面试题(数据库)
凡事预则立不预则废,面试前准备下笔试题吧。
以下摘录于程序员面试宝典
1.数据库
1.1存储过程和函数的区别是什么?
存储过程是用户定义的一系列SQL语句的集合,涉及特定表或其他对象的任务,用户可以调用存储过程。
而函数通常是数据库已定义的方法,他接受参数并返回某种类型的值,并且不涉及特定的用户表
1.2什么是数据库事务?
数据库事务是指作为单个逻辑工作单元执行的一系列操作,这些操作要么全做,要么全不做,是一个不可分割的工作单元。
事务的开始与结束用户可以显式控制,如果用户没有显示的定义事务,则由DBMS按照默认规定自动划分事务。事务具有原子性,一致性,独立性,持久性等特点。
- 事务的原子性指的是一个事务要么全部执行,要么全部不执行
- 一致性就是在一个用户未提交他的事务前(比如更新一个字段),其他用户 Select 出来的结果都一样
- 事务的独立性是指一个事务的执行不能其它事务干扰
- 事务的持久性是指事务运行成功以后,就系统的更新是永久的。不会无缘无故的回滚。
- 替换单引号,即把所有的单引号改成双引号,防止攻击者修改sql语句
- 删除用户输入内容的所有连字符,防止攻击者获取权限
- 用户不同的用户执行查询,添加,修改,删除操作,由于隔离了不同账户的可执行操作,因此也就防止了原本用于执行select命令的地方变成了insert,update,delete
- 用存储过程执行所有的查询
- 检查用户输入的合法性
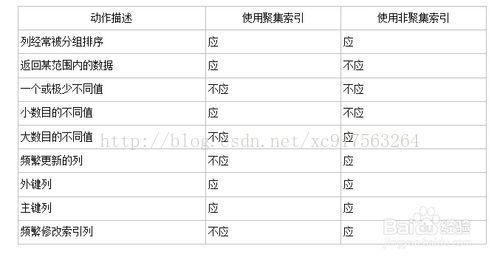
1.6解释聚集索引和非聚集索引的区别?
其中聚集索引表示表中存储的数据按照索引的顺序存储,检索效率比非聚集索引高,但对数据更新影响较大。非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置,非聚集索引检索效率比聚集索引低,但对数据更新影响较小。
一个通俗的举例,说明两者的区别
其实,我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
2.SQL语言
2.1找出表ppp里面num最小的数,不能使用min函数
select top 1 num from ppp order by num
2.2找出ppp里面最小的数,可以使用min函数
select * from ppp where num in(select min(num) from ppp)
2.3选择表ppp2中num重复的记录
select * from ppp2 where num in
(
select num from ppp2 group by num having (count(num) > 1)
)
2.4写出复制表,拷贝表和四表联查的SQL语句
源表名A,新表明:B
复制表:select * into B from A where 1 = 0
拷贝表:select * into B from A
四表联查:select * from A,B,C,D where 条件
2.5在SQLServer中如何创建临时表
create table #temp(字段1 类型,字段2 类型....)
2.6有数据表A,有一个字段add_time,如果要查询最新的时间记录,如何写SQL语句?
select * from A where add_time =
(
select max(add_time) from A
)
2.7有一个数据库,只有一张表,包含1000条数据,你能想出一种解决方法,把第五到第七行的记录取出来吗?
create table #temp
(id int)
declare @i int
set @i = 0
while(@i < 10)
begin
insert into #temp(id) values(@i)
set @i = @i + 1
end
select top 3 id from #temp
where id in
(
select top 7 id from #temp
)
order by id desc
2.8请问下列语句是否可以正常运行,为什么?
update table1 set name = (select name from table2 t1 inner join table1 t2 on t1.id = t2.id)
where name is null
不能,因为select name from table2 t1 inner join table1 t2 on t1.id = t2.id,这一句返回的是一个结果集,而update语句少了条件句。返回的是结果集,会出现非一对一的情况。
3.SQL语言客观题
3.1下面哪个SQL语句描述了每一个部门的每个工种的工资最大值?
A.select dept_id, job_cat,max(salary) from employees where salary > max (salary);
B.select dept_id, job_cat,max(salary) from employees group by dept_ id, job_cat;
C.select dept_id, job_cat,max(salary) from employees;
D.select dept_id, job_cat,max(salary) from employees group by dept_id;
E.select dept_id, job_cat,max(salary) from employees group by dept_ id, job_cat,salary;
答案:B
group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面(重要)
3.2以下是学生表的字段描述:
sid_id,number,start_date,date,end_date
关于对start_date字段的使用,以下哪两个函数是合法的?
A.sum(start_date)
B.avg(start_date)
C.count(start_date)
D.avg(start_date,end_date)
E.min(start_date)
F.maximum(start_date)
答案:C,E。
count(start_date)等同于count(数字),min(start_date)得到最小的日期
3.3以下哪两种约束的情况下,Oracle数据库会隐性创建一个唯一索引?
A.not null
B.primary
C.foreign key
D.check
E.unique
答案:B,E。
主键和唯一约束。
3.4在select语句中包括一个where关键词,请问group by关键词一般在select语句中什么位置?
A.immediately after the select clause(紧跟select关键词之后)
B.before the where clause(在where关键词之前)
C.before the from clause(在from关键词之前)
D.after the order by clause(在order by关键词之后)
E.after the where clause(在where关键词之后)
答案:E
group by语句在where 关键字之后。
3.5在select语句中包括一个where关键词,请问order by关键词一般在select语句中什么位置?
A.immediately after the select clause(紧跟select关键词之后)
B.before the where clause(在where关键词之前)
C.after all clause(在所有关键词之后)
D.after the where clause(在where关键词之后)
E.before the from clause(在from关键词之前)
答案:C
order语句在所有语句最后
3.6对比下面两个SQL语句。
Select last_name,salary from employees order by salary;
Select last_name,salary from employees order by 2 asc;
A.the same result(相同的结果)
B.different result(不同的结果)
C.the second statement returns a syntax error(第二个结果会显示错误)
答案:A
order by 列号,但是数字不可以使用0,也不可以超出查询的列
3.7如果你想把时间显示成像“20051110 14:44:17”这样的格式,下面哪个select语句应该被使用?
A.select to_date(sydate,'yearmmdd hh:mm:ss')from dual;
B.select to_char(sydate,'yearmonthday hh:mi:ss')from dual;
C.select to_date(sydate,'yyyymmdd hh24:mi:ss')from dual;
D.select to_char(sydate,'yyyymmdd hh24:mi:ss')from dual;
E.select to_char(sydate,'yy-mm-dd hh24:mi:ss')from dual;
答案:D
3.8 下面哪一个是DML(Data Manipulation Language,数据操纵语言)的执行状态?
A.commit
B.merge
C.update
D.delete
E.creat
F.drop
答案:C,D。
3.9 Select语句中用来连接字符串的符号是______。
A.+
B.&
C.||
D.|
答案:A
3.10下列哪个选项防止两个部门(相同名称)被分配在DEPTID字段,但允许NULL值?
A.ALTER TABLE department ADD CONSTRAINT dpt_cst PRIMARY KEY(改变department表,增加主键约束)
B.CREATE INDEX dpt_idx ON department(deptid)(创建department索引)
C.ALTER TABLE department ADD CONSTRAINT dpt_cst UNIQUE(创建唯一约束)
D.CREATE UNIQUE INDEX dpt_idx ON department(deptid) --(在department唯一索引)
解析:A选项有主键,肯定不允许为NULL。B、D选项也显然不对。
unique约束能够约束一列保证该列值唯一,但允许该列有空值。故选C。
答案:C
对于SQLserver而言,唯一约束和唯一索引是同一个概念
以下转载自http://blog.csdn.net/johnstrive/article/details/41677441
创建唯一索引保证了往表中插入重复索引列值的操作都会失败。如果一个单独的sql语句试图往表中插入包含重复索引列值的数据行,sql server将不会插入以上所有行。例如,当一个insert操作试图把从表A中取出的20行插入到表B,而其中的10行跟索引列值重复的话,默认情况下以上20行都不会被插入。然而,如果把索引对应的 “忽略重复键”开关打开的话,包含重复数值的行不会被插入,而非重复数值行会被插入。也就是说,其中的10行会被插入。
约束则没有这一开关,因此定义了一个约束之后,只要有与定义列重复值的行,插入都将被拒绝。