kylin 安装配置实验
一、实验环境
3台CentOS release 6.4虚拟机,IP地址为
192.168.56.101 master
192.168.56.102 slave1
192.168.56.103 slave2
hadoop 2.7.2
hbase 1.1.4
hive 2.0.0
zookeeper 3.4.8
kylin 1.5.1(一定要apache-kylin-1.5.1-HBase1.1.3-bin.tar.gz包)
master作为hadoop的NameNode、SecondaryNameNode、ResourceManager,hbase的HMaster
slave1、slave2作为hadoop的DataNode、NodeManager,hbase的HRegionServer
同时master、slave1、slave2作为三台zookeeper服务器
参考:
http://blog.csdn.net/wzy0623/article/details/50681554
三、安装配置基于独立Zookeeper集群的Hbase
参考:
http://blog.csdn.net/wzy0623/article/details/51241641
http://blog.csdn.net/wzy0623/article/details/51276501
四、安装配置hive
参考:
http://blog.csdn.net/wzy0623/article/details/50685966
五、添加hive_dependency环境变量
六、把hive安装目录拷贝到Hadoop集群的其他节点
七、在每个节点中配置如下环境变量:
八、安装配置kylin
# 在master上执行以下命令
需要对此脚本做两点修改:
1. export KYLIN_HOME=/home/grid/kylin # 改成绝对路径
2. export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX # 在路径中添加$hive_dependency
九、测试
1. 分别在三台机器上启动zookeeper
2. 在master启动其它kylin依赖的服务
3. 在master启动kylin
4. 测试kylin自带的例子
(1)运行${KYLIN_HOME}/bin/sample.sh,并重启kylin服务器
${KYLIN_HOME}/bin/sample.sh
${KYLIN_HOME}/bin/kylin.sh stop
${KYLIN_HOME}/bin/kylin.sh start
(2)使用ADMIN/KYLIN作为用户名/密码登录以下URL,在左上角的project下拉列表中选择'learn_kylin'项目
http://192.168.56.101:7070/kylin
(3)选中'kylin_sales_cube'示例立方体,点击'Actions'->'Build',选择一个截止日期,本试验中选择的是'2012-04-01'
(4)在'Monitor'标签中通过刷新页面检查进度条,直到100%
(5)在'Insight'标签中执行下面的SQL查询:
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
(6)在hive中执行同一个SQL查询,验证kylin的查询结果
Build成功的监控标签如图2所示
查询执行和结果分别如图3、图4所示
Build成功后,hive中建立了3个表,如图5所示
Build成功后,hbase中建立了2个表,如图6所示
注意:
1. kylin、hadoop、hbase、hive的版本一定要匹配。
2. 需要把hive拷贝到集群中的每个节点中。
3. 需要修改kylin.sh脚本。
4. 需要在每个节点中配置如下环境变量:
HADOOP_HOME
HBASE_HOME
HADOOP_HDFS_HOME
HIVE_HOME
HADOOP_COMMON_HOME
JAVA_HOME
HADOOP_YARN_HOME
ZOOKEEPER_HOME
KYLIN_HOME
HADOOP_MAPRED_HOME
参考:
http://kylin.apache.org/docs15/tutorial/kylin_sample.html
http://www.myexception.cn/open-source/1940509.html
3台CentOS release 6.4虚拟机,IP地址为
192.168.56.101 master
192.168.56.102 slave1
192.168.56.103 slave2
hadoop 2.7.2
hbase 1.1.4
hive 2.0.0
zookeeper 3.4.8
kylin 1.5.1(一定要apache-kylin-1.5.1-HBase1.1.3-bin.tar.gz包)
master作为hadoop的NameNode、SecondaryNameNode、ResourceManager,hbase的HMaster
slave1、slave2作为hadoop的DataNode、NodeManager,hbase的HRegionServer
同时master、slave1、slave2作为三台zookeeper服务器
需要事先重新编译hadoop源码,使得native库支持snappy
编译hadoop源码,参考:
http://blog.csdn.net/wzy0623/article/details/51263041
参考:
http://blog.csdn.net/wzy0623/article/details/50681554
三、安装配置基于独立Zookeeper集群的Hbase
参考:
http://blog.csdn.net/wzy0623/article/details/51241641
http://blog.csdn.net/wzy0623/article/details/51276501
四、安装配置hive
参考:
http://blog.csdn.net/wzy0623/article/details/50685966
五、添加hive_dependency环境变量
export hive_dependency=/home/grid/hive/conf:/home/grid/hive/lib/*:/home/grid/hive/hcatalog/share/hcatalog/hive-hcatalog-core-2.0.0.jar六、把hive安装目录拷贝到Hadoop集群的其他节点
scp -r hive slave1:/home/grid/
scp -r hive slave2:/home/grid/七、在每个节点中配置如下环境变量:
JAVA_HOME
HADOOP_HOME
HBASE_HOME
HADOOP_HDFS_HOME
HIVE_HOME
HADOOP_COMMON_HOME
JAVA_HOME
HADOOP_YARN_HOME
ZOOKEEPER_HOME
KYLIN_HOME
HADOOP_MAPRED_HOME
hive_dependency八、安装配置kylin
# 在master上执行以下命令
cd /home/grid/
tar -zxvf apache-kylin-1.5.1-HBase1.1.3-bin.tar.gz
ln -s apache-kylin-1.5.1-bin kylin需要对此脚本做两点修改:
1. export KYLIN_HOME=/home/grid/kylin # 改成绝对路径
2. export HBASE_CLASSPATH_PREFIX=${tomcat_root}/bin/bootstrap.jar:${tomcat_root}/bin/tomcat-juli.jar:${tomcat_root}/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX # 在路径中添加$hive_dependency
九、测试
1. 分别在三台机器上启动zookeeper
/home/grid/zookeeper/bin/zkServer.sh start2. 在master启动其它kylin依赖的服务
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
~/mysql/bin/mysqld &
nohup $HIVE_HOME/bin/hive --service metastore > /tmp/grid/hive_metastore.log 2>&1 &
/home/grid/hbase/bin/start-hbase.sh3. 在master启动kylin
cd /home/grid/kylin/bin
./kylin.sh start4. 测试kylin自带的例子
(1)运行${KYLIN_HOME}/bin/sample.sh,并重启kylin服务器
${KYLIN_HOME}/bin/sample.sh
${KYLIN_HOME}/bin/kylin.sh stop
${KYLIN_HOME}/bin/kylin.sh start
(2)使用ADMIN/KYLIN作为用户名/密码登录以下URL,在左上角的project下拉列表中选择'learn_kylin'项目
http://192.168.56.101:7070/kylin
(3)选中'kylin_sales_cube'示例立方体,点击'Actions'->'Build',选择一个截止日期,本试验中选择的是'2012-04-01'
(4)在'Monitor'标签中通过刷新页面检查进度条,直到100%
(5)在'Insight'标签中执行下面的SQL查询:
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
(6)在hive中执行同一个SQL查询,验证kylin的查询结果
Build成功的模型标签如图1所示

图1
Build成功的监控标签如图2所示

图2
查询执行和结果分别如图3、图4所示

图3
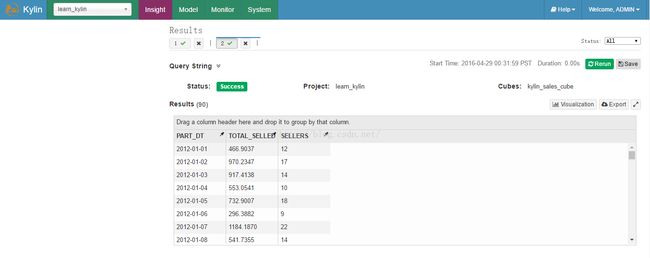
图4
Build成功后,hive中建立了3个表,如图5所示
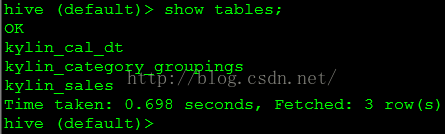
图5
Build成功后,hbase中建立了2个表,如图6所示
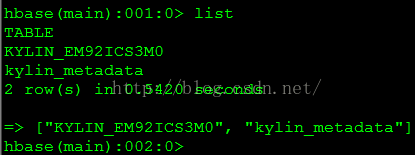
图6
注意:
1. kylin、hadoop、hbase、hive的版本一定要匹配。
2. 需要把hive拷贝到集群中的每个节点中。
3. 需要修改kylin.sh脚本。
4. 需要在每个节点中配置如下环境变量:
HADOOP_HOME
HBASE_HOME
HADOOP_HDFS_HOME
HIVE_HOME
HADOOP_COMMON_HOME
JAVA_HOME
HADOOP_YARN_HOME
ZOOKEEPER_HOME
KYLIN_HOME
HADOOP_MAPRED_HOME
参考:
http://kylin.apache.org/docs15/tutorial/kylin_sample.html
http://www.myexception.cn/open-source/1940509.html