awk(三)杂乱
本文整体布局,按照sed和awk第二版的重点来,算是学习笔记吧!
小记:前两篇章是自己总结的,可以先了解下,本文不打算按部就班的讲,以前面两节为知识铺垫!
核心:掌握awk的规则
awk是一门解释性(程序设计)语言,本文从打印Hello Awk开始
(1)需求:打印 Hello Awk
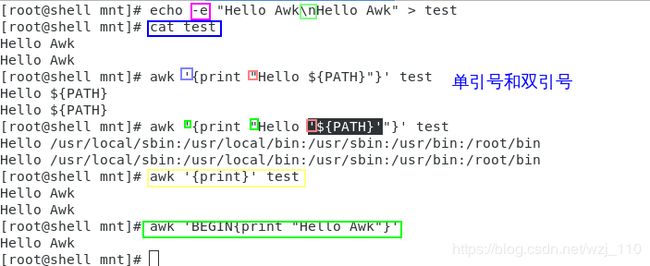
# 细细体会这种写法-->双引号包含单引号
awk 'BEGIN{print "'$var'"}'
test小知识点
#(1)echo -e激活转义字符,使用-e选项时,若出现某些特殊字符,则特别加以处理,而不会将它当成一般文字输出
#(2)当awk中print语句没有参数,只是简单输出每个输入行
#(3)运行原理:对于文本中的每一行(作为对象),用{pattern}进行匹配,如果匹配就对该行进行{action}
#(4)BEGIN:BEGIN模式用于指定在第一个输入行读入之前要执行动作,可以只有BEGIN模式,没有其它语句,此时awk将不处理任何输入文件
AWK与SHELL之间的变量传递方法
参考
(2)awk是输入驱动的
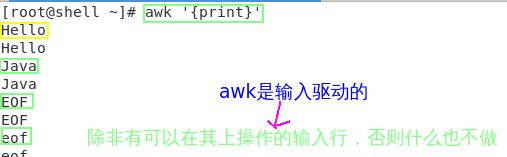
#(1):每次输入之后都需要按RETURN键
#(2):结束的时候可以按CTRL-D键盘(3)awk的设计模型
'BEGIN':在任何输入'被读取前'执行的例程-->常用来做'初始化'
'中间':读入每个输入行时('一次读入一行')执行第二个例程(主输入循环)
'END':在所有的'输入完成后'(全部文件内容)执行第三个例程-->常做'统计收尾'牢记:每个模式/操作过程位于主输入循环中个,且负责读取输入行;所编写的过程将应用于每个输入行,而且一次一行
(4)模式匹配初涉
pattern:顾名思义是符合标准,自然而然涉及到了正则表达式
原理:当awk读入一输入行时,它试图匹配脚本中的每个模式匹配规则,只有与一个特定模式匹配的输入行才能称之为操作对象
awk的正则表达式是属于:扩展的正则表达式
经典的模式
'空行': /^$/
'整数':/[0-9]+/
awk '/[0-9]+/{print}' file特殊:一行匹配多个规则

注意:输入4T被标识即是整数,又是字符串,即一行匹配多个规则,一般要防止一行与多个规则匹配!
说明:pattern1处理之后,pattern2日仍是原模式空间的改行匹配,而不是pattern1处理后的结果pattern2再处理

补充:awk脚本的注释也是#
(5)记录(Record)和字段(Field)
awk假设输入是有结构(可识别的结构化数据),这种结构不一定是一眼能看出来的!
记录:文件的每个输入行作为一条记录
字段:由分割符(默认是空格和制表符)分割的单词作为字段
分隔符(Separation):用来分割字段的字
(6)字段的引用(quote)和分离
awk允许'字段操作符$'来指定字段
'$0':表示整个输入记录
'$1':表示第一个字段,其他依次类推(7)逗号变空格

说明:print语句中分割每个参数的逗号使得输出(OFS原因)各值之间有一个空格!

脚本形式

备注:改变输出用OFS即可!
BEGIN指定'相关分割符'最好以""分割(8)数值计算和变量初次涉及
echo a b c | awk 'BEGIN{one=1;two=2}{print $(one+two)}'
# $n,n不一定要用整数,也可以用变量值代替
# 说明1-->第一部分:echo a b c 表示awk读入一行,可以用''引起来
# 说明2-->第二部分:BEGIN做文件读入前的初始化,print $(one+two)打印print $3即该记录的第三个字段(9)~ 操作符
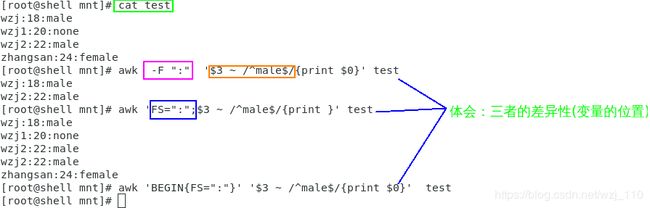
说明:(~)操作符测试一个字段的正则表达式
补充
awk -v FS=':' '$3 ~ /^male$/{print $0}' test
wzj:18:male
wzj2:22:male后记:关于写不写博客,纠结了很长时间,一方面太耗费精力,另一方面时间也不太允许,所幸经过挣扎,重新回归,希望大家多多批评,多多提问题,一块进步!