BCOS源码学习(一)基础概念
本篇主要是扫盲,解决一些基础概念问题,对以太坊或者BCOS有了解的可以直接略过,BCOS是在以太坊的基础上修改而来。
一:哈希
哈希是BCOS中最重要的概念,通过给定的哈希算法h=h(x)可以将一个得到一个哈希值h,该输入是不可逆的,哈希在数学上是唯一的,因此它可以作为某个对象的全局唯一标识符,因此如果我们将一个哈希值和它对应的对象以[k,v]的形式保存在键值对中,可以很方便的索引到所需要的对象;哈希的另外一个特点是不可逆的,即不能通过h反推出它的对象x的值。
在BCOS中,哈希函数的实现在\libdevcore\SHA3.cpp中,我们不关心它的具体实现,它计算哈希的函数就是简单的sha3(),返回一个h256类型的值。
需要关注的是和哈希有关的几个数据类型,即以h开头的如h2048,、h1024等等,这是BCOS里专门为哈希散列值准备的容器,在\libdevcore\FixedHash中实现,FixedHash类重载了相应的操作符,我们可以像使用内置类型一样使用h+数字的这类型的结构;这些结构的意义也很容易了解,如h64就是指64位的哈希散列值,这里的数字代表二进制数目,而不是字节数,这点要注意;该类还提供了哈希类型(h+数字)的vector容器和set容器。
在之后我们会经常遇到Address这个数据类型,它代表BCOS当中的地址,只要时刻记得它就是一个h160就可以了。
二:RLP编码
RLP也是BCOS中极为基础和重要的机制,其定义可以参见以太坊的RLP
这种编码格式可以将任意嵌套的字节数组变成一个无嵌套的字节数组bytes,它可以线性的表示任意数据,另外该编码方式是可逆的。需要指出BCOS中,大多数情况下,数据都是编码成RLP之后才进行保存或者哈希的。
这里需要注意一个数据类型byte,在libdevcore\common.h中定义,它是一个uint8_t就是一个字节,该文件还定义了bytes,它实际上是一个vector。跑一下题,这个文件中还定义了许多名字,其中最为重要的是u+数字的类型如u128、u64等,这里的数字表示的也是位而不是字节,u代表的是无符号,以后我们会经常遇到这个类型。还有一个重要的数据类型vector_ref,定义在\libdevcore\vector_ref中,该类可以当成一个vector来用。
回到RLP,RLP的实现在\libdevcore\RLP,里面比较重要的俩个类是RLP类和RLPStream类,RLP类用来读取RLP格式的字节数组,RLPStream则提供了重要的函数append,该函数可以将给定的数据追加到字节流,该函数的重载版本几乎覆盖可能涉及的需要写入流中的数据类型,也就是说这俩个类,一个负责生产RLP字节流,一个负责读RLP字节格式;RLP类为自己提供了一个迭代器,我们可以像使用容器一样使用RLP。
RLP既然是双向的,那么RLP数据也一定可以还原成原始数据;该类重载了相应的操作符,最重要的是提供了允许数据的转换的方式,如explicit operator std::string() const { return toString(); },就允许将RLP格式的数据转换成字符串。图中所示的bytesConstRef实际上就是一个vector_ref
其实我们可以不必关注其实现细节,直接把它当做内置类型使用就可以了。

三:账户
BCOS中账户是极为关键的概念,账户分为俩类:一类是外部账户,外部账户代表着外部代理人的,如节点,机构等;一类是合约账户,合约账户就是指合约。实际上这俩类账户对于BCOS来说是讲的是一个东西,它们指的都是Account类,该类在\libethereum\Account中实现。可以将账户理解成一个状态的集合。
账户主要包含几个重要的成员:
u256 m_nonce;//随机数
u256 m_balance = 0;//余额
bytes m_codeCache;//合约代码的缓存
h256 m_storageRoot = EmptyTrie; //存储
std::unordered_map其中由于BCOS抛弃了代币的概念,所以余额的这个字段在这里无用;随机数是对账户状态的一个计数器,保证每一笔交易只能被处理一次,如果账户是一个外部账户,那么随机数代表的就是此账户地址发送的交易的序号,如果是一个合约账户,该数字代表的就是创建合约的序号;合约代码缓存是指如果该账户是合约账户则合约的代码就保存在这里,存储那一部分中m_storageRoot而是一个MPT树的树根,m_storageOverlay键值对才是真正保存账户状态的地方,需要注意的是,树根将被保存在一个状态数据库中,如果我们想要找到这个账户的状态,需要从状态数据库中读取树根,顺着MPT树来找。
在这里需要解释的多一点,当我们通过状态树,找到了某个账户的m_storageRoot。并不意味着我们就找到了该账户保存的数据了,m_storageRoot本身就是一颗树,想要都该账户里保存的数据,还要通过m_storageRoot这颗树再去寻找,至于状态树,那是下一章的内容了~
四:MPT
MPT(Merkle-PatriciaTrie)贯穿了整个BCOS。BCOS中的MPT树,我更愿意将其理解为一种[k,v]的实现方法,我们知道在BCOS中大多数的数据都是以键值对的方式存储的,比如说我们想要找到一个账户,那么我们需要知道该账户的地址,这就是键,与其对应的账户内容,就是值。在有很多个地址的情况下,怎么快速找到我们要的那个地址,进而得到它对应的值,最笨的方法是挨个遍历。BCOS采用的方法是用MPT,它既是默克尔树也是紧凑前缀树,在\libdevcore\Triexxx中实现了这个结构,当我们在介绍BCOS具体的区块数据组织形式时可能会与它打交道,这里先不管。
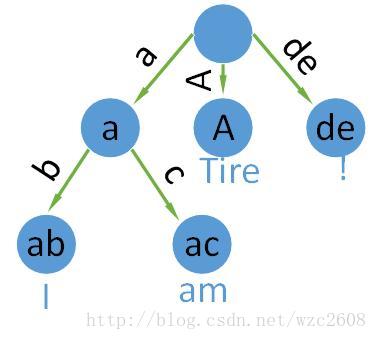
先来说什么是前缀树,如图:

这就是前缀树,每个节点所携带的数据由该节点的位置来体现,子节点共享父节点的前缀,在图中键标注在节点中,值标注在节点下,在计算机中以键值对的方式保存,如[ab,I]就表示键为ab而值为I,图中的要保存的数据是I am Tire !。
紧凑前缀树是对前缀树的改进,如果一个节点有唯一的子节点,那么就与父节点合并,上图基于紧凑前缀树的表示如图:
默克尔树,又被称为哈希树,它的特点是树中保存的键值对的键是数据块的哈希值,其中叶子节点直接对应要保存的数据块的哈希值,而非叶子节点则保存的是其子节点的串联字符串的哈希值,I am Tire !用默克尔树的表示如下图:
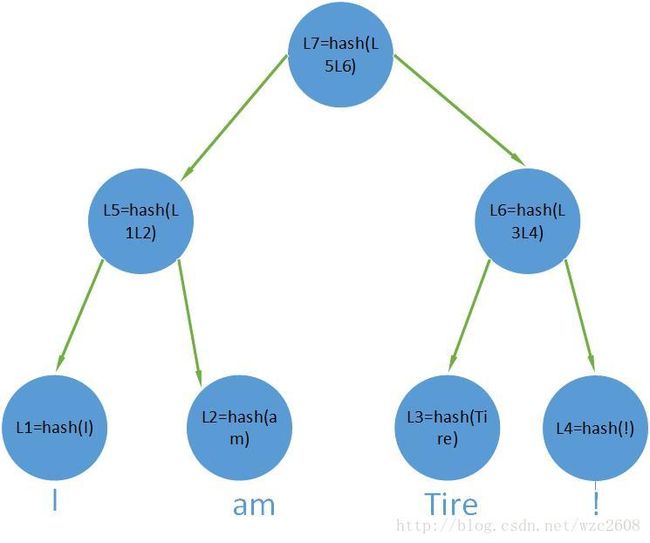
终于到了最关键的地方了,MPT就是默克尔树与紧凑前缀树的结合,我们结合代码来看:
MPT树中使用了一种十六进制前缀的编码方式来对key(键)进行编码,因为字母表是十六进制的所以,每一个节点可能有十六个子节点,该函数在数据库后端的定义位于\libdevcore\TrieDB,这里定义了一个GenericTrieDB的模板类,我们可以直接使用这个类,该类中定义了一个node结构体,这个结构体就代表了MPT中的节点:
std::string rlp;
std::string key; // as hexPrefixEncoding.
byte child; 其中rlp代表值,这个值是数据进行了rlp编码之后的一个值;key代表键,这个键也是通过一种编码方式得到的,即我们所说的十六进制前缀编码,这种编码方式比较简单,之所以要编码是因为统一key的表示方式,key的任意一个位置只有十六种可能;
MPT树中有四类节点:
空节点:就是一个空串
叶子节点:表示为一个[k,v]键值对,k是key的十六进制编码值,value是数据的rlp编码值。
扩展节点:表示为一个[k,v]键值对,value是其它节点的hash值,可以用来链接到其他节点。
分支节点:就是一个长度为17的list,包括十六进制编码后的十六个字符,如果有一个[k,v]在这里终止,最后一个字符代表这个v值。
可以看出,有俩种[k,v]类型的节点对应同一个结构体,所以引入一种终止标识符来表示到底是那类型的节点,如果终止标识符打开,则为叶子节点,如果关闭则为扩展节点;另外key的长度有可能是奇数也有可能是偶数,所以我们在每个节点前加入一个或俩个单独的4位二进制数(hex),具体意义如下表:
- 00: 扩展节点,key长度为偶数
- 1: 扩展节点,key长度为奇数
- 20: 叶子节点,key长度为偶数
- 3: 叶子节点,key长度为奇数
为了说明编码方式,我们解析一个函数:
std::string hexPrefixEncode(bytes const& _hexVector, bool _leaf, int _begin, int _end)
{
unsigned begin = _begin;
unsigned end = _end < 0 ? _hexVector.size() + 1 + _end : _end;
bool odd = ((end - begin) % 2) != 0;//判断key的长度是否为奇数
std::string ret(1, ((_leaf ? 2 : 0) | (odd ? 1 : 0)) * 16);
if (odd)
{
ret[0] |= _hexVector[begin];
++begin;
}
for (unsigned i = begin; i < end; i += 2)
ret += _hexVector[i] * 16 + _hexVector[i + 1];
return ret;
}首先传入的参数是一个bytes类型,这将是我们要编码的key,bool类型的leaf标示了该节点是否为叶子节点,begin和end代表key的开端和结束。我们假设要编码的key为0x12345
首先判断key是奇长度还是偶长度
接着std::string ret(1, ((_leaf ? 2 : 0) | (odd ? 1 : 0)) * 16);
假设该节点是叶子节点且key长度为奇数,那么ret被赋值为0011 0000,也就是0x30
if (odd)
{
ret[0] |= _hexVector[begin];
++begin;
}如果key的长度是奇数,那么ret[0] = 0x30 与key的第一个byte按位取或,在这里我们要搞清楚key的第一个byte到底是什么,由于key是以bytes的行式保存在内存中的,而一个byte又是八位的,所以奇数长度的key在bytes中保存的时候,最前的hex一定会补零,就是0x012345,这样,key就用三个byte保存下来,第一个byte与ret[0]按位或之后得到的ret[0]的值就是0x31,符合我们上面谈到的表格。
接下来的部分就是对key本身的编码了:
for (unsigned i = begin; i < end; i += 2)
ret += _hexVector[i] * 16 + _hexVector[i + 1];可以看出,编码过程只是简单将一个byte分在了俩个byte里而已,
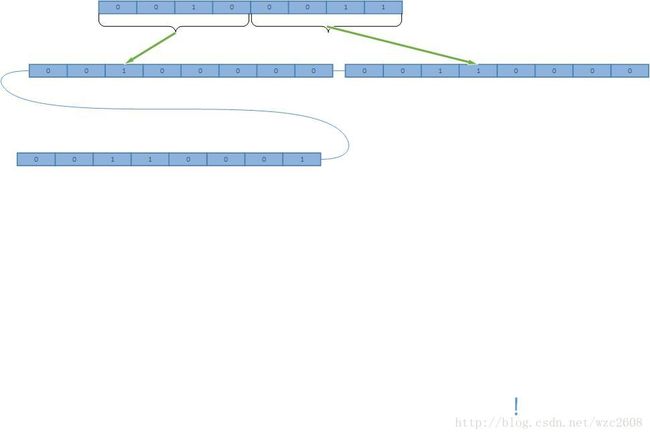
以上编码后的key就变成了0X3120304050
到目前为止,扩展节点和叶子节点就讲完了,这俩个节点都对应着node结构体,空节点就不说了,最后是分支节点。很不幸,分支节点对应的也是这个结构体,到目前为止,node结构体中列出的重要成员中,还有一个byte child 变量我们没有解释,这个变量只有有限的几种可能的取值,如下表:
- 255:代表入口
- 17: 代表出口
- 16:实际上的节点
- 0-15:实际上的孩子
这个理解还是比较困难的,花了好长时间,仍然以代码举例结合整个树的结构进行讲解:
比方说,系统要随着MPT树插入一个节点:
....
std::string rootValue = node(m_root);
bytes b = mergeAt(RLP(rootValue), m_root, NibbleSlice(_key), _value);
....这个名为m_root是我们要找的这棵树的根节点的哈希值,node(m_root)是从数据库中根据这个哈希值,找到这个哈希所对应的值,也就是说先通过哈希找到树,这个值是一个字符串。然后mergeAt函数才是真正的插入。
unsigned itemCount = _orig.itemCount();这句话,将刚刚得到的那个字符串转换成的RLP进行计数,它只有俩种种可能,要么是2要么是17,当然_orig也可能是一个空串,如果是一个空串的话,就新生成一棵树,不属于插入的范围了。(注意,这个时候_orig这个时候已经不是字符串了,它是一个RLP编码后的值,不能将这个计数函数理解为对字符串的字符数量计数)
那么为什么只能是二或者十七呢?
还记得,我们刚才的节点分类嘛?叶子节点和扩展节点对应一个[k,v]j键值对,扩展节点对应一个长度为17的list,这个判断实际上是对节点类型的判断。
在计数为2的情况下:
if (k == _k && isLeaf(_orig))
return place(_orig, _k, _v);首先来判断是不是叶子节点,这里的_k当然要插入的那个节点的编码后的key,而k则是根据_orig即上一个节点的key计算出来的,要判断的对象则是传入的上一个节点,如果发现这俩个k相等说明什么呢,说明树的分支已经走到了尽头。这是前缀树的特点,父节点的key总是子节点key的一部分,当深入到树的最深的一个节点时,我们会发现总有k == _k成立,这个时候就直接将值插入到这个节点就可以了。
注意,在这里我没有再使用根节点这一词而是使用了上一个节点,因为mergeAt()这个函数是递归调用的,最初传进来的值是根节点的值,但很快就不是了。
if (_k.contains(k) && !isLeaf(_orig))
{
if (!_inLine)
killNode(_orig, _origHash);
RLPStream s(2);
s.append(_orig[0]);
mergeAtAux(s, _orig[1], _k.mid(k.size()), _v);
return s.out();
}我们刚才提到了前缀编码,contains函数就是对前缀的一个判断,通过这个if我们可以得知,这种情况对应的是节点是扩展节点,没有找到我们应该插入的那个节点,所以调用了mergeAtAux函数
RLP r = _orig;
.......
bytes b = mergeAt(r, _k, _v, !isRemovable);
......r在这里实际上等于上一个节点的_orig[1],也就是上一个节点的值,这个值本身就是下一个节点的哈希,isRemovable则是对节点是否向下移动做一个判断,这个函数又调用了mergeAt,开始新一轮的判断。
当计数为17的情况下,当前节点一定是分支节点:
分支节点也分俩种情况:
if (_k.size() == 0)
return place(_orig, _k, _v);再也没有key值了,说明已到底,直接插入值。(注意,每经过一个节点key的长度都会减少,与父节点共享的那部分将减去)
byte n = _k[0];
RLPStream r(17);
for (byte i = 0; i < 17; ++i)
if (i == n)
mergeAtAux(r, _orig[i], _k.mid(1), _v);用要插入的key的第一个值与0-16挨个对比,由于key采用十六进制编码,所以一定有一个数与之对应,然后将key[0]去掉,顺着对应的那个数的下一级的哈希值,继续调用mergeAtAux。
那么node结构体是如何表示一个有17个成员的list的呢?
其实很简单,将十六个哈希和一个值一同以RLP的形式打包到rlp里就可以了,当一个迭代器访问到分支节点时,这时child被定义为255,然后如果rlp.itemCount == 17的话,将对key进行判断,如果到这个节点终止的话,将child设置为16,;否则将child设置为key所对应的第一个字符即0-15
if (k.size())
{
m_trail.back().setChild(k[0]);
k = k.mid(1);
}
else
m_trail.back().setChild(16);设置完成之后,迭代器就获得了一个路径,知道应该访问到分支节点为止,还是应该访问分支节点的哪个子节点。(GenericTrieDB类的迭代器的next函数)
到这机制就基本已经明了了,可以得出结论了:
1. 每一个节点无论其是什么类型的节点,都有其哈希值作为索引,这个哈希值不等于键值对里的key值,键值对里的key只做与最后的数据索引使用。
2. MPT将紧凑前缀树与默克尔树相结合,用默克尔树的方式搜索key,而key又是以紧凑前缀树的方式与数据相关联

本图来自网络MPT
到此为止,整个MPT树算是清楚了。
五:JSON
json是一种轻量级的数据交换格式,它的格式非常简单,网络上有很对关于json的的资料,这里不对json格式本身做介绍,主要是总结在BCOS中用到的俩个用于读写json的库即json-spirit和jsoncpp。
json-spirit
这个库定义了一个value类,这个类就是你要读的json,直接调用合适的get函数就可以读到json的值,json的值可能是数字,字符串,对象,数组等;必须根据具体的对象不同选择合适的get函数。如:
int i = value_1.get_value< int >();
一般来讲,读取到的往往是一个数组或着对象,数组和对象的数据是放在vector容器中的:
typedef std::vector< Pair > Object;
typedef std::vector< Value > Array;
其中pair的结构如下:
struct Pair
{
Pair( const std::string& name, const Value& value );
bool operator==( const Pair& lhs ) const;
std::string name_;
Value value_;
};可以看出在这俩种类型中又使用了value本身,那么它们也可以再包含数组或对象
3.怎么读json呢?
从流或字符串读,读到的东西当然是保存在value中
bool read( const std::string& s, Value& value );
bool read( std::istream& is, Value& value );使用迭代器
bool read( std::string::const_iterator& begin,
std::string::const_iterator end, Value& value );前面谈到如果json的值是数组或对象的话,它本身还可以再包含数组或对象,读函数一次只能读一层,如果要向里读的话必须自己设计逻辑。
4.怎么写json呢?
来自官方的小例子:
Object addr_obj;
addr_obj.push_back( Pair( "house_number", 42 ) );
addr_obj.push_back( Pair( "road", "East Street" ) );
addr_obj.push_back( Pair( "town", "Newtown" ) );
ofstream os( "address.txt" );
write( addr_obj, os, pretty_print );
os.close();object类型是指json object;pair类型上面说过了,最后生成的文件如下:
{
"house_number" : 42,
"road" : "East Street",
"town" : "Newtown"
}注意write函数,既可以将之写入到字符串也可以写入到文件:
std::string write( const Value& value, Output_options options = none, unsigned int precision_of_doubles = 0 );
void write( const Value& value, std::ostream& os, Output_options options = none, unsigned int precision_of_doubles = 0 );options是一个控制参数,具体看文档吧,不那么重要
5.出错怎么办?
如果出错或抛出一个异常,告诉你在哪行哪列json格式有问题:
struct Error_position
{
...
unsigned int line_;
unsigned int column_;
std::string reason_;
};BCOS使用的json-spirit版本是4.03
Jsoncpp
和json-spirit一样jsoncpp也提供几个类:
Json::Value 表示值的类型
Json::Reader 对流或字符串解析成value
Json::Writer 将value转化成流或字符串
1.怎么读?
Json::Reader reader;
Json::Value value;
reader.parase(str,value); 其中str是要读取的流或者字符串,读到的东西就保存在value里,以后想读取json中的某一部分怎么办呢?
比如json是这样的
{ "ret":200, //http response code
"code":0, //busi return code
"info":"bad parameters" //infomation of response
} 只要value[ret].asInt就可以读到它的值为200
value[info].asString就可以读到bad parameters
2.怎么写?
Json::Value Obj //先创建一个json的对象
Json::Value item //创建要插入对象的条目
item["ret"] = 200; //赋值
obj.append(item) //插入
// 转换为字符串(带格式)
std::string out = Obj .toStyledString();
// 输出无格式json字符串
Json::FastWriter writer;
std::string out2 = writer.write(Obj );