BP神经网络(四)--梯度下降法python实例
下面我们将用python实现一个简单的梯度下降算法。场景是一个简单的线性回归的例子:假设现在我们有一系列的点,如下图所示:

从图上可以看出横坐标x的取值范围是0到20,近似于一条直线。这里用梯度下降法来拟合这条曲线。由于这条曲线近似于直线,所以用线性方程做拟合。我们假设线性方程式为:
h ( Θ ) ( x ( i ) ) = Θ 0 + Θ 1 x ( i ) h_{(\Theta)}(x^{(i)})=\Theta_0+\Theta_1x^{(i)} h(Θ)(x(i))=Θ0+Θ1x(i)
此为假设的预测函数,根据每一个输入点 x ( i ) x^{(i)} x(i)。会有一个预测的输出值 h ( Θ ) ( x ( i ) ) h_{(\Theta)}(x^{(i)}) h(Θ)(x(i)), Θ 0 、 Θ 1 \Theta_0、\Theta_1 Θ0、Θ1为待求的参数。
我们再来定义一个代价函数,这里选用均方误差代价函数:
J ( Θ ) = 1 2 m ∑ i = 1 m ( h ( Θ ) ( x ( i ) ) − y ( i ) ) 2 J(\Theta) = \frac{1}{2m}\sum_{i=1}^m(h_{(\Theta)}(x^{(i)}) - y^{(i)})^2 J(Θ)=2m1i=1∑m(h(Θ)(x(i))−y(i))2
上式中,m为数据集中点的个数。
1 2 \frac{1}{2} 21是为了求导方便加入的,因为在求梯度时,二次方乘下来就和这里 1 2 \frac{1}{2} 21抵消了,方便后续的计算,对结果不会有影响。
y ( i ) 是 数 据 集 中 每 个 点 的 真 实 y 坐 标 的 值 。 y^{(i)}是数据集中每个点的真实y坐标的值。 y(i)是数据集中每个点的真实y坐标的值。
h ( Θ ) ( x ( i ) ) h_{(\Theta)}(x^{(i)}) h(Θ)(x(i))是我们刚刚定义的预测函数,根据每一个输入 x ( i ) x^{(i)} x(i),根据 Θ ( Θ 0 , Θ 1 ) \Theta(\Theta_0,\Theta_1) Θ(Θ0,Θ1)计算得到预测的纵坐标值。
我们知道函数在一个已知点的梯度的反方向上,下降最快,所以要通过对代价函数进行梯度下降法,使得计算次数最小。在用梯度下降法进行多次迭代后,使均方误差代价函数的值小于某个给定的阈值,此时的 Θ ( Θ 0 , Θ 1 ) \Theta(\Theta_0,\Theta_1) Θ(Θ0,Θ1)为满足条件的最优化参数,那么线性方程式也就确定了。
根据代价函数看到,代价函数中的变量有两个,所以是一个多变量的梯下降问题,求解出代价函数的梯度,也就是分别对两个变量进行求偏导:
Δ J ( Θ ) = ⟨ δ J δ Θ 0 , δ J δ Θ 1 ⟩ \Delta J(\Theta) = \left\langle \frac{\delta J}{\delta \Theta_0},\frac{\delta J}{\delta \Theta_1} \right\rangle ΔJ(Θ)=⟨δΘ0δJ,δΘ1δJ⟩
δ J δ Θ 0 = 1 m ∑ i = 1 m ( h ( Θ ) ( x ( i ) ) − y ( i ) ) \frac{\delta J}{\delta \Theta_0}=\frac{1}{m}\sum_{i=1}^m(h_{(\Theta)}(x^{(i)}) - y^{(i)}) δΘ0δJ=m1i=1∑m(h(Θ)(x(i))−y(i))
δ J δ Θ 1 = 1 m ∑ i = 1 m ( h ( Θ ) ( x ( i ) ) − y ( i ) ) x ( i ) \frac{\delta J}{\delta \Theta_1}=\frac{1}{m}\sum_{i=1}^m(h_{(\Theta)}(x^{(i)}) - y^{(i)})x^{(i)} δΘ1δJ=m1i=1∑m(h(Θ)(x(i))−y(i))x(i)
为了方便代码的编写,将所有的公式都转换为矩阵的形式,Python中计算矩阵是非常方便的,同时代码也会变得非常的简洁:
h ( Θ ) ( x ( i ) ) = Θ 0 + Θ 1 x ( i ) h_{(\Theta)}(x^{(i)})=\Theta_0+\Theta_1x^{(i)} h(Θ)(x(i))=Θ0+Θ1x(i)
有两个变量,为了对这个公式进行矩阵化,给每一个点x增加一维,这一维的 值固定为1,这一维将会乘到 Θ 0 \Theta_0 Θ0上。这样就方便统一矩阵化的计算。
之前的 x ( i ) x^{(i)} x(i)变成 ( 1 , x ( i ) ) (1,x^{(i)}) (1,x(i))。 h ( Θ ) ( x ( i ) ) = Θ 0 + Θ 1 x ( i ) h_{(\Theta)}(x^{(i)})=\Theta_0+\Theta_1x^{(i)} h(Θ)(x(i))=Θ0+Θ1x(i)对于每一个点就变成了:
( 1 , x ( i ) ) ∗ ( Θ 0 Θ 1 ) (1,x^{(i)})* \begin{pmatrix} \Theta_0 \\ \Theta_1\\ \end{pmatrix} (1,x(i))∗(Θ0Θ1)
m个点的矩阵形式为:
( 1 x ( 1 ) . . . . . . 1 x ( m ) ) ∗ ( Θ 0 Θ 1 ) \begin{pmatrix} 1 & x^{(1)} \\ ...&...\\ 1 & x^{(m)}\\ \end{pmatrix}* \begin{pmatrix} \Theta_0 \\ \Theta_1\\ \end{pmatrix} ⎝⎛1...1x(1)...x(m)⎠⎞∗(Θ0Θ1)
为了方便表示,另 X = ( 1 x ( 1 ) . . . . . . 1 x ( m ) ) , Θ = ( Θ 0 Θ 1 ) X = \begin{pmatrix} 1 & x^{(1)} \\ ...&...\\ 1 & x^{(m)}\\ \end{pmatrix},\Theta = \begin{pmatrix} \Theta_0 \\ \Theta_1\\ \end{pmatrix} X=⎝⎛1...1x(1)...x(m)⎠⎞,Θ=(Θ0Θ1)
然后将代价函数和梯度转化为矩阵向量相乘的形式:
J ( Θ ) = 1 2 m ( X Θ − y → ) T ( X Θ − y → ) J(\Theta) = \frac{1}{2m}(X\Theta - \overrightarrow{y})^T(X\Theta - \overrightarrow{y}) J(Θ)=2m1(XΘ−y)T(XΘ−y)
Δ J ( Θ ) = 1 m X T ( X Θ − y → ) \Delta J(\Theta) = \frac{1}{m}X^T(X\Theta - \overrightarrow{y}) ΔJ(Θ)=m1XT(XΘ−y)
下面为代码实现部分:
首先定义数据集和学习率:
import numpy as np
m = 20 #数据集个数
X0 = np.ones((m,1))
X2 = np.arange(1,m+1)
X1 = X2.reshape(m,1)
X = np.hstack((X0,X1))
y = np.array([3,4,5,5,2,4,7,8,11,8,12,11,13,13,16,17,18,17,19,21]).reshape(m,1)#相应y的值
alpha = 0.01#学习率
定义误差函数和梯度函数:
def error_function(theta,X,y): #误差函数
diff = np.dot(X,theta)-y
return (1./m)*np.dot(np.transpose(X),diff)
def gradient_function(theta,X,y):#梯度函数
diff = np.dot(X,theta) - y
return (1./m)*np.dot(np.transpose(X),diff)
迭代进行梯度下降,直到满足给定的阈值:
def gradient_descent(X,y,alpha):#梯度下降法
theta = np.array([1,1]).reshape(2,1)
gradient = gradient_function(theta,X,y)
while np.all(np.absolute(gradient) > 1e-5):
theta = theta - alpha * gradient
gradient = gradient_function(theta,X,y)
return theta
optimal_theta = gradient_descent(X,y,alpha)
print('optimal_theta:', optimal_theta)
print('error_function:',error_function(optimal_theta,X,y))
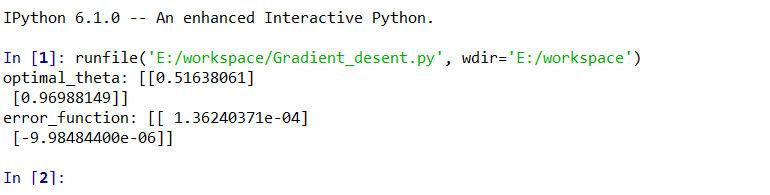
执行结果如下图:
如需完整代码请关注公众号,扫描下方二维码,回复:梯度下降
