主题模型TopicModel:Unigram、LSA、PLSA主题模型详解
http://blog.csdn.net/pipisorry/article/details/42560693
主题模型历史:
Papadimitriou、Raghavan、Tamaki和Vempala在1998年发表的一篇论文中提出了潜在语义索引。1999年,Thomas Hofmann又在此基础上,提出了概率性潜在语义索引(Probabilistic Latent Semantic Indexing,简称PLSI)。
隐含狄利克雷分配LDA可能是最常见的主题模型,是一般化的PLSI,由Blei, David M.、吴恩达和Jordan, Michael I于2003年提出。LDA允许文档拥有多种主题。其它主体模型一般是在LDA基础上改进的。例如Pachinko分布在LDA度量词语关联之上,还加入了主题的关联度。

文本建模-理解LDA模型的基础模型:
Unigram model、mixture of unigrams model,以及pLSA模型。
定义变量:
 表示词,
表示词,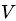 表示所有单词的个数(固定值)
表示所有单词的个数(固定值)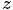 表示主题,
表示主题,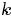 是主题的个数(预先给定,固定值)
是主题的个数(预先给定,固定值)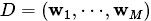 表示语料库,其中的
表示语料库,其中的 是语料库中的文档数(固定值)
是语料库中的文档数(固定值)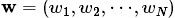 表示文档,其中的
表示文档,其中的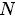 表示一个文档中的词数(随机变量)
表示一个文档中的词数(随机变量)
Unigram model
对于文档,用 表示词
表示词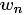 的先验概率,生成文档
的先验概率,生成文档 的概率为:
的概率为:

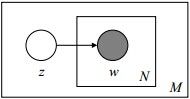
其图模型为(图中被涂色的w表示可观测变量,N表示一篇文档中总共N个单词,M表示M篇文档):
或为:
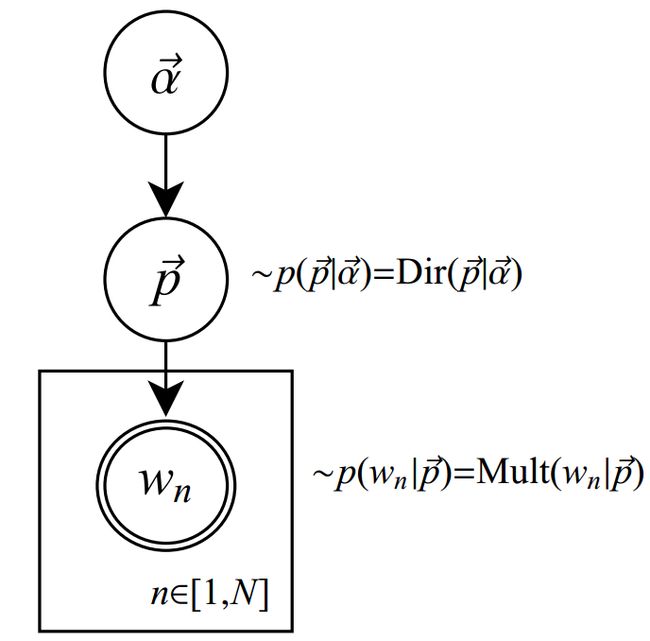
unigram model假设文本中的词服从Multinomial分布,而我们已经知道Multinomial分布的先验分布为Dirichlet分布。 上图中的 表示在文本中观察到的第n个词,n∈[1,N]表示该文本中一共有N个单词。加上方框表示重复,即一共有N个这样的随机变量。其中,p和α是隐含未知变量:
表示在文本中观察到的第n个词,n∈[1,N]表示该文本中一共有N个单词。加上方框表示重复,即一共有N个这样的随机变量。其中,p和α是隐含未知变量:
- p是词服从的Multinomial分布的参数
- α是Dirichlet分布(即Multinomial分布的先验分布)的参数。
一般α由经验事先给定,p由观察到的文本中出现的词学习得到,表示文本中出现每个词的概率。
最简单的 Unigram Model:
假设我们的词典中一共有 V 个词 v1,v2,⋯vV ,那么最简单的 Unigram Model 就是认为上帝是按照如下的游戏规则产生文本的。

上帝的这个唯一的骰子各个面的概率记为 p→=(p1,p2,⋯,pV) , 所以每次投掷骰子类似于一个抛钢镚时候的贝努利实验, 记为 w∼Mult(w|p→) 。
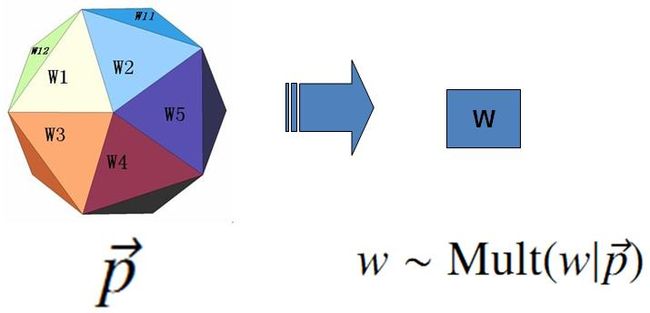
上帝投掷 V 个面的骰子
对于一篇文档 d=w→=(w1,w2,⋯,wn) , 该文档被生成的概率就是
而文档和文档之间我们认为是独立的, 所以如果语料中有多篇文档 W=(w1−→,w2−→,…,wm−→) ,则该语料的概率是
在 Unigram Model 中假设了文档之间是独立可交换的,而文档中的词也是独立可交换的,所以一篇文档相当于一个袋子,里面装了一些词,而词的顺序信息就无关紧要了,这样的模型也称为词袋模型(Bag-of-words)。
假设语料中总的词频是 N , 在所有的 N 个词中,如果我们关注每个词 vi 的发生次数 ni ,那么 n→=(n1,n2,⋯,nV) 正好是一个多项分布
当然,我们很重要的一个任务就是估计模型中的参数 p→ ,也就是问上帝拥有的这个骰子的各个面的概率是多大,按照统计学家中频率派的观点,使用最大似然估计最大化 P(W) ,于是参数 pi 的估计值就是
贝叶斯观点下的 Unigram Model:
对于以上模型,贝叶斯统计学派的统计学家会有不同意见,他们会很挑剔的批评只假设上帝拥有唯一一个固定的骰子是不合理的。在贝叶斯学派看来,一切参数都是随机变量,以上模型中的骰子 p→ 不是唯一固定的,它也是一个随机变量。所以按照贝叶斯学派的观点,上帝是按照以下的过程在玩游戏的

上帝的这个坛子里面,骰子可以是无穷多个,有些类型的骰子数量多,有些类型的骰子少,所以从概率分布的角度看,坛子里面的骰子 p→ 服从一个概率分布 p(p→) ,这个分布称为参数 p→ 的先验分布。
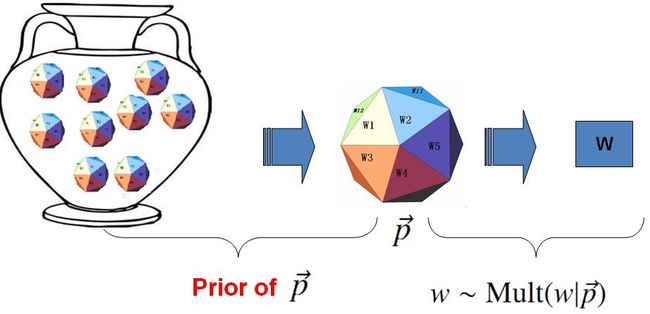
贝叶斯观点下的 Unigram Model
以上贝叶斯学派的游戏规则的假设之下,语料 W 产生的概率如何计算呢?由于我们并不知道上帝到底用了哪个骰子 p→ ,所以每个骰子都是可能被使用的,只是使用的概率由先验分布 p(p→) 来决定。对每一个具体的骰子 p→ ,由该骰子产生数据的概率是 p(W|p→) , 所以最终数据产生的概率就是对每一个骰子 p→ 上产生的数据概率进行积分累加求和
在贝叶斯分析的框架下,此处先验分布 p(p→) 就可以有很多种选择了,注意到 P(n→)=Mult(n→|p→,N)
实际上是在计算一个多项分布的概率,所以对先验分布的一个比较好的选择就是多项分布对应的共轭分布,即 Dirichlet 分布
此处, Δ(α→) 就是归一化因子 Dir(α→) ,即
Δ(α→)=∫∏k=1Vpαk−1kdp→.
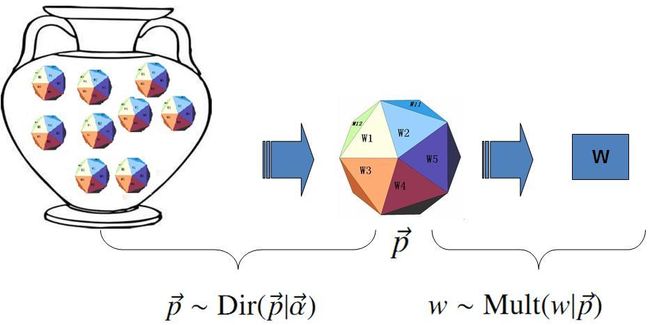
Dirichlet 先验下的 Unigram Model
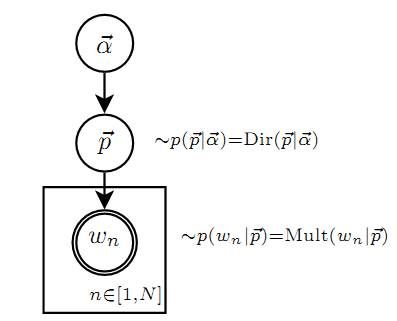
Unigram Model的概率图模型
Dirichlet 先验 + 多项分布的数据 → 后验分布为 Dirichlet 分布
于是,在给定了参数 p→ 的先验分布 Dir(p→|α→) 的时候,各个词出现频次的数据 n→∼Mult(n→|p→,N) 为多项分布, 所以无需计算,我们就可以推出后验分布是
贝叶斯的框架下参数 p→ 的估计:由于我们已经有了参数的后验分布,所以合理的方式是使用后验分布的极大值点,或者是参数在后验分布下的平均值。在该文档中,我们取平均值作为参数的估计值。使用上个小节中的结论,由于 p→ 的后验分布为 Dir(p→|n→+α→) ,于是
也就是说对每一个 pi , 我们用下式做参数估计
考虑到 αi 在 Dirichlet 分布中的物理意义是事件的先验的伪计数,这个估计式子的含义是很直观的:每个参数的估计值是其对应事件的先验的伪计数和数据中的计数的和在整体计数中的比例。
进一步,我们可以计算出文本语料的产生概率为
,Δ(α→)=∫∏k=1Vpαk−1kdp→
Mixture of unigrams model
,再根据该主题生成文档,该文档中的所有词都来自一个主题。假设主题有 ,生成文档{语料}的概率为:
,生成文档{语料}的概率为:

PLSA模型
{pLSA样本随机,参数虽未知但固定,属于频率派思想;区别LDA样本固定,参数未知但不固定,是个随机变量,服从一定的分布,LDA属于贝叶斯派思想}
pLSA模型
Hoffman 于 1999 年给出的PLSA(Probabilistic Latent Semantic Analysis) 模型中首先进行了明确的数学化。Hoffman 认为一篇文档(Document) 可以由多个主题(Topic) 混合而成, 而每个Topic 都是词汇上的概率分布,文章中的每个词都是由一个固定的 Topic 生成的。下图是英语中几个Topic 的例子。
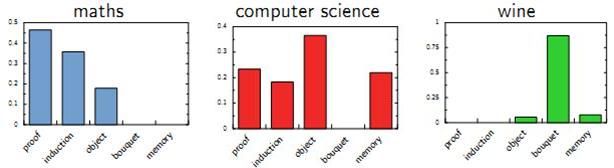
Topic 就是Vocab 上的概率分布
PLSA的文档生成模型
- 1. 假设你每写一篇文档会制作一颗K面的“文档-主题”骰子(扔此骰子能得到K个主题中的任意一个),和K个V面的“主题-词项” 骰子(每个骰子对应一个主题,K个骰子对应之前的K个主题,且骰子的每一面对应要选择的词项,V个面对应着V个可选的词)。
- 比如可令K=3,即制作1个含有3个主题的“文档-主题”骰子,这3个主题可以是:教育、经济、交通。然后令V = 3,制作3个有着3面的“主题-词项”骰子,其中,教育主题骰子的3个面上的词可以是:大学、老师、课程,经济主题骰子的3个面上的词可以是:市场、企业、金融,交通主题骰子的3个面上的词可以是:高铁、汽车、飞机。
- 2. 每写一个词,先扔该“文档-主题”骰子选择主题,得到主题的结果后,使用和主题结果对应的那颗“主题-词项”骰子,扔该骰子选择要写的词。 {每篇文档有不同的 文档-主题 骰子}
- 先扔“文档-主题”的骰子,假设(以一定的概率)得到的主题是教育,所以下一步便是扔教育主题筛子,(以一定的概率)得到教育主题筛子对应的某个词:大学。
- 上面这个投骰子产生词的过程简化下便是:“先以一定的概率选取主题,再以一定的概率选取词”。事实上,一开始可供选择的主题有3个:教育、经济、交通,那为何偏偏选取教育这个主题呢?其实是随机选取的,只是这个随机遵循一定的概率分布。比如3个主题的概率分布是{教育:0.5,经济:0.3,交通:0.2},我们把各个主题z在文档d中出现的概率分布称之为主题分布,且是一个多项分布。
- 同样的,从主题分布中随机抽取出教育主题后,依然面对着3个词:大学、老师、课程,这3个词都可能被选中,但它们被选中的概率也是不一样的。比如3个词的概率分布是{大学:0.5,老师:0.3,课程:0.2},我们把各个词语w在主题z下出现的概率分布称之为词分布,这个词分布也是一个多项分布。
- 先扔“文档-主题”的骰子,假设(以一定的概率)得到的主题是教育,所以下一步便是扔教育主题筛子,(以一定的概率)得到教育主题筛子对应的某个词:大学。
- 所以,选主题和选词都是两个随机的过程,先从主题分布{教育:0.5,经济:0.3,交通:0.2}中抽取出主题:教育,然后从该主题对应的词分布{大学:0.5,老师:0.3,课程:0.2}中抽取出词:大学。

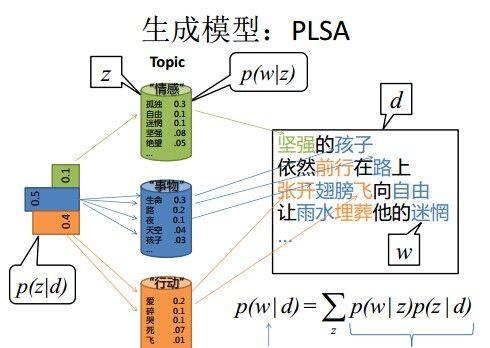
- 3. 最后,你不停的重复扔“文档-主题”骰子和”主题-词项“骰子,重复N次(产生N个词),完成一篇文档,重复这产生一篇文档的方法M次,则完成M篇文档。
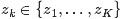 。
。变量定义
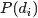 表示海量文档中某篇文档被选中的概率。
表示海量文档中某篇文档被选中的概率。
 表示词
表示词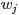 在给定文档
在给定文档 中出现的概率。
中出现的概率。
- 怎么计算得到呢?针对海量文档,对所有文档进行分词后,得到一个词汇列表,这样每篇文档就是一个词语的集合。对于每个词语,用它在文档中出现的次数除以文档中词语总的数目便是它在文档中出现的概率。
- 怎么计算得到呢?针对海量文档,对所有文档进行分词后,得到一个词汇列表,这样每篇文档就是一个词语的集合。对于每个词语,用它在文档中出现的次数除以文档中词语总的数目便是它在文档中出现的概率
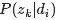 表示具体某个主题
表示具体某个主题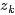 在给定文档下出现的概率。
在给定文档下出现的概率。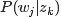 表示具体某个词在给定主题
表示具体某个词在给定主题 下出现的概率,与主题关系越密切的词,其条件概率越大。
下出现的概率,与主题关系越密切的词,其条件概率越大。
- 按照概率选择一篇文档
- 选定文档后,从主题分布中按照概率选择一个隐含的主题类别
- 选定后,从词分布中按照概率选择一个词
这个利用看到的文档推断其隐藏的主题(分布)的过程(其实也就是产生文档的逆过程),便是主题建模的目的:自动地发现文档集中的主题(分布)。
 是已知的。
,训练出文档-主题
和
主题-词项
,如下公式所示:
是已知的。
,训练出文档-主题
和
主题-词项
,如下公式所示:

{P(di)应该都一样吧-}
由于可事先计算求出,而和未知,所以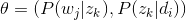 就是我们要估计的参数(值),通俗点说,就是要最大化这个θ。
就是我们要估计的参数(值),通俗点说,就是要最大化这个θ。
常用的参数估计方法有极大似然估计MLE、最大后验证估计MAP、贝叶斯估计等等。因为该待估计的参数中含有隐变量z,所以我们可以考虑EM算法。
EM算法的简单介绍
EM算法,全称为Expectation-maximization algorithm,为期望最大算法,其基本思想是:首先随机选取一个值去初始化待估计的值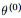 ,然后不断迭代寻找更优的
,然后不断迭代寻找更优的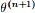 使得其似然函数likelihood
使得其似然函数likelihood  比原来的
比原来的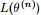 要大。换言之,假定现在得到了
要大。换言之,假定现在得到了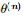 ,想求
,想求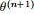 ,使得
,使得
EM的关键便是要找到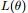 的一个下界
的一个下界 (注:
(注: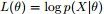 ,其中,X表示已经观察到的随机变量),然后不断最大化这个下界,通过不断求解下界的极大化,从而逼近要求解的似然函数。
,其中,X表示已经观察到的随机变量),然后不断最大化这个下界,通过不断求解下界的极大化,从而逼近要求解的似然函数。
所以EM算法的一般步骤为:
- 1. 随机选取或者根据先验知识初始化;
- 2. 不断迭代下述两步
- ①给出当前的参数估计,计算似然函数的下界
- ②重新估计参数θ,即求,使得
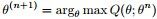
- ①给出当前的参数估计
- 3. 上述第二步后,如果收敛(即收敛)则退出算法,否则继续回到第二步。
上述过程好比在二维平面上,有两条不相交的曲线,一条曲线在上(简称上曲线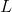 ),一条曲线在下(简称下曲线
),一条曲线在下(简称下曲线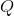 ),下曲线为上曲线的下界。现在对上曲线未知,只已知下曲线,为了求解上曲线的最高点,我们试着不断增大下曲线,使得下曲线不断逼近上曲线,下曲线在某一个点达到局部最大值并与上曲线在这点的值相等,记录下这个值,然后继续增大下曲线,寻找下曲线上与上曲线上相等的值,迭代到收敛(即收敛)停止,从而利用当前下曲线上的局部最大值当作上曲线的全局最大值(换言之,EM算法不保证一定能找到全局最优值)。如下图所示:
),下曲线为上曲线的下界。现在对上曲线未知,只已知下曲线,为了求解上曲线的最高点,我们试着不断增大下曲线,使得下曲线不断逼近上曲线,下曲线在某一个点达到局部最大值并与上曲线在这点的值相等,记录下这个值,然后继续增大下曲线,寻找下曲线上与上曲线上相等的值,迭代到收敛(即收敛)停止,从而利用当前下曲线上的局部最大值当作上曲线的全局最大值(换言之,EM算法不保证一定能找到全局最优值)。如下图所示:

PLSA算法的EM推导详细介绍
假定有训练集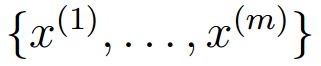 ,包含m个独立样本,希望从中找到该组数据的模型p(x,z)的参数。
,包含m个独立样本,希望从中找到该组数据的模型p(x,z)的参数。
然后通过极大似然估计建立目标函数--对数似然函数:

{规范地,x -> xi} {
}【p(x|theta)和p(x;theta)的区别】
这里,z是隐随机变量,直接找到参数的估计是很困难的。我们的策略是建立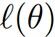 的下界,并且求该下界的最大值;重复这个过程,直到收敛到局部最大值。
的下界,并且求该下界的最大值;重复这个过程,直到收敛到局部最大值。
令Qi是z的某一个分布(表达式待会可以求解出来),Qi≥0,且结合Jensen不等式,有:
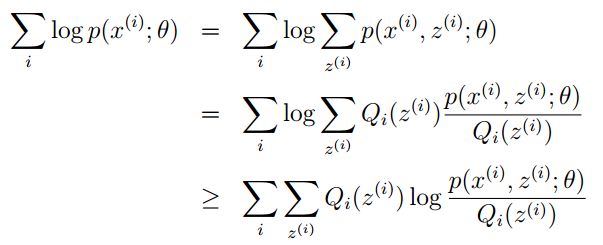
[TopicModel - EM算法]
为了寻找尽量紧的下界,我们可以让使上述等号成立,而若要让等号成立的条件则是:

换言之,有以下式子成立: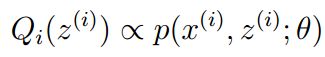 ,且由于有:
,且由于有:
所以可得:
{the distribution of zi given xi and parameterized by theta,e.g. Qi(Zi) = theta0^x0*theta1^x1*... -}
最终得到EM算法的整体框架:
{E步中,是通过上次的p(z|d)和p(w|z)求出p(x,z;theta)的}
EM算法估计pLSA的两未知参数(对应上面的框架)
首先尝试从矩阵的角度来描述待估计的两个未知变量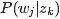 和
和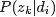 。
。
- 假定用
 表示词表
表示词表 在主题
在主题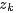 上的一个多项分布,则
上的一个多项分布,则 可以表示成一个向量,每个元素
可以表示成一个向量,每个元素 表示词项
表示词项 出现在主题中的概率,即
出现在主题中的概率,即
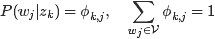
- 用
 表示所有主题
表示所有主题 在文档
在文档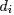 上的一个多项分布,则
上的一个多项分布,则 可以表示成一个向量,每个元素
可以表示成一个向量,每个元素 表示主题出现在文档中的概率,即
表示主题出现在文档中的概率,即
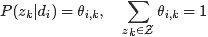
这样,巧妙的把和转换成了两个矩阵。换言之,最终我们要求解的参数是这两个矩阵:
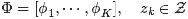
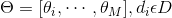
由于词和词之间是相互独立的,所以整篇文档N个词的分布为:
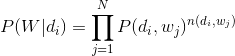
再由于文档和文档之间也是相互独立的,所以整个语料库中词的分布为(整个语料库M篇文档,每篇文档N个词):
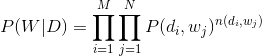
其中, 表示词项在文档中的词频,
表示词项在文档中的词频,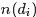 表示文档di中词的总数,显然有
表示文档di中词的总数,显然有
从而得到整个语料库的词分布的对数似然函数(下述公式中有个小错误,正确的应该是:N为M,M为N):
{note:1)步的推导:
其中∑ P(wj|zk)P(zk|di) = P(wj|di)的推导:
{条件概率的全概率并且我们是按照如下方式得到“词-文档”的生成模型的:
1. 按照概率P(di)选择一篇文档di
2. 按照概率P(zk|di)选择一个隐含的主题类别zk
3. 按照概率P(wj|zk)生成一个词wj
根据操作的物理意义 P(wj,zk,di) = P(wj,zk)如果从PLSA的话,模型本身就设定w与d无关的按照这个顺序操作的话 P(wj|zk,di) 确实等于 P(wj|zk);因为主题zk都是从文章di中选的,词wi又都是从主题zk中选的,所以这里的词wi都是从文章di中选的
对于word只关注来自哪个topic,不关注来自哪个doc-} }
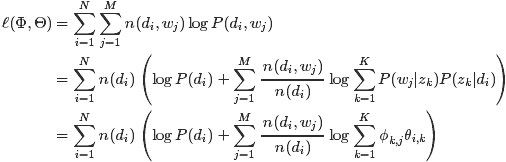
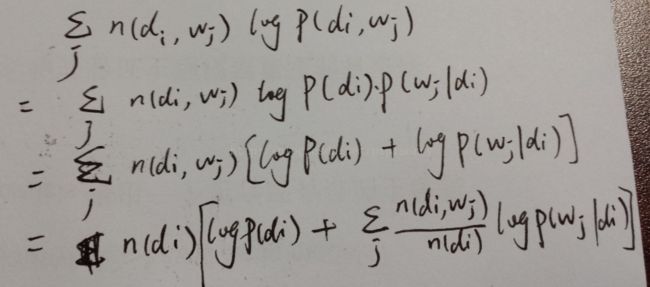
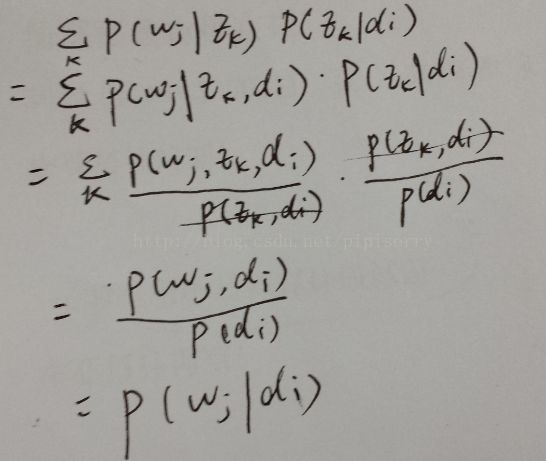
现在,我们需要最大化上述这个对数似然函数来求解参数和。对于这种含有隐变量的最大似然估计,可以使用EM算法。
- E-step:假定参数已知,计算此时隐变量的后验概率。
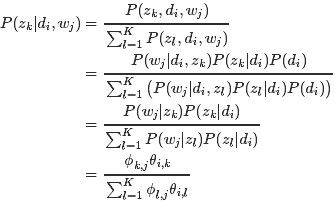
{步骤中,我们假定所有的
和
都是已知的,初始时随机赋值,后面迭代的过程中取前一轮M步骤中得到的参数值。}
- M-step:带入隐变量的后验概率,最大化样本分布的对数似然函数,求解相应的参数。
观察之前得到的对数似然函数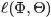 的结果,由于文档长度
的结果,由于文档长度 可以单独计算,所以去掉它不影响最大化似然函数。
可以单独计算,所以去掉它不影响最大化似然函数。
![]()
此外,根据E-step的计算结果,把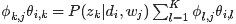 代入,于是我们只要最大化下面这个函数
代入,于是我们只要最大化下面这个函数 {E()}即可(下述公式中有个小错误,正确的应该是:N为M,M为N):
{E()}即可(下述公式中有个小错误,正确的应该是:N为M,M为N):
E
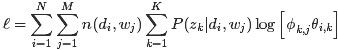
{TopicModel - EM算法 - Lazy Statistician规则:E(z) = ∑P(zk|di, wj)z中z替换成L式, 相当于把其中与z相关的部分积分掉
TopicModel - EM算法 最大化Complete data对数似然函数的期望(即把其中与z相关的部分积分掉)}

这是一个多元函数求极值问题,并且已知有如下约束条件(下述公式中有个小错误,正确的应该是:M为N):
(1)
凸优化中,一般处理这种带有约束条件的极值问题,常用的方法便是拉格朗日乘数法,即通过引入拉格朗日乘子将约束条件和多元(目标)函数融合到一起,转化为无约束条件的极值问题。
这里我们引入两个拉格朗日乘子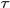 和
和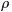 ,从而写出拉格朗日函数(下述公式中有个小错误,正确的应该是:N为M,M为N):
,从而写出拉格朗日函数(下述公式中有个小错误,正确的应该是:N为M,M为N):

因为我们要求解的参数是和,所以分别对和求偏导,然后令偏导结果等于0,得到(下述公式中有个小错误,正确的应该是:N为M,M为N):
(2)
消去拉格朗日乘子,最终可估计出参数和(下述公式中有个小错误,正确的应该是:N为M,M为N):
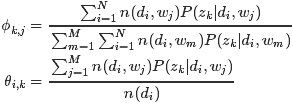
{注意这里进行过方程两边同时乘以和的变形},联立上面4组方程(1)(2),我们就可以解出M步骤中通过最大化期望估计出的新的参数值
解方程组的关键在于先求出 ,其实只需要做一个加和运算就可以把的系数都化成1,后面就好计算了}
,其实只需要做一个加和运算就可以把的系数都化成1,后面就好计算了}
【TopicModel - PLSA模型及PLSA的EM推导】
然后使用更新后的参数值,我们又进入E步骤,计算隐含变量 Given当前估计的参数条件下的后验概率。如此不断迭代,直到满足终止条件。
Given当前估计的参数条件下的后验概率。如此不断迭代,直到满足终止条件。
from:http://blog.csdn.net/pipisorry/article/details/42560693
ref: 1.TopicModel - LSA(隐性语义分析)的早期方法SVD
2.TopicModel - EM算法及PLSA的EM推导
3.TopicModel - LDA详解