表格问答1:简介
在公众号的第一篇文章中我们介绍了一个厉害的开放域问答系统REALM,它主要解决的问题是从知识库中找到问题相关的文章并从文章中找到问题的答案。REALM这种直接从文章中获取答案的设定在问答领域称为非结构化文档问答,而接下来我们将用几篇文章介绍一下与之相对应的结构化文档问答中的一个重要分支表格问答。
什么是表格问答
表格其实是一种信息密度很高的文档类型,与文章相比,更加适合作为电商、查询场景的知识源。用表格来提供信息不仅方便业务端梳理知识,而且结构化的数据给算法端进行信息聚合、比较甚至推理提供了更肥沃的土壤。
下图是MSRA18年底发的一篇文章的插图,里面对整个表格相关NLP问题有一个比较完整的呈现。其中涉及了检索、语义解析、生成和对话等多个方向。
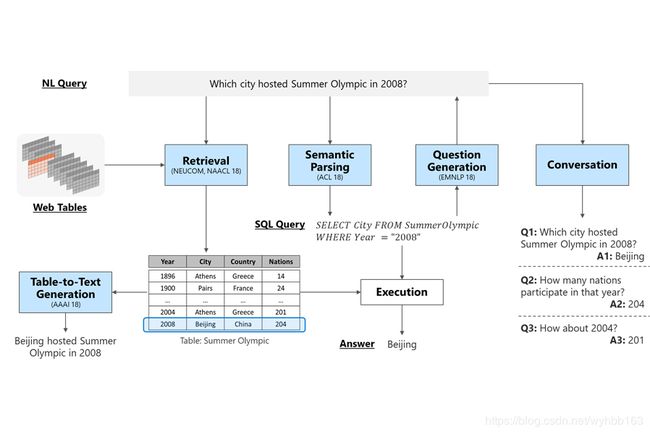
如图所示,表格问答就是针对一个自然语言问题,根据表格内容给出答案。
表格问答主要涉及的是图中检索和语义解析两个模块。检索模块在文档问答里也有,文档问答的检索模块是为了找到和问题相关的文档,而表格问答里检索模块的目标则是找到和问题相关的表格。这个模块只有在涉及大量表格,例如搜索引擎,的时候才会用到。
语义解析是和文档问答中差别比较大的部分。在文档问答中是使用一个reader模型来处理检索到的文档(context),而表格问答的侧重点则是处理问题(query)。语义解析模型的目标是结合表格信息将问题(如图中的Which city hosted Summer Olympic in 2008?)转化成一个机器可理解和执行的规范语义表示,对二维表而言这种表示通常就是SQL语句(如图中的SELECT City FROM SummerOlympic WHERE Year="2008")。有了SQL语句就可以执行得到针对问题的答案(如图中的Beijing)。
在不需要表格检索的场景中,表格问答就简化成了一个自然语言转SQL(nl2sql)问题,我们后面的介绍也主要聚焦在nl2sql这个问题上。
NL2SQL数据集
我认为语义解析算是NLP界“最初的梦想”了,NL2SQL由于其实用性渐渐成为了语义解析领域一个重要的方向,近几年也诞生了很多有代表性的nl2sql数据集。
英语世界两个比较有代表性的是WikiSQL和Spider;去年国内的追一科技在天池平台上举办过一次中文nl2sql挑战赛,为中文NLP世界贡献了一个高质量的数据集。
WikiSQL相对比较简单,也比较典型。数据集分为两个部分:问题和表格数据。
下面是一个问题的例子,可以看出WikiSQL里的查询语句并不会太难,而且多数预测目标可以建模分类问题进行解决。
{
"phase":1,
"question":"who is the manufacturer for the order year 1998?",
"sql":{
"conds":[
[
0,
0,
"1998"
]
],
"sel":1,
"agg":0
},
"table_id":"1-10007452-3"
}
其中
question是自然语言问题table_id是与这个这个问题相关的表格编号sql字段是标签数据。这个数据集进一步把SQL语句结构化(简化),分成了conds,sel,agg三个部分。sel是查询目标列,其值是表格中对应列的序号agg的值是聚合操作的编号,可能出现的聚合操作有['', 'MAX', 'MIN', 'COUNT', 'SUM', 'AVG']共6种。conds是筛选条件,可以有多个。每个条件用一个三元组(column_index, operator_index, condition)表示,可能的operator_index共有['=', '>', '<', 'OP']四种,condition是操作的目标值,这是不能用分类解决的目标。
WikiSQL是针对单表场景的数据集,每一个问题只会对应一张表格。表格数据大概长下面这个样子,其中id与问题中的table_id对应,header是表头信息,types是每一列的数据类型,rows则是每一行数据。
{
"id":"1-1000181-1",
"header":[
"State/territory",
"Text/background colour",
"Format",
"Current slogan",
"Current series",
"Notes"
],
"types":[
"text",
"text",
"text",
"text",
"text",
"text"
],
"rows":[
[
"Australian Capital Territory",
"blue/white",
"Yaa\u00b7nna",
"ACT \u00b7 CELEBRATION OF A CENTURY 2013",
"YIL\u00b700A",
"Slogan screenprinted on plate"
],
[
"New South Wales",
"black/yellow",
"aa\u00b7nn\u00b7aa",
"NEW SOUTH WALES",
"BX\u00b799\u00b7HI",
"No slogan on current series"
]
]
}
Spider数据集比WikiSQL困难,它需要构造的SQL语句更加复杂,而且有的问题需要做多张表的聚合。下图是Spider数据集里一些不同难度查询语句的例子,WikiSQL基本上处在其中的easy水平。

中文NL2SQL数据集的形式几乎和WikiSQL一模一样,但难度高出不少。它更加接近业务场景一些,主要体现在表格内容非常丰富、自然语言问题的表达也更加多样。这两点从当时比赛冠军的答辩ppt里就可见一二。要取得好成绩需要做很多文本规范化的工作。

性能评价
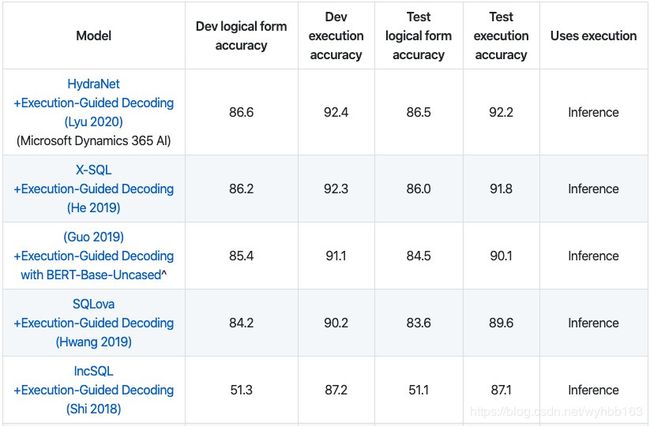
NL2SQL一般有两种评价方式,一种是直接比较生成的SQL与标签的差别,另一种是比较生成的SQL执行结果与标签SQL执行结果的差别。在WikiSQL中这两个指标分别称为logical form accuracy和execution accuracy。由于不同的SQL语句可能产生相同的结果,所以用后一种评价方式的得分一般高于前一种。
Spider原来的评价指标比较接近于logical form acc,今年刚开放了execution acc赛道。由于难度有差异,目前模型在各数据集上的水平也有一些差别。WikiSQL目前排行榜上第一名的执行准确率已经达到92%,逻辑形式准确率也达到了86.5%,而Spider由于难度更大,SOTA成绩只有61.9%。
以上就是今天的全部内容,相信你已经对NL2SQL问题有了一个比较直观的了解。后面我打算再写两篇关于表格问答算法和落地产品的文章。下一期将会先介绍来自微软的两个相继在WikiSQL获得SOTA成绩的模型HydraNet和X-SQL,不要错过哦。
原文首发在公众号:朴素人工智能。欢迎关注!
