神经翻译笔记4扩展c. 2017-2019年间RNN和RNN语言模型的新进展
文章目录
- 神经翻译笔记4扩展c. 2017-2019年间RNN和RNN语言模型的新进展
- QuasiRNN
- FS-RNN
- Skip RNN
- 高秩RNN语言模型MoS
- IndRNN
- ON-LSTM
- Mogrifier LSTM
- 参考文献
神经翻译笔记4扩展c. 2017-2019年间RNN和RNN语言模型的新进展
尽管在本文写作时(2020年4月),基于Transformer结构的预训练语言模型已经大杀四方,BERT都已经成为明日黄花,在其基础上衍生的各种变体,例如RoBERTa、ALBERT、BART等等长江后浪推前浪,使得基于RNN的语言模型更不再是语言模型领域的焦点。但是为了系列文章结构的完备性,本文以及下一篇文章仍然会介绍一些这方面的“新”工作和一些里程碑式的工作。本文将介绍2017至2019三年间,RNN体系结构及基于RNN的语言模型的一些新进展。
QuasiRNN
本文实际上发表于2016年,而且采用了CNN的思想,因此先不在本文介绍。在这里先立个flag,等本系列笔记进行到6时,再概述此工作。采取同样思想的亦有SRU,准备也到时再介绍
FS-RNN
FS-RNN (Fast-Slow RNN) [Mujika2017] 受两类RNN的启发
- 多(时间)尺度RNN:对于堆叠RNN中更高层的若干层,其被更新的次数越少(更不频繁),以此来获得信息的分层表示。由于高层参数更新变慢,因此计算起来更高效,梯度更新路径越短,越能捕捉长距离依赖
- 深度变换RNN (deep transition RNN),其相邻两个隐藏状态之间引入了新的顺序连接层,以此来增加两个时间步之间变换函数的深度,进而学习更复杂的非线性变换
FS-RNN将两类网络结合起来,最简单的方式是
- 对底层RNN,引入深度变换(若干顺序连接层),称为“快层”
- 对高层RNN,降低更新频率,称为“慢层”
更形式化地讲,底层在两个时间步之间插入 k k k个顺序连接的RNN神经元 F 1 , … , F k F_1, \ldots, F_k F1,…,Fk,高层只使用一个神经元 S S S。 F 1 F_1 F1接收第 t t t时间步的输入 x t x_t xt,将输出传给 S S S作为输入, S S S处理后将状态传给 F 2 F_2 F2,然后从 F 2 F_2 F2开始输出逐级传播下去,前一个 F i − 1 F_{i-1} Fi−1的输出作为后一个 F i F_i Fi的输入,到 F k F_k Fk输出概率分布 y t y_t yt,如下图所示
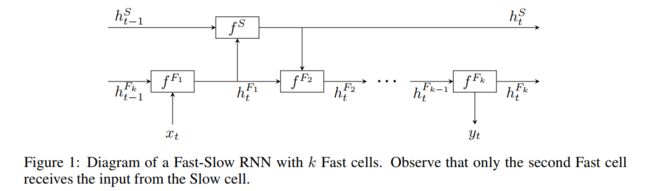
记每个RNN神经元 Q Q Q为一个可微函数 f Q ( h , x ) f^Q(h,x) fQ(h,x),其将上一步的隐藏状态 h h h和输入 x x x一起映射为一个新的隐藏状态,则
h t F 1 = f F 1 ( h t − 1 F k , x t ) h t S = f S ( h t − 1 S , h t F 1 ) h t F 2 = f F 2 ( h t F 1 , h t S ) h t F i = f F i ( h t F i − 1 ) f o r 3 ≤ i ≤ k y t = s o f t m a x ( W h t F k + b ) \begin{aligned} h_t^{F_1} &= f^{F_1}(h_{t-1}^{F_k}, x_t) \\ h_t^{S} &= f^{S}(h_{t-1}^{S}, h_t^{F_1}) \\ h_t^{F_2} &= f^{F_2}(h_{t}^{F_1}, h_t^S) \\ h_t^{F_i} &= f^{F_i}\left(h_t^{F_{i-1}}\right)\ \ {\rm for\ }3\le i \le k \\ y_t &= {\rm softmax}\left(Wh_t^{F_k}+b\right) \end{aligned} htF1htShtF2htFiyt=fF1(ht−1Fk,xt)=fS(ht−1S,htF1)=fF2(htF1,htS)=fFi(htFi−1) for 3≤i≤k=softmax(WhtFk+b)
文章使用LSTM作为基础的RNN神经元,在Penn Treebank和enwik8上均取得了不错的效果
Skip RNN
传统RNN和普通的带门控的RNN(例如LSTM)对长句表现都不好。[Campos2017]的思路是让网络学习输入序列中哪些样本可以解决目标问题,因此可以在训练时跳过一些状态的更新,可以减少对序列的操作
记RNN接受的输入序列 x = ( x 1 , … , x T ) \boldsymbol{x} = (x_1, \ldots, x_T) x=(x1,…,xT),每步向下传递的状态为 s = ( s 1 , … , s T ) \boldsymbol{s}=(s_1, \ldots, s_T) s=(s1,…,sT),有
s t = R N N ( s t − 1 , x t ) s_t = {\rm RNN}(s_{t-1}, x_t) st=RNN(st−1,xt)
本文引入了一个额外的状态更新门 u t ∈ { 0 , 1 } u_t \in \{0,1\} ut∈{0,1},该门是完全二值的,只输出0或1,不像LSTM或GRU那样输出一个0到1的浮点数。当 u t = 1 u_t = 1 ut=1时,该时刻状态更新;当 u t = 0 u_t = 0 ut=0时,该时刻从前一时刻直接拷贝状态。 u t u_t ut的结果由上一步产生的概率 u ~ t ∈ [ 0 , 1 ] \tilde{u}_{t} \in [0,1] u~t∈[0,1]决定,具体地
u t = f b i n a r i z e ( u ~ t ) s t = u t ⋅ R N N ( s t − 1 , x t ) + ( 1 − u t ) ⋅ s t − 1 Δ u ~ t = σ ( W p s t + b p ) u ~ t + 1 = u t ⋅ Δ u ~ t + ( 1 − u t ) ⋅ ( u ~ t + min ( Δ u ~ t , 1 − u ~ t ) ) \begin{aligned} u_t &= f_{\rm binarize}(\tilde{u}_t) \\ s_t &= u_t \cdot {\rm RNN}(s_{t-1}, x_t) + (1-u_t)\cdot s_{t-1} \\ \Delta \tilde{u}_t &= \sigma(\boldsymbol{W}_ps_t + \boldsymbol{b}_p) \\ \tilde{u}_{t+1} &= u_t \cdot \Delta\tilde{u}_t + (1-u_t)\cdot (\tilde{u}_t + \min(\Delta\tilde{u}_t, 1-\tilde{u}_t)) \end{aligned} utstΔu~tu~t+1=fbinarize(u~t)=ut⋅RNN(st−1,xt)+(1−ut)⋅st−1=σ(Wpst+bp)=ut⋅Δu~t+(1−ut)⋅(u~t+min(Δu~t,1−u~t))
其中 W p \boldsymbol{W}_p Wp是权重, b p \boldsymbol{b}_p bp是偏置项, σ \sigma σ是sigmoid函数, f b i n a r i z e : [ 0 , 1 ] → { 0 , 1 } f_{\rm binarize}:[0,1] \rightarrow \{0,1\} fbinarize:[0,1]→{0,1}是将输入映射为0或1的函数,本文使用了四舍五入法(round),也可以从伯努利分布随机采样。模型隐含了一个信息:如果连续跳过的状态越多,那么下一个状态就更可能被更新:
- 如果当前状态被跳过,那么下一个时间步的“预激活值” u ~ t + 1 \tilde{u}_{t+1} u~t+1会增加 Δ u ~ t \Delta \tilde{u}_t Δu~t
- 如果当前状态被更新,那么累积的“预激活值”清零,重置为 Δ u ~ t \Delta \tilde{u}_t Δu~t
如果在某些场合下,可以为减少计算量额外牺牲精度,即为了让模型更倾向于少更新状态,则可以引入一个额外的损失项
L b u d g e t = λ ⋅ ∑ t = 1 T u t L_{\rm budget} = \lambda \cdot \sum_{t=1}^T u_t Lbudget=λ⋅t=1∑Tut
有趣的是,本工作的三项实验均未在NLP任务上进行
高秩RNN语言模型MoS
[YangZhilin2017]将语言模型看作是一个矩阵分解问题。文章将自然语言 L \mathcal{L} L定义为一个有限集合,集合中每个元素是一个有序对,由上下文和给定上下文后下一个标识符的分布两者组成,即
L = { ( c 1 , P ∗ ( X ∣ c 1 ) ) , … , ( c N , P ∗ ( X ∣ c N ) ) } \mathcal{L} = \{(c_1, P^\ast(X|c_1)), \ldots, (c_N, P^\ast(X|c_N))\} L={(c1,P∗(X∣c1)),…,(cN,P∗(X∣cN))}
其中 N N N是所有可能的上下文的数目。令 L \mathcal{L} L中所有可能的标识符集合为 { x 1 , x 2 , … , x M } \{x_1, x_2, \ldots, x_M\} {x1,x2,…,xM},大小为 M M M,则语言模型的目标是学习一个参数为 θ \theta θ的模型分布 P θ ( X ∣ C ) P_\theta(X|C) Pθ(X∣C)以逼近真实分布 P ∗ ( X ∣ C ) P^\ast(X|C) P∗(X∣C)。本文主要研究该模型的表示能力,即对给定的 L \mathcal{L} L是否存在参数 θ \theta θ,使得对 L \mathcal{L} L中的所有 c c c有 P θ ( X ∣ c ) = P ∗ ( X ∣ c ) P_\theta(X|c) = P^\ast(X|c) Pθ(X∣c)=P∗(X∣c)
对于RNN语言模型, P θ ( x ∣ c ) P_\theta(x|c) Pθ(x∣c)由RNN的上下文向量(隐藏状态) h c \boldsymbol{h}_c hc和词向量 w x \boldsymbol{w}_x wx决定,即
P θ ( x ∣ c ) = exp { h c T w x } ∑ x ′ exp { h c T w x ′ } P_\theta (x|c) = \frac{\exp\{\boldsymbol{h}_c^\mathsf{T}\boldsymbol{w}_{x}\}}{\sum_{x'}\exp\{\boldsymbol{h}_c^\mathsf{T}\boldsymbol{w}_{x'}\}} Pθ(x∣c)=∑x′exp{hcTwx′}exp{hcTwx}
称 h c T w x \boldsymbol{h}_c^\mathsf{T}\boldsymbol{w}_{x} hcTwx为分对数logit。定义如下三个矩阵
H θ = [ h c 1 T h c 2 T ⋯ h c N T ] ∈ R N × d ; W θ = [ w x 1 T w x 2 T ⋯ w x M T ] ∈ R M × d A = [ log P ∗ ( x 1 ∣ c 1 ) log P ∗ ( x 2 ∣ c 1 ) ⋯ log P ∗ ( x M ∣ c 1 ) log P ∗ ( x 1 ∣ c 2 ) log P ∗ ( x 2 ∣ c 2 ) ⋯ log P ∗ ( x M ∣ c 2 ) ⋮ ⋮ ⋱ ⋮ log P ∗ ( x 1 ∣ c N ) log P ∗ ( x 2 ∣ c N ) ⋯ log P ∗ ( x M ∣ c N ) ] ∈ R N × M \boldsymbol{H}_\theta = \left[\begin{matrix}\boldsymbol{h}_{c_1}^\mathsf{T} \\ \boldsymbol{h}_{c_2}^\mathsf{T} \\ \cdots \\ \boldsymbol{h}_{c_N}^\mathsf{T} \end{matrix}\right] \in \mathbb{R}^{N \times d}; \boldsymbol{W}_\theta = \left[\begin{matrix}\boldsymbol{w}_{x_1}^\mathsf{T} \\ \boldsymbol{w}_{x_2}^\mathsf{T} \\ \cdots \\ \boldsymbol{w}_{x_M}^\mathsf{T} \end{matrix}\right] \in \mathbb{R}^{M\times d} \\ \\ \boldsymbol{A}=\left[\begin{matrix}\log P^\ast (x_1|c_1) & \log P^\ast (x_2|c_1) & \cdots & \log P^\ast (x_M|c_1) \\ \log P^\ast (x_1|c_2) & \log P^\ast (x_2|c_2) & \cdots & \log P^\ast (x_M|c_2) \\ \vdots & \vdots & \ddots & \vdots \\ \log P^\ast (x_1|c_N) & \log P^\ast (x_2|c_N) & \cdots & \log P^\ast (x_M|c_N)\end{matrix}\right] \in \mathbb{R}^{N \times M} Hθ=⎣⎢⎢⎡hc1Thc2T⋯hcNT⎦⎥⎥⎤∈RN×d;Wθ=⎣⎢⎢⎡wx1Twx2T⋯wxMT⎦⎥⎥⎤∈RM×dA=⎣⎢⎢⎢⎡logP∗(x1∣c1)logP∗(x1∣c2)⋮logP∗(x1∣cN)logP∗(x2∣c1)logP∗(x2∣c2)⋮logP∗(x2∣cN)⋯⋯⋱⋯logP∗(xM∣c1)logP∗(xM∣c2)⋮logP∗(xM∣cN)⎦⎥⎥⎥⎤∈RN×M
其中 H θ \boldsymbol{H}_\theta Hθ、 W θ \boldsymbol{W}_\theta Wθ和 A \boldsymbol{A} A的每一行分别是上下文向量、词向量和真实分布中概率的对数值。对不同的参数 θ \theta θ, H θ \boldsymbol{H}_\theta Hθ和 W θ \boldsymbol{W}_\theta Wθ也会不同
定义矩阵集合 F ( A ) F(\boldsymbol{A}) F(A)为 A \boldsymbol{A} A每行各自加一增量得到的矩阵的集合。形式化表示为
F ( A ) = { A + Λ J N , M ∣ Λ ∈ R N × N } F(\boldsymbol{A}) = \{\boldsymbol{A} + \boldsymbol{\Lambda J}_{N,M} | \boldsymbol{\Lambda} \in \mathbb{R}^{N \times N}\} F(A)={A+ΛJN,M∣Λ∈RN×N}
其中 Λ \boldsymbol{\Lambda} Λ为对角矩阵。 F ( A ) F(\boldsymbol{A}) F(A)就是让 A \boldsymbol{A} A第 i i i行每个元素都增加一个增量 Λ i i \boldsymbol{\Lambda}_{ii} Λii
文章根据 F ( A ) F(\boldsymbol{A}) F(A)的两个性质和一条引理(具体内容略)将问题转化为:是否存在一个参数 θ \theta θ和矩阵 A ′ ∈ F ( A ) \boldsymbol{A}' \in F(\boldsymbol{A}) A′∈F(A),使得
H θ W θ T = A ′ \boldsymbol{H}_\theta \boldsymbol{W}_\theta^\mathsf{T} = \boldsymbol{A}' HθWθT=A′
这实际上是一个矩阵分解问题。如果存在一个合法的矩阵分解,则 H θ W θ T \boldsymbol{H}_\theta \boldsymbol{W}_\theta^\mathsf{T} HθWθT的秩不应该比 A ′ \boldsymbol{A}' A′的秩小,而 H θ W θ T \boldsymbol{H}_\theta \boldsymbol{W}_\theta^\mathsf{T} HθWθT秩的上界为 d d d。文章再次推导并形式化提出了“Softmax瓶颈”问题,即
如果 d < r a n k ( A ′ ) − 1 d < {\rm rank}(\boldsymbol{A}' )- 1 d<rank(A′)−1,则对任意函数族 U \mathcal{U} U和任意模型参数 θ \theta θ, L \mathcal{L} L中都有一个上下文 c c c使得 P θ ( X ∣ c ) ≠ P ∗ ( X ∣ c ) P_\theta(X|c) \not= P^\ast(X|c) Pθ(X∣c)=P∗(X∣c)
更白话的解释是,当 d d d太小时,softmax没有足够能力表示真实的数据分布。然而,根据一些直觉和经验观察,对任何自然语言 L \mathcal{L} L来说, A \boldsymbol{A} A可能都是高秩的,即在目前的实践中都有 d ≪ r a n k ( A ) d \ll {\rm rank}(\boldsymbol{A}) d≪rank(A)。一种对策是使用非参数模型,例如Ngram语言模型,不过这种模型表示能力太高会损失泛化能力
本文提出的方法是在模型里计算 K K K个softmax分布,然后将他们的结果加权输出,即
P θ ( x ∣ c ) = ∑ k = 1 K π c , k exp { h c , k T w x } ∑ x ′ exp { h c , k T w x ′ } π c t , k = exp { w π , k T g t } ∑ k ′ = 1 K exp { w π , k ′ T g t } h c t , k = tanh ( W h , k g t ) \begin{aligned} P_\theta (x|c) &= \sum_{k=1}^K \pi_{c,k} \frac{\exp\{\boldsymbol{h}_{c,k}^\mathsf{T}\boldsymbol{w}_{x}\}}{\sum_{x'}\exp\{\boldsymbol{h}_{c,k}^\mathsf{T}\boldsymbol{w}_{x'}\}} \\ \pi_{c_t, k} &= \frac{\exp\{\boldsymbol{w}_{\pi,k}^\mathsf{T}\boldsymbol{g}_{t}\}}{\sum_{k'=1}^K\exp\{\boldsymbol{w}_{\pi,k'}^\mathsf{T}\boldsymbol{g}_{t}\}} \\ \boldsymbol{h}_{c_t, k} &= \tanh(\boldsymbol{W}_{h,k}\boldsymbol{g}_t) \end{aligned} Pθ(x∣c)πct,khct,k=k=1∑Kπc,k∑x′exp{hc,kTwx′}exp{hc,kTwx}=∑k′=1Kexp{wπ,k′Tgt}exp{wπ,kTgt}=tanh(Wh,kgt)
其中 g t \boldsymbol{g}_t gt是由加在输入 X \boldsymbol{X} X上的RNN得到的隐藏状态(感觉相当于本节最开始引入的 h \boldsymbol{h} h), w π , k \boldsymbol{w}_{\pi,k} wπ,k和 W h , k \boldsymbol{W}_{h,k} Wh,k都是模型参数。本文称这种方法为“softmax混合模型”(Mixture of Softmaxes,缩写MoS)
本工作的直接后继是Mixtape [YangZhilin2019],不过模型更加复杂,这里就不介绍了
IndRNN
由于RNN中各时间步内部共享一个权重矩阵 U \boldsymbol{U} U(正文中的 W \boldsymbol{W} W),因此会很容易带来梯度消失或梯度爆炸问题,而且很难解释和理解单个神经元所扮演的角色。此外,每个时间步展开时所进行的矩阵乘法也不好并行化,使得网络对长序列的处理非常耗时。[LiShuai2018] 提出将这个 U \boldsymbol{U} U替换成一个 d d d维向量 u \boldsymbol{u} u( d d d为每层神经元的个数),即第 t t t时刻隐藏状态为
h ( t ) = a c t i v a t i o n ( W x ( t ) + u ⊙ h ( t − 1 ) + b ) \boldsymbol{h}^{(t)} = {\rm activation}\left(\boldsymbol{Wx}^{(t)}+\boldsymbol{u}\odot \boldsymbol{h}^{(t-1)} + \boldsymbol{b}\right) h(t)=activation(Wx(t)+u⊙h(t−1)+b)
这使得每一层的各个神经元都相互独立,都只从前一个时刻自身的隐藏状态接收信息,不被其他神经元影响,如下图所示。因此网络被称为“独立循环神经网络”(Independent RNN, IndRNN)。IndRNN常用ReLU作为激活函数

对第 n n n个神经元,隐藏状态为
h n ( t ) = a c t i v a t i o n ( w n x ( t ) + u n h n ( t − 1 ) + b n ) h_n^{(t)} = {\rm activation}\left(\boldsymbol{w}_n\boldsymbol{x}^{(t)} + u_nh_n^{(t-1)} + b_n\right) hn(t)=activation(wnx(t)+unhn(t−1)+bn)
假设对时刻 T T T的目标函数是 J n J_n Jn,则其反向传播到时刻 t t t的梯度为
∂ J n ∂ h n ( t ) = ∂ J n ∂ h n ( T ) ∂ h n ( T ) ∂ h n ( t ) = ∂ J n ∂ h n ( T ) ∏ k = t T − 1 ∂ h n ( k + 1 ) ∂ h n ( k ) = ∂ J n ∂ h n ( T ) ∏ k = t T − 1 a c t i v a t i o n n ′ ( k + 1 ) u n = ∂ J n ∂ h n ( T ) u n T − t ∏ k = t T − 1 a c t i v a t i o n n ′ ( k + 1 ) \begin{aligned} \frac{\partial J_n}{\partial h_n^{(t)}} &= \frac{\partial J_n}{\partial h_n^{(T)}} \frac{\partial h^{(T)}_n}{\partial h_n^{(t)}} = \frac{\partial J_n}{\partial h_n^{(T)}} \prod_{k=t}^{T-1} \frac{\partial h^{(k+1)}_n}{\partial h_n^{(k)}} \\ &= \frac{\partial J_n}{\partial h_n^{(T)}} \prod_{k=t}^{T-1} {\rm activation}_n^{'(k+1)} u_n = \frac{\partial J_n}{\partial h_n^{(T)}}u_n^{T-t} \prod_{k=t}^{T-1} {\rm activation}_n^{'(k+1)} \end{aligned} ∂hn(t)∂Jn=∂hn(T)∂Jn∂hn(t)∂hn(T)=∂hn(T)∂Jnk=t∏T−1∂hn(k)∂hn(k+1)=∂hn(T)∂Jnk=t∏T−1activationn′(k+1)un=∂hn(T)∂JnunT−tk=t∏T−1activationn′(k+1)
这里只依赖两项:标量 u n u_n un的指数项(正则化更容易)和激活函数的逐元素导数(一般都有界)。由于标量 u n u_n un在训练过程中只根据学习率被微调,而不是像矩阵一样其乘积由特征值决定(而特征值很容易剧烈变化),因此IndRNN的训练过程更鲁棒。为了避免梯度消失,只需要让 ∣ u n ∣ > 0 |u_n| > 0 ∣un∣>0即可。而且由于各个 u n u_n un相对独立,因此很难出现所有 u n u_n un都为0的情况,不用刻意限制,只需要让 ∣ u n ∣ ≤ γ ( T − t ) |u_n| \le \sqrt[(T-t)]{\gamma} ∣un∣≤(T−t)γ来防止梯度爆炸即可( γ \gamma γ是不让爆炸发生的最大梯度)。如果只是要做文本分类,只需要长期记忆,则需要提高 ∣ u n ∣ |u_n| ∣un∣的下界使得梯度在 T − t T-t T−t个时间步后仍然有效。记最小的有效梯度为 ϵ \epsilon ϵ,则此时需要将权重初始化在区间 [ ϵ ( T − t ) , γ ( T − t ) ] [\sqrt[(T-t)]{\epsilon}, \sqrt[(T-t)]{\gamma}] [(T−t)ϵ,(T−t)γ]内。(注意,这里对关键结论有所省略,仅讨论激活函数为ReLU的情况)
将基本IndRNN单元和批归一化BN相结合作为一个原子单元,并将若干原子单元堆叠,可以组成更深的IndRNN网络。进一步,可以在纵向各层之间引入残差连接,进一步增强深层网络的稳定性。记第 l l l层第 t t t步的残差连接为 F l ( t ) \mathcal{F}_l^{(t)} Fl(t),第 l l l层第 t t t步的输出特征为 x l ( t ) x_l^{(t)} xl(t),有
x l ( t ) = x l − 1 ( t ) + F l ( t ) ( x l − 1 ( t ) ) x_l^{(t)} = x_{l-1}^{(t)} + \mathcal{F}_l^{(t)}\left(x_{l-1}^{(t)}\right) xl(t)=xl−1(t)+Fl(t)(xl−1(t))
或者可以将残差连接(相加操作)改成连接操作 C \mathcal{C} C,此时可以看做是将前面各层的特征都组合起来,即
x l ( t ) = C ( x l − 1 ( t ) , F l ( t ) ( x l − 1 ( t ) ) ) x_l^{(t)} = \mathcal{C}\left(x_{l-1}^{(t)}, \mathcal{F}_l^{(t)}\left(x_{l-1}^{(t)}\right)\right) xl(t)=C(xl−1(t),Fl(t)(xl−1(t)))
称为稠密连接IndRNN(densely connected IndRNN)。三种体系结构如下图所示
 IndRNN各时间步可独立计算 W x ( t ) \boldsymbol{Wx}^{(t)} Wx(t),而 u ⊙ h ( t − 1 ) \boldsymbol{u}\odot \boldsymbol{h}^{(t-1)} u⊙h(t−1)计算量较小,因此并行化得到了提高。实验表明IndRNN在序列极长(上千步)时仍然能快速收敛,且能叠加多层(12层)
IndRNN各时间步可独立计算 W x ( t ) \boldsymbol{Wx}^{(t)} Wx(t),而 u ⊙ h ( t − 1 ) \boldsymbol{u}\odot \boldsymbol{h}^{(t-1)} u⊙h(t−1)计算量较小,因此并行化得到了提高。实验表明IndRNN在序列极长(上千步)时仍然能快速收敛,且能叠加多层(12层)
ON-LSTM
尽管语言读写时展现出线性的表象,但是其底层结构并非线性,而是树形、分层的。将树形结构引入深度神经网络,可以获得一个分层的表示结果,而且可以对语言本身的组合现象建模,处理长期依赖问题。在统计自然语言处理中,使用有监督的句法分析器产生句法树,已经是一个经典方向,而且一些思想也被引入到了深度学习中。但是很多语言没有大量有标注的数据,一些领域里语言结构也不规则(例如推特),而且随着时间的变化语言结构也会缓慢改变。另一方面,让模型从语料中自动归纳语法仍然是一个开放性问题。[ShenYikang2018]提出了一种称为“有序神经元”(ordered neurons)的方法,通过无监督语法分析让高层神经元学习长期信息,而底层神经元学习短期信息。高层神经元和底层神经元通过控制神经元的更新频率来做区分:高层神经元更新更少,而底层更新更多。使用这种神经元构成的网络,称为ON-LSTM。ON-LSTM与语法树的关系大致如下图所示,图中最顶层节点只在第一步更新,代表了整个句子的信息;第二层节点在第1、2步更新,而第三层节点由于对应单词词性(语法树叶子节点),需要每步都被更新。节点的更新顺序是预先定义的,作为模型结构的一部分
 然而,经典LSTM各个节点的门控单元都是独立的,很难体现分层信息,因此需要修改来引入这种依赖关系。本文提出了一种新的激活函数 c u m a x \rm cumax cumax,定义为
然而,经典LSTM各个节点的门控单元都是独立的,很难体现分层信息,因此需要修改来引入这种依赖关系。本文提出了一种新的激活函数 c u m a x \rm cumax cumax,定义为
g ^ = c u m a x ( … ) = c u m s u m ( s o f t m a x ( … ) ) \hat{\boldsymbol{g}} = {\rm cumax}(\ldots) = {\rm cumsum}({\rm softmax}(\ldots)) g^=cumax(…)=cumsum(softmax(…))
其中 c u m s u m \rm cumsum cumsum为累加函数。该激活函数使得向量 g ^ \hat{\boldsymbol{g}} g^表现出一种二元门 ( 0 , … , 0 , 1 , … , 1 ) (0, \ldots , 0 ,1,\ldots, 1) (0,…,0,1,…,1)的形态,其可以将RNN神经元的状态分成两段,进而对两段使用不同的更新方法。记随机变量 d d d为 g ^ \hat{\boldsymbol{g}} g^两段的分隔点(第一次出现1的位置)。实际上, d d d就是 s o f t m a x ( … ) {\rm softmax}(\ldots) softmax(…)结果中最大分量所在的索引位置
就此,文章引入两个新的门,主遗忘门 f ~ ( t ) \tilde{\boldsymbol{f}}^{(t)} f~(t)和主更新门 i ~ ( t ) \tilde{\boldsymbol{i}}^{(t)} i~(t):(这里仍然是用 h \boldsymbol{h} h表示隐藏向量)
f ~ ( t ) = c u m a x ( W f ~ x ( t ) + U f ~ h ( t − 1 ) + b f ~ ) i ~ ( t ) = 1 − c u m a x ( W i ~ x ( t ) + U i ~ h ( t − 1 ) + b i ~ ) \begin{aligned} \tilde{\boldsymbol{f}}^{(t)} &= {\rm cumax}\left(\boldsymbol{W}_{\tilde{f}}\boldsymbol{x}^{(t)} + \boldsymbol{U}_{\tilde{f}}\boldsymbol{h}^{(t-1)} + \boldsymbol{b}_{\tilde{f}}\right) \\ \tilde{\boldsymbol{i}}^{(t)} &= 1 - {\rm cumax}\left(\boldsymbol{W}_{\tilde{i}}\boldsymbol{x}^{(t)} + \boldsymbol{U}_{\tilde{i}}\boldsymbol{h}^{(t-1)} + \boldsymbol{b}_{\tilde{i}}\right) \end{aligned} f~(t)i~(t)=cumax(Wf~x(t)+Uf~h(t−1)+bf~)=1−cumax(Wi~x(t)+Ui~h(t−1)+bi~)
其中主遗忘门是递增的(在某个位置之前的元素都是0,之后的元素都是1),而主更新门是递减的。整个ON-LSTM的更新规则为
f ( t ) = σ ( W f x ( t ) + U f h ( t − 1 ) + b f ) i ( t ) = σ ( W i x ( t ) + U i h ( t − 1 ) + b i ) o ( t ) = σ ( W o x ( t ) + U o h ( t − 1 ) + b o ) c ^ ( t ) = tanh ( W c x ( t ) + U c h ( t − 1 ) + b c ) f ~ ( t ) = c u m a x ( W f ~ x ( t ) + U f ~ h ( t − 1 ) + b f ~ ) i ~ ( t ) = 1 − c u m a x ( W i ~ x ( t ) + U i ~ h ( t − 1 ) + b i ~ ) ω ( t ) = f ~ ( t ) ∘ i ~ ( t ) f ^ ( t ) = f ( t ) ∘ ω ( t ) + ( f ~ ( t ) − ω ( t ) ) = f ~ ( t ) ∘ ( f ( t ) ∘ i ~ ( t ) + 1 − i ~ ( t ) ) i ^ ( t ) = i ( t ) ∘ ω ( t ) + ( i ~ ( t ) − ω ( t ) ) = i ~ ( t ) ∘ ( i ( t ) ∘ f ~ ( t ) + 1 − f ~ ( t ) ) c ( t ) = f ^ ( t ) ∘ c ( t − 1 ) + i ^ ( t ) ∘ c ^ ( t ) h ( t ) = o ( t ) ∘ tanh ( c ( t ) ) \begin{aligned} \boldsymbol{f}^{(t)} &= \sigma\left(\boldsymbol{W}_{ {f}}\boldsymbol{x}^{(t)} + \boldsymbol{U}_{ {f}}\boldsymbol{h}^{(t-1)} + \boldsymbol{b}_{ {f}}\right) \\ \boldsymbol{i}^{(t)} &= \sigma\left(\boldsymbol{W}_{ {i}}\boldsymbol{x}^{(t)} + \boldsymbol{U}_{ {i}}\boldsymbol{h}^{(t-1)} + \boldsymbol{b}_{ {i}}\right) \\ \boldsymbol{o}^{(t)} &= \sigma\left(\boldsymbol{W}_{ {o}}\boldsymbol{x}^{(t)} + \boldsymbol{U}_{ {o}}\boldsymbol{h}^{(t-1)} + \boldsymbol{b}_{ {o}}\right) \\ \hat{\boldsymbol{c}}^{(t)} &= \tanh\left(\boldsymbol{W}_{ {c}}\boldsymbol{x}^{(t)} + \boldsymbol{U}_{ {c}}\boldsymbol{h}^{(t-1)} + \boldsymbol{b}_{ {c}}\right) \\ \tilde{\boldsymbol{f}}^{(t)} &= {\rm cumax}\left(\boldsymbol{W}_{\tilde{f}}\boldsymbol{x}^{(t)} + \boldsymbol{U}_{\tilde{f}}\boldsymbol{h}^{(t-1)} + \boldsymbol{b}_{\tilde{f}}\right) \\ \tilde{\boldsymbol{i}}^{(t)} &= 1 - {\rm cumax}\left(\boldsymbol{W}_{\tilde{i}}\boldsymbol{x}^{(t)} + \boldsymbol{U}_{\tilde{i}}\boldsymbol{h}^{(t-1)} + \boldsymbol{b}_{\tilde{i}}\right) \\ \boldsymbol{\omega}^{(t)} &= \tilde{\boldsymbol{f}}^{(t)} \circ \tilde{\boldsymbol{i}}^{(t)} \\ \hat{\boldsymbol{f}}^{(t)} &= {\boldsymbol{f}}^{(t)} \circ {\boldsymbol{\omega}}^{(t)} + \left(\tilde{\boldsymbol{f}}^{(t)} - {\boldsymbol{\omega}}^{(t)}\right) = \tilde{\boldsymbol{f}}^{(t)} \circ \left({\boldsymbol{f}}^{(t)} \circ \tilde{\boldsymbol{i}}^{(t)} + 1 - \tilde{\boldsymbol{i}}^{(t)}\right) \\ \hat{\boldsymbol{i}}^{(t)} &= {\boldsymbol{i}}^{(t)} \circ {\boldsymbol{\omega}}^{(t)} + \left(\tilde{\boldsymbol{i}}^{(t)} - {\boldsymbol{\omega}}^{(t)}\right) = \tilde{\boldsymbol{i}}^{(t)} \circ \left({\boldsymbol{i}}^{(t)} \circ \tilde{\boldsymbol{f}}^{(t)} + 1 - \tilde{\boldsymbol{f}}^{(t)}\right) \\ \boldsymbol{c}^{(t)} &= \hat{\boldsymbol{f}}^{(t)} \circ {\boldsymbol{c}}^{(t-1)} + \hat{\boldsymbol{i}}^{(t)} \circ \hat{\boldsymbol{c}}^{(t)} \\ \boldsymbol{h}^{(t)} &= \boldsymbol{o}^{(t)} \circ \tanh \left(\boldsymbol{c}^{(t)} \right) \end{aligned} f(t)i(t)o(t)c^(t)f~(t)i~(t)ω(t)f^(t)i^(t)c(t)h(t)=σ(Wfx(t)+Ufh(t−1)+bf)=σ(Wix(t)+Uih(t−1)+bi)=σ(Wox(t)+Uoh(t−1)+bo)=tanh(Wcx(t)+Uch(t−1)+bc)=cumax(Wf~x(t)+Uf~h(t−1)+bf~)=1−cumax(Wi~x(t)+Ui~h(t−1)+bi~)=f~(t)∘i~(t)=f(t)∘ω(t)+(f~(t)−ω(t))=f~(t)∘(f(t)∘i~(t)+1−i~(t))=i(t)∘ω(t)+(i~(t)−ω(t))=i~(t)∘(i(t)∘f~(t)+1−f~(t))=f^(t)∘c(t−1)+i^(t)∘c^(t)=o(t)∘tanh(c(t))
其背后的直觉如下(假设所有主门每个元素都是0或1)
- 主遗忘门 f ~ ( t ) \tilde{\boldsymbol{f}}^{(t)} f~(t)控制模型的擦除行为。假设其分隔点为 d f ( t ) d_f^{(t)} df(t),根据 f ^ ( t ) \hat{\boldsymbol{f}}^{(t)} f^(t)和 c ( t ) \boldsymbol{c}^{(t)} c(t)的更新公式,前一个单元传来的状态 c ( t − 1 ) \boldsymbol{c}^{(t-1)} c(t−1)的前 d f ( t ) d_f^{(t)} df(t)个神经元都被擦除。在语法树中,这意味着前一个成分已经被处理完毕
- 主输入门 i ~ ( t ) \tilde{\boldsymbol{i}}^{(t)} i~(t)控制模型的写入行为。假设其分隔点为 d i ( t ) d_i^{(t)} di(t),该值若大则说明当前输入包含长期信息,需要保存若干个时间步
- 两个主门的逐元素乘积 ω ( t ) \boldsymbol{\omega}^{(t)} ω(t)表示它们交叠的部分。当交叠存在时,这一段里的神经元编码的成分是不完全的,通过标准LSTM来更新
(所以文章两个主门的作用是预测每一步的分隔点,通过分隔点控制信息的更新。分隔点的位置决定了两个0-1向量,但是0-1向量是离散的,不好求导,所以通过softmax来近似——这也是文章在4.1节后面文字所想表达的内涵?看了下面引用的苏剑林的博客,自己的一点概括,不一定准确)
由于主门只做大粒度的控制,因此可以让其维度小一点。设隐藏状态的维度为 D D D,这里所有主门的维度都是 D / C D/C D/C的,其中 C C C是一个超参数。在与LSTM遗忘门和输入门逐元素相乘时,将主门的每个分量重复 C C C次,即每 C C C个神经元由一个主门控制
实验表明,ON-LSTM不仅提高了语言模型的效果,还能无监督地学到句子的语法结构
ON-LSTM是ICLR 2019的最佳论文之一。本节仅是对原文做的一个简单记录,更详细的分析可以参考苏剑林:ON-LSTM用有序神经元表达层次结构
Mogrifier LSTM
Mogrifier LSTM[Melis2019]期望通过引入额外的门控机制,使得模型对当前输入的信息能够结合上文进行缩放,进而得到一个受上文影响的输入表示。对于原始的LSTM,输入门 i ( t ) {\boldsymbol{i}}^{(t)} i(t)可以看做是对 c ~ ( t ) \tilde{\boldsymbol{c}}^{(t)} c~(t)的每行都做了一个放缩(不看非线性操作 tanh \tanh tanh)(因为 c ( t ) \boldsymbol{c}^{(t)} c(t)的更新里有一项是 c ~ ( t ) ⊙ i ( t ) \tilde{\boldsymbol{c}}^{(t)} \odot {\boldsymbol{i}}^{(t)} c~(t)⊙i(t))。Mogrifier LSTM更进一步,使得LSTM的所有权重矩阵 W \boldsymbol{W} W和 U \boldsymbol{U} U的每一列都被缩放一个因子,且缩放程度和上下文相关。具体地,在计算各个门之前,Mogrifier LSTM让输入 x ( t ) \boldsymbol{x}^{(t)} x(t)(简记为 x \boldsymbol{x} x)和上一步隐藏状态 h ( t − 1 ) \boldsymbol{h}^{(t-1)} h(t−1)(记为 h p r e v \boldsymbol{h}_{\rm prev} hprev)交互影响,即
M o g r i f y ( x , c p r e v , h p r e v ) = L S T M ( x ↑ , c p r e v , h p r e v ↑ ) x ↑ 和 h p r e v ↑ 是 如 下 迭 代 过 程 最 终 一 步 的 结 果 x i = 2 σ ( Q i h p r e v i − 1 ) ⊙ x i − 2 f o r o d d i ∈ [ 1 … r ] h p r e v i = 2 σ ( R i x i − 1 ) ⊙ h p r e v i − 2 f o r e v e n i ∈ [ 1 … r ] x − 1 = x , h p r e v 0 = h p r e v \begin{aligned} {\rm Mogrify}(\boldsymbol{x}, \boldsymbol{c}_{\rm prev}, \boldsymbol{h}_{\rm prev}) &= {\rm LSTM}(\boldsymbol{x}^{\uparrow}, \boldsymbol{c}_{\rm prev}, \boldsymbol{h}_{\rm prev}^{\uparrow}) \\ \boldsymbol{x}^{\uparrow}和\boldsymbol{h}_{\rm prev}^{\uparrow}是如下&迭代过程最终一步的结果 \\ \boldsymbol{x}^i &= 2\sigma\left(\boldsymbol{Q}^i\boldsymbol{h}_{\rm prev}^{i-1}\right) \odot \boldsymbol{x}^{i-2} \ \ \ \ {\rm for\ odd\ }i \in [1\ldots r] \\ \boldsymbol{h}^i_{\rm prev} &= 2\sigma\left(\boldsymbol{R}^i\boldsymbol{x}^{i-1}\right) \odot \boldsymbol{h}^{i-2}_{\rm prev} \ \ \ \ {\rm for\ even\ }i \in [1\ldots r] \\ \boldsymbol{x}^{-1} &= \boldsymbol{x},\ \boldsymbol{h}_{\rm prev}^0 = \boldsymbol{h}_{\rm prev} \end{aligned} Mogrify(x,cprev,hprev)x↑和hprev↑是如下xihprevix−1=LSTM(x↑,cprev,hprev↑)迭代过程最终一步的结果=2σ(Qihprevi−1)⊙xi−2 for odd i∈[1…r]=2σ(Rixi−1)⊙hprevi−2 for even i∈[1…r]=x, hprev0=hprev
r ∈ N r\in \mathbb{N} r∈N是模型的超参数,定义迭代过程的轮数。当 r = 0 r=0 r=0时,Mogrifier LSTM退化为标准LSTM。为了减少模型参数,通常将 Q i \boldsymbol{Q}^i Qi和 R i \boldsymbol{R}^i Ri分解成两个低秩矩阵的乘积。实践表明, r r r为5或6,低秩矩阵的秩在40到90之间时,效果最好。文章尝试了两种变体,分别为
- Q i \boldsymbol{Q}^i Qi和 R i \boldsymbol{R}^i Ri使用满秩矩阵
- x i \boldsymbol{x}^i xi更新时不再依赖前一次迭代的 h p r e v i − 1 \boldsymbol{h}_{\rm prev}^{i-1} hprevi−1,而是都依赖初始的 h p r e v \boldsymbol{h}_{\rm prev} hprev。 h p r e v i \boldsymbol{h}_{\rm prev}^{i} hprevi同理
两种变体效果都不太好
本文在PTB和MWC两个语言模型任务上进行了实验,都取得了不错的效果。此外,文章通过“逆序拷贝”任务(读入一个字符串,遇到某个特殊字符时,倒序输出所有接收到的输入),验证模型的确可以根据上下文放大输入表示中有用的信息,减少无用的信息,从而降低输入嵌入矩阵的维度
最后,文章认为以下几项假说不能解释mogrifier的有效性,包括
- “Mogrifier LSTM受益于对 x \boldsymbol{x} x和 h p r e v \boldsymbol{h}_{\rm prev} hprev进行缩放”:否。对LSTM做缩放,且使缩放因子可学习,并没有提升LSTM的效果
- “Mogrifier LSTM受益于让优化过程更容易”:否。没有观察到
- “常见的语言模型正则化手段之一是让输入输出共享词嵌入矩阵,这个限制太大,而mogrifier放松了这样的限制”:否。分开学习输入输出嵌入矩阵,mogrifier仍然有效
- “Mogrifier LSTM受益于低秩矩阵分解”:否。使用满秩矩阵虽然降低了效果,但是仍然比普通LSTM好
- “Mogrifier LSTM在罕见词上表现更佳”:否。逆序拷贝任务不存在罕见词问题,mogrifier LSTM效果仍然更好
- “Mogrifier LSTM只在英语上效果好”:否。MWC(多语Wiki数据集)的效果推翻了这种说法
- “Mogrifier LSTM更能处理长距离依赖”:否。在句子级语言模型上mogrifier LSTM效果也很好
参考文献
- [Mujika2017] Mujika, A., Meier, F., & Steger, A. (2017). Fast-slow recurrent neural networks. In Advances in Neural Information Processing Systems (NeurIPS 2017) (pp. 5915-5924).
- [Campos2017] Campos, V., Jou, B., Giró-i-Nieto, X., Torres, J., & Chang, S. F. (2017). Skip rnn: Learning to skip state updates in recurrent neural networks. arXiv preprint arXiv:1708.06834. (Published in ICLR 2018).
- [YangZhilin2017] Yang, Z., Dai, Z., Salakhutdinov, R., & Cohen, W. W. (2017). Breaking the softmax bottleneck: A high-rank RNN language model. arXiv preprint arXiv:1711.03953. (Published in ICLR 2018).
- [YangZhilin2019] Yang, Z., Luong, T., Salakhutdinov, R. R., & Le, Q. V. (2019). Mixtape: Breaking the Softmax Bottleneck Efficiently. In Advances in Neural Information Processing Systems (NeurIPS 2019) (pp. 15922-15930).
- [LiShuai2018] Li, S., Li, W., Cook, C., Zhu, C., & Gao, Y. (2018). Independently recurrent neural network (indrnn): Building a longer and deeper rnn. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR2018) (pp. 5457-5466).
- [ShenYikang2018] Shen, Y., Tan, S., Sordoni, A., & Courville, A. (2018). Ordered neurons: Integrating tree structures into recurrent neural networks. arXiv preprint arXiv:1810.09536.
- [Melis2019] Melis, G., Kočiský, T., & Blunsom, P. (2019). Mogrifier lstm. arXiv preprint arXiv:1909.01792. (Pulished in ICLR 2020)