用NVIDIA-NGC对BERT进行训练和微调
用NVIDIA-NGC对BERT进行训练和微调
Training and Fine-tuning BERT Using NVIDIA NGC
想象一下一个比人类更能理解语言的人工智能程序。想象一下为定制的域或应用程序构建自己的Siri或Google搜索。
Google BERT(来自Transformers的双向编码器表示)为自然语言处理(NLP)领域提供了一个改变游戏规则的转折点。
BERT运行在NVIDIA GPUs驱动的超级计算机上,训练其庞大的神经网络,达到前所未有的NLP精度,冲击了已知人类语言理解的空间。像这样的人工智能已经被期待了几十年。有了BERT,它终于来了。

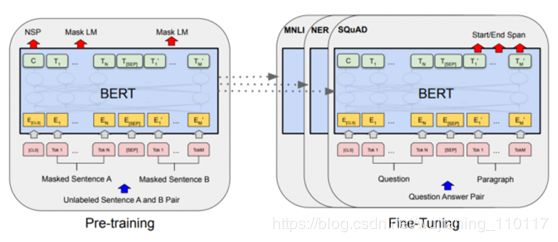
Figure 1. Block diagram for BERT pretraining and fine-tuning.
本文将详细讨论如何使用BERT,这需要预训练和微调阶段。本文重点放在预训练。
What can BERT do?
随着全球研究机构将对话人工智能作为首要目标,BERT在自然语言处理领域取得了重大突破。在过去,基本的语音接口,如电话树算法,当你打电话给你的移动电话公司,银行,或互联网供应商是交易性的,并有有限的语言理解。
对于事务性接口,计算机的理解范围一次仅限于一个问题。这给计算机提供了有限的所需智能:只有与当前动作相关的智能,一两个字,或者更进一步说,可能是一个句子。有关更多信息,请参阅什么是会话人工智能?。
但当人们在日常对话中交谈时,他们指的是段落前面介绍的单词和上下文。超越单句是对话人工智能的切入点。
下面是一个使用BERT理解文章并回答问题的例子。这个例子更多的是对话而不是交易。这个例子展示了BERT在语言理解方面的表现。从美式足球运动版上选一段,然后问BERT一个关键问题。这个例子取自《钢铁侠》中没有本·罗伊特利斯伯格的镜头。现在会发生什么?。
****消息
匹兹堡钢人队是一支总部位于宾夕法尼亚州匹兹堡的职业美式足球队。钢人队作为美国足球协会(AFC)东区的会员俱乐部参加国家足球联盟(NFL)的比赛。该队在海因茨球场进行主场比赛。钢铁工人去年赚了43900000美元。他们的四分卫叫本·罗特利斯伯格。
罗斯伯格已经在处理肘部问题了。本被后援梅森·鲁道夫接替。他的第一个传球被接球手蒙克里夫的手反弹拦截,但鲁道夫在下半场反弹,以16分领先三个得分球。这还不足以阻止钢人队以0-2落后,在过去的12年里,大约90%以0-2领先的球队错过了季后赛。这些可能性可能已经让钢人队的球迷们开始考虑明年的比赛,很难不去想罗思伯格的未来。
问:谁取代了本?
正在运行推理…****
以312.076句/秒的速度进行推理
回答:“梅森·鲁道夫”
概率:86.918
太棒了,对吧?句子被解析成知识表示。在挑战问题上,BERT必须确定谁是匹兹堡钢人队的四分卫(本罗斯利斯伯格)。此外,BERT可以看出梅森·鲁道夫取代了罗斯利斯伯格担任四分卫,这是本文的一个重点。
使用NVIDIA TensorRT的推理速度早些时候报告为每秒312.076句。如果取其倒数,则获得3.2毫秒的延迟时间。这种GPU加速可以很快地预测出答案,在人工智能领域被称为推理。
在2018年,BERT成为一个流行的深度学习模式,因为它的GLUE(General Language Understanding Evaluation,通用语言理解评估)得分达到80.5%(7.7%的绝对改善)。有关更多信息,请参见多任务基准测试和分析平台以获得自然理解。
回答问题是粘合基准度量之一。最近的一个突破是开发斯坦福问答数据集或小组,因为它是一个强大和一致的训练和标准化学习绩效观察的关键。有关更多信息,请参阅SQuAD:100000+文本机器理解问题。
拥有足够的计算能力同样重要。在Google开发了BERT之后,不久NVIDIA就通过在许多gpu上训练BERT,使用大规模并行处理实现了世界记录时间。他们使用了大约83亿个参数,并在53分钟内训练,而不是几天。根据ZDNet在2019年的报告,“GPU制造商说,他们的人工智能平台现在拥有最快的训练记录、最快的推理和迄今为止同类最大的训练模型。”
BERT background
BERT的名字里有三个概念。
首先,变形金刚是一个神经网络层,它利用自我注意来学习人类语言,其中的一段文字会与自身进行比较。该模型学习如何从段中的每个其他单词派生给定单词的含义。
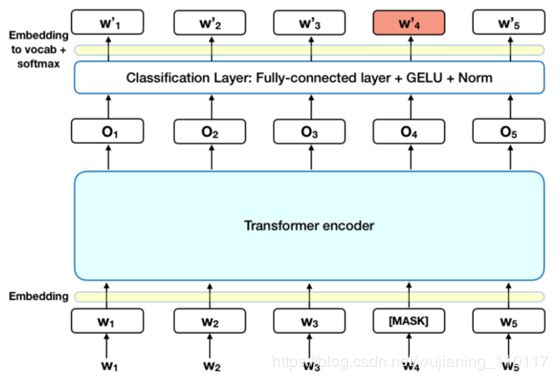
Figure 2. BERT high-level architecture. Words are encoded with transformers, then used as inputs to classifiers.
第二,双向意味着递归神经网络(RNNs)将单词视为时间序列,从两个方向看句子。旧的算法将单词向前看,试图预测下一个单词,而忽略了后面出现的单词所提供的上下文和信息。BERT用自我注意一次看整个输入句子。这个词之前或之后的任何关系都会被考虑在内。
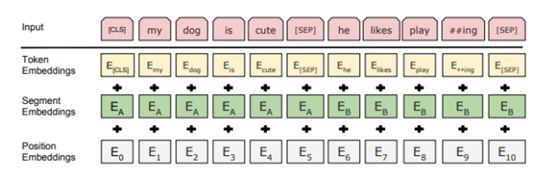
Figure3. BERT works with various types of embeddings as it parses two basic sentences.
最后,编码器是编码器-解码器结构的一个组件。将输入语言编码到潜在空间中,然后使用经过训练的解码器反向创建另一种语言。这对翻译很有帮助,因为自我关注有助于解决语言在表达相同观点方面的许多差异,例如单词的数量或句子结构。
在BERT中,您只需采用编码的思想来创建输入的潜在表示,然后将其用作几个完全连接的层的特征输入,以学习特定的语言任务。
How to use BERT
图4暗示了让BERT学会为您解决问题的两个步骤。您首先需要对transformer层进行预处理,以便能够将给定类型的文本编码为包含完整底层含义的表示。然后,需要训练全连接的分类器结构来解决特定的问题,也称为微调。
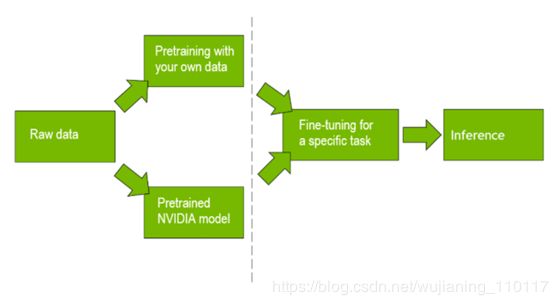
Figure 4. BERT workflow with pretraining and fine-tuning phases.
预训练是一项巨大的努力,可能需要超级计算机级的计算时间和等量的数据。最常用的开放源代码数据集是维基百科上的文章,它们构成了25亿个单词,而BooksCorpus则提供了11000个免费使用的文本。这最终形成了一个约33亿字的数据集。
所有这些数据都可以输入到网络中,供模型扫描和提取语言结构。在这个过程的最后,你应该有一个模型,在某种意义上,知道如何阅读。这个模型对语言、单词的意义、上下文和语法有一个大致的理解。
要为特定领域(如金融领域)定制此模型,需要在预训练模型上添加更多特定领域的数据。这使得模型能够理解特定领域的行话和术语,并对其更加敏感。
根据上下文的不同,一个词有多种含义。例如,熊对动物学家来说就是动物。对华尔街的某些人来说,这意味着一个糟糕的市场。添加专门的文本使BERT定制到该域。使用NGC上提供的预训练BERT并通过添加特定于域的数据对其进行自定义是一个好主意。
微调更容易实现,需要的数据集要小得多,大约有上万个标记示例。BERT可以被训练去做一系列的语言任务。
尽管有许多不同的微调运行,您可以创建专门版本的BERT,但它们都可以分支到相同的基础预训练模型。这使得BERT方法通常被称为转移学习的一个例子,当为一个问题训练的模型权重被用作另一个问题的起点时。经过微调,这个BERT模型获得了阅读的能力,并学会了用它来解决问题。
What makes BERT special?
从教育的角度来看,早期的信息可能很有趣,但这种方法真的比以前的思路有那么大的改进吗?答案是响亮的是!BERT模型在NLP任务中比以往任何时候都能获得更高的精度。一个潜在的来源是胶水基准。
GLUE表示11个示例NLP任务。一个常见的例子是命名实体识别(named entity recognition),或者能够将输入中的每个单词识别为人、位置等。另一种是句子情感相似度,即判断两个句子是否都意味着同一件事。GLUE提供了用于评估性能的通用数据集,模型研究人员将其结果提交到在线排行榜,作为模型准确性的一般展示。
2018年9月,最先进的NLP模型徘徊在GLUE分数70左右,平均完成各种任务。虽然令人印象深刻,但在同样的任务中,人类基线的测量值为87.1,因此很难对人类水平的表现提出任何要求。
BERT是由谷歌研究员雅各布·德夫林(Jacob Devlin)在2018年10月开放的(特别是BERT的参数变化最大)。虽然发布的最大的BERT模型仍然只有80.5分,但它显著地表明,在至少几个关键任务中,它可以首次超过人类的基线。有关更多信息,请参阅BERT:Pre-training of Deep Bidirectional Transformers For Language Understanding。 BERT用这些结果获得了整个领域的兴趣,并引发了一波新的提交,每一个都采用了基于BERT变换器的方法并对其进行了修改。从2019年底的GLUE排行榜上看,最初的BERT投稿一路下滑至第17位。
最令人印象深刻的是,人类的基线分数最近被加入了排行榜,因为模特的表现明显提高到了被超越的程度。果不其然,在几个月的时间里,人类的基准线下降到了8点,完全超过了平均分和几乎所有的个人任务表现。当你读到这篇文章的时候,人类的基线可能会更低。
与2012年用于图像处理的卷积神经网络的出现类似,这种在可实现的模型性能方面令人印象深刻的快速增长为新的NLP应用打开了闸门。
Try out BERT
现在,很多人想试试BERT。对于用户来说,问答过程是相当先进和有趣的。从我们的步骤开始。
之前的一篇文章,实时自然语言理解与BERT使用TensorRT,检查如何建立和运行BERT使用aNVIDIA
NGC网站容器为TensorRT。我们建议使用它。我们可以访问运行Ubuntu 16.04.6lts的NVIDIA V100 GPU。如果驱动器空间对您来说有问题,请使用/tmp区域,方法是在post中的步骤之前使用以下命令:
cd/tmp
此外,我们还找到了另一个可能有帮助的选择。确保python/create_docker_container.sh路径访问的脚本从底部开始的第三行如下:
-v ${PWD}/models:/models \
另外,在后面直接添加一行,内容如下:
-v H O M E : {HOME}: HOME:{HOME} \
在成功进入文章的第五步之后,您可以运行它,然后替换-p “…” -q "What is TensorRT?"段落和问题shell命令部分,如下命令所示。这与本文前面描述的美式足球问题重复。
python/bert_inference.py -e bert_base_384.engine -p
匹兹堡钢人队是一支总部位于宾夕法尼亚州匹兹堡的职业美式足球队。钢人队作为美国足球协会(AFC)东区的会员俱乐部参加国家足球联盟(NFL)的比赛。该队在海因茨球场进行主场比赛。钢铁工人去年赚了43900000美元。他们的四分卫叫本·罗特利斯伯格。罗斯伯格已经在处理肘部问题了。本被后援梅森·鲁道夫接替。他的第一个传球被接球手蒙克里夫的手反弹拦截,但鲁道夫在下半场反弹,以16分领先三个得分球。这还不足以阻止钢人队以0-2落后,在过去的12年里,大约90%以0-2领先的球队错过了季后赛。这些可能性可能已经让钢人队的球迷们开始考虑明年的比赛了,很难不去想罗斯伯格的未来。
" -q “Who replaced Ben?” -v /workspace/models/fine tuned/bert_tf_v2_base_fp16_384_v2/vocab.txt -b 1
要用其他问题来尝试这个足球段落,请更改-q "Who replaced Ben?"选择和价值与另一个类似的问题。
对于预训练和微调的两阶段方法,对于NVIDIA金融服务客户,有一个BERT-GPU训练营可用。