scalable and
efficient object detection 》。BiFPN思想和ASFF非常类似,也是可学习参数的自适应加权融合,但是比ASFF更加复杂。
EfficientDet的方法论和创新性围绕两个关键挑战:
l 更好地融合多层特征。这个毋庸置疑,肯定是从 FPN 发展过来的,至于 Bi 就是双向,原始的FPN实现的自顶向下(top-down)融合,所谓的BiFPN就是两条路线既有top-down也有down-top。在融合过程中,之前的一些模型方法没有考虑到各级特征对融合后特征的g共享度问题,即之前模型认为各级特征的贡献度相同,而本文作者认为它们的分辨率不同,其对融合后特征的贡献度不同,因此在特征融合阶段引入了weight。
l 型缩放。这个主要灵感来自于
EfficientNet,即在基线网络上同时对多个维度进行缩放(一般都是放大),这里的维度体现在主干网络、特征网络、以及分类/回归网络全流程的整体架构上整体网络由主干网络、特征网络以及分类/回归网络组成,可以缩放的维度比
EfficientNet 多得多,所以用网络搜索方式不合适了,作者提出一些启发式方法。
BiFPN
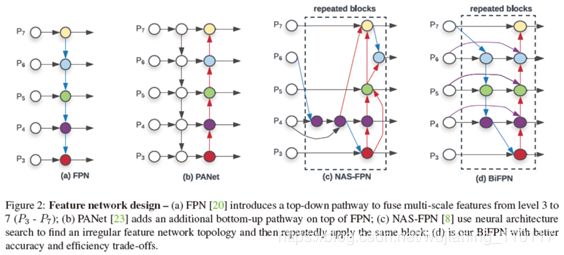
BiFPN的思想其实是基于路径增强FPN(PANet)的思想,在自顶向下特征融合之后紧接着自底向上再融合一遍。在图2中文章列举了三类FPN以及BiFPN。图2(a) 是传统FPN,图2(b)是PANet,图2©是利用网络自动搜索的方式生成的不规则特征融合模块,且这个模块可以重复叠加使用【即堆叠同样的模块,不停地使用相同的结构融合多层特征】。可以看到,PANet可以看做一个naïve的双向FPN。
BiFPN针对PANet的改进点主要有三个:
·
削减了一些边。BiFPN删除了只有一个入度的节点,因为这个节点和前一个节点的信息是相同的【因为没有别的新的信息传进来】,这样就祛除了一些冗余计算。
·
增加了一些边。BiFPN增加了一些跳跃连接【可以理解为residual连接,图2(d)中横向曲线3个连接】,这些连接由同一层的原始特征节点【即没有经历自顶向下融合的特征】连接到输出节点【参与自底向上特征融合】。
·
将自顶向下和自底向上融合构造为一个模块,使其可以重复堆叠,增强信息融合【有了一种递归神经网络的赶脚】。PANet只有一层自顶向下和一层自底向上。
而对于特征融合的计算,BiFPN也做了改进。传统融合计算一般就是把输入特征图resize到相同尺寸然后相加【或相乘,或拼接】。但是BiFPN考虑到不同特征的贡献可能不同,所以考虑对输入特征加权。文章中把作者们对如何加权的探索过程也列了出来。
·
首先尝试简单加权相加,对权值不做约束。这样得到的实验结果还可以,但是没有约束的权值会造成训练困难和崩溃。
·
然后为了归一化权值,作者尝试了用softmax操作把权值归一化到[0, 1]。虽然达到了归一化效果,但是softmax极大增加了GPU计算负担。
·
最后,回归本质,不整什么指数计算了。直接权值除以所有权值加和(分母加了一个极小量防止除0)来归一化【也就是计算权值在整个权值中的比例】,同样把权值归一化到[0,1],性能并没有下降,还增加了计算速度。
BiFPN介绍的最后,作者还提醒大家注意在特征融合模块里为了进一步提高计算效率,卷积使用的是逐深度卷积【就是每个通道自成一个分组】,并在每个卷积之后加了BN和激活函数。
EfficientDet
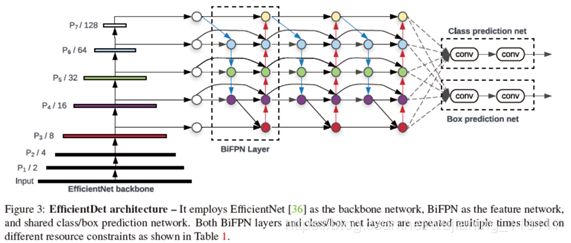
EfficientDet使用在imagenet上预训练的EfficientNet作为backbone模型,并对网络中第3到第7层特征进行了BiFPN特征融合,用来检测和分类。
EfficientDet同样对模型进行了缩放。与EfficientNet对传统提升模型尺度方法的态度一样,文章认为传统提升模型尺度指示简单地针对单一维度【深度,宽度或分辨率】进行增加,而EfficientNet提出的符合缩放才是真香。EfficientDet提出了自己的符合缩放,要联合对backbone,BiFPN,预测模块,和输入分辨率进行缩放。然而仅仅对EfficientNet本身缩放的参数进行网格搜索就已经很贵了,对所有网络的所有维度进行网格搜索显然也是不可承受之重。所以EfficientDet用了一个“启发式”方法【在我看来是对每个网络的每个维度自定了一些简单的规则而已】。
·
Backbone依然遵循EfficientNet。
·
BiFPN的深度随系数ϕ线性增长,宽度随ϕ指数增长。而对宽度指数的底做了一个网格搜索,确定底为1.35 。
![]()
· 对预测模块,宽度与BiFPN一致。深度随ϕ线性增长。
![]()
· 输入分辨率也是随ϕ线性增长。
![]()
参考文章
https://zhuanlan.zhihu.com/p/93922612
https://blog.csdn.net/weixin_44936889/article/details/104269829
https://zhuanlan.zhihu.com/p/
https://blog.csdn.net/watermelon1123/article/details/103277773