Spark深入解析(八):Spark整合YARN报错或无法查看日志
目录
- 如果整合Yarn报错或无法查看log需做如下操作
- 如果要整合YARN历史服务器和Spark历史服务器,则还需要如下操作
- 配置历史日志服务器
- 本地调试
如果整合Yarn报错或无法查看log需做如下操作
1.修改hadoop的yarn-site.xml
vim /export/servers/hadoop/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭YARN内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 如果开启如下配置则需要开启Spark历史服务器
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node01:19888/jobhistory/logs</value>
</property>
-->
2.分发并重启Hadoop服务
/export/servers/hadoop/sbin/stop-dfs.sh
/export/servers/hadoop/sbin/stop-yarn.sh
/export/servers/hadoop/sbin/start-dfs.sh
/export/servers/hadoop/sbin/start-yarn.sh
如果要整合YARN历史服务器和Spark历史服务器,则还需要如下操作
1.开启YARN历史服务器的配置并启动
/export/servers/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
2.先配置Spark日志服务器【文章末尾详细配置】
3.修改spark-defaults.conf
- vim /export/servers/spark/conf/spark-defaults.conf
spark.yarn.historyServer.address node01:4000
4.启动Spark HistoryServer服务
/export/servers/spark/sbin/start-history-server.sh
如果依赖的Jar包较多可以上传到HDFS并告诉YARN去取
在spark-default.conf中配置
spark.yarn.jars = hdfs://node01:8020/sparkjars/*
配置之后各个节点会去HDFS上下载并缓存
如果不配置Spark程序启动会把Spark_HOME打包分发到各个节点
配置历史日志服务器
默认情况下, Spark 程序运行完毕关闭窗口后, 就无法再查看运行记录的 Web UI (4040)了, 通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程
- 修改文件名
cd /export/servers/spark/conf
cp spark-defaults.conf.template spark-defaults.conf
- 修改配置
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/sparklog
- 注意:hdfs上的目录需要手动先创建
hadoop fs -mkdir -p /sparklog
- 修改spark-env.sh
- vim spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/sparklog"
- 同步文件
scp -r /export/servers/spark/conf/ @node02:/export/servers/spark/conf/
scp -r /export/servers/spark/conf/ @node03:/export/servers/spark/conf/
- 重启集群
/export/servers/spark/sbin/stop-all.sh
/export/servers/spark/sbin/start-all.sh
- 在master上启动日志服务器
/export/servers/spark/sbin/start-history-server.sh
- 在4000端口查看历史日志(如果加载不出来换浏览器试试)
http://node01:4000/
- 如果遇到Hadoop HDFS的写入权限问题
org.apache.hadoop.security.AccessControlException
解决方案:在hdfs-site.xml中添加如下配置,关闭权限验证
-------------------------------------------------
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
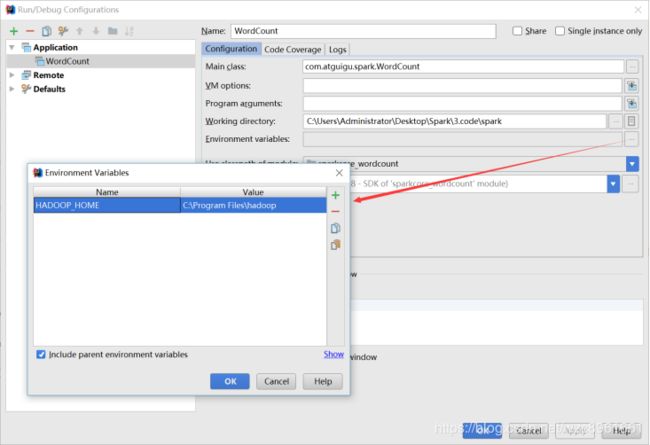
本地调试
本地Spark程序调试需要使用local提交模式,即将本机当做运行环境,Master和Worker都为本机。运行时直接加断点调试即可。如下:
创建SparkConf的时候设置额外属性,表明本地执行:
val conf = new SparkConf().setAppName("WC").setMaster("local[*]")
如果本机操作系统是windows,如果在程序中使用了hadoop相关的东西,比如写入文件到HDFS,则会遇到如下异常:

出现这个问题的原因,并不是程序的错误,而是用到了hadoop相关的服务,解决办法是将附加里面的hadoop-common-bin-2.7.3-x64.zip解压到任意目录。

在IDEA中配置Run Configuration,添加HADOOP_HOME变量