Java学习总结 1-1-3 J.U.C并发编程包详解
笔记记录,整理的有点乱,建议全屏,否则排版可能会很奇怪~~
Lock锁
获取锁的几种方式:
void lock(); 不死不休
boolean tryLock(); 浅尝辄止
boolean tryLock(long time, TimeUnit unit)throws InterruptedException; 过时不候
void localInterruptibly() throws InterruptedException; 任人摆布
释放锁:
void unlock;
lock最常用,localInterruptibly一般比较昂贵,有的impl可能还没有实现locakInterruptibly(),只有真的需要效应中断时才使用
Condition:new ReentrantLock().newCondition()
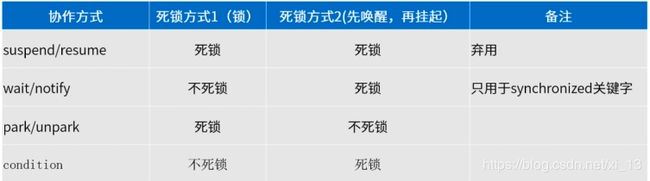
Condition必须在加锁之后使用await或signal方法,Condition可以有多个
wait/await:线程等待时同时拥有释放锁的语义
ReentrantLock:互斥锁
ReentrantLock有两个重要的属性实现,owner、count和waiterrs,表示当前哪个线程加的锁、加锁的次数和抢锁失败等待
的队列。加锁的次数需要和解锁的次数相同
owner:保存当前持有锁线程的引用
count:加锁次数,解锁次数需与加锁次数相同,否则锁不处于可以被争抢的状态
waiterrs:抢锁失败进入队列,进入该队列的线程将进行等待(Watting状态),等待持有锁的线程执行完自动唤醒
Synchronized:
优点:1、使用简单,语义清晰,
2、由JVM提供,提供了多种优化方案(锁粗化、锁消除、偏向锁、轻量级锁)
3、锁的释放由虚拟机来完成,不用人工干预,也降低了死锁的可能性
缺点:无法实现一些锁的高级特性:公平锁、中断锁、超时锁、读写锁、共享锁
Lock:
优点:可实现锁的高级特性:公平锁、中断锁、超时锁、读写锁、共享锁等等
缺点:需手动释放锁unlock,使用不当可能会造成死锁
ReaadWriteLock :读写锁(适用于读取操作多于写入的场景,改进互斥锁的性能。例:集合的并发线程安全新改造、缓存组件)
维护一对关联,一个只用于读操作,一个只用于写操作;读操作可以由多个读线程同时持有,写锁是排他的。同一时间,两
把锁不能被不同线程持有 当线程争抢读锁时,首先判断写锁值是否为零,为零则获取读锁。争抢写锁时首先判断读锁值是
否为零,为零则判断写锁是否为零,为零则持有该锁,修改writeCount和owner,争抢失败的线程进入waiterrs队列进入等
待状态,等持有锁的线程执行完后唤醒队列头部的线程
readCount:读锁的线程数,可被多个线程持有,数字随线程数累加
writeCount:写锁重入的次数 ,同一时刻只能被一个线程持有但可被重入多次,解锁次数需与加锁次数相同
owner:保存当前持有锁线程的引用,只用于写锁,读线程占有锁时该值为null
waiterrs:抢锁失败进入队列,进入该队列的线程将进行等待(Watting状态),等待持有锁的线程执行完自动唤醒
锁降级:
指写锁降级成为读锁。持有写锁的同时,在获取读锁,随后释放写锁的过程。写锁是线程独占,读锁是共享,所以
写-->读是降级。(读->写是不能实现的)
并发类容器Map
HashMap、ConcurrentHashMap
HashMap:线程不安全
怎么存储的,结构是什么?
1.7:Entry
扩容:resize(int newCapacity)方法,将数组版里的元素重新哈希到新的数组里,在原数组达元素个数到长度的0.75倍
时(不是数组的长度),扩容大小到原来的两倍
1.8:Entry
扩容时只是修改引用,并非复制数据
怎么查找数据,算法?
1.7:先把Entry的Key值取Hash值,然后取模,计算的结果作为数组的下标判断该下表对应的位置是否有元素,如果没
有新建节点存储,如果有则遍历链表所有元素,便利时如果遇到相同key则替换,否则在便利完后添加新的节点
1.8:过程和1.7大同小异,只是在链表元素>=8时转为红黑树,便利的是红黑树而不是普通的链表
两种Map初始化大小时指定map长度最好为16的整倍数,不指定默认为16
ConcurrentHashMap:线程安全的HashMap
怎么存储的,结构是什么?
1.7:segments[] + Hashtablle,数组+链表。数组的每个元素都是特殊的hashtable,采用分段锁的机制提供并发访问,
数组长度一经初始化不会变。扩容不是针对、segmennts数组来讲。根据Hash值获取需要存放在数组哪个角标(即
哪个Hashtable),来存储数据
1.8:数组 + 链表: 添加元素时,计算hash值取模得到数组的下标,如果该下标的元素为空,通过CAS操作在该下标位
置新建node,吧元素存入链表的头部,若失败则重新检查该下标是否为空,不为空则添加synchronzed对整个链
表添加锁来添加元素,链表元素到8之后转换为红黑树
相比1.7,1.8的ConcurrentHashMap优势?
1.7采用的Hashtable数据结构比较重,数组长度一经初始化不能被改变,对并发量增大不友好,hashtable内元素无限增
大,导致效率变低。
1.8采用数据较简单的数据结构,可扩容,并且只对数组所在下标的链表做锁,锁住的数据力度较小,并发支持较好
ConcurrentSkipListMap:有顺序的key,线程安全的TreeMap
跳表结构:
List Set Queue
List:数组结构、有序、元素可重复
ArrayList:
存储结构:数组(Object[] elementData)、非线程安全
初始化长度:不指定默认为0,不指定长度下第一次调用add方法重新计算数组长度并赋值为10
扩容机制:
添加时数组元素个数(size)+1后大于数组长度时扩容
1、计算原数组长度1.5倍的长度作为扩容后的数组长度
2、调用JDK的数组复制方法(Arrays.copyOf(Object[],int capacity);)将原数组内容复制到新创建的数组并重新赋值给
elementData
CopyOnWirteArrayList:
在高并发下要求ArrayList具有线程安全的时候,无非采用synchronized和互斥锁(ReadWriteLock)两种方式,
synchronized效率太低不考虑,ReadWriteLock在读多写少时可能会出现在执行一个写操作时,加上写锁之后同一时间大
量读操作被阻塞无法执行,所以引入CopyOnWrite思想。
CopyOnWirte思想:
CopyOnWrite可被理解为“使用拷贝的副本执行写操作”,原数组用Volatile修饰,在需要修改数组里元素时,先拷贝这个
数组做为副本,写操作只对副本进
行(CAS操作),一旦写操作执行完成之后,将副本赋值给原数组引用,达到对读线程即时可见
扩容机制:添加时进行扩容,每次长度只扩容1
缺点:将数据全量复制,占用空间且浪费性能
优点:读写分离,读时不需要锁
Set:K,V结构、无序、元素不可重复
HashSet:基于HashMap实现,非线程安全
CopyOnWriteArraySet:基于CopyOnWirteArrayList实现,线程安全
添加时校验元素是否已存在,只添加未存在的元素,所以元素不可重复
ConcurrentSkipListSet:基于ConcurrentSkipListMap实现,线程安全,有序,查询快
Queue(队列、管道结构):先进先出
栈(半封闭结构):后进先出
Queue API:
非阻塞 API:对队列操作时不等待,如果得不到期望的结果则返回null
offer:添加一个元素并返回true,对列已满则返回false
poll :移除并返回对列头部的元素,对列为空则返回null
peek :返回对列头部的元素,对列为空则返回null
阻塞 API :对队列操作时得不到期望的结果则一直等待
put :添加一个元素,队列满则等待
take:移除并返回列头部的元素
不常用(非阻塞):
add:增加一个元素,队列满则抛异常
remove:移除并返回列头部的元素,队列为空则抛异常
element:返回对列头部的元素,队列为空则抛异常
ArrayBlockIngQueue:阻塞、线程安全
结构:数组 + putIndex + takeIndex + couunt,以数组形式实现对列,两个下标实现先进先出,count为当前数组内的元素
个数。内部维护一个数组,putIndex和takeIndex默认为0,通过构造函数指定数组容量大小
put():添加元素时
当添加元素(调用put()方法)时,若count和元素的长度相等(数组已满)则移入等待对列(notFull.await()),否则
通过读取putIndex获取数组下标使元素添加至相应位置并修改putIndex值为下个元素应存放的位置(putIndex+1)修
改后大于数组本身下标时则重置为0并记录元素个数(count++),并唤醒notEmpty线程;
take():删除元素时
删除元素(调用take()方法)时,若如果数组为空则移入等待对列(notEmpty.await());反之通过读取takeIndex获
取数组下标删除元素并修改takeIndex值为下个元素应存放的位置(takeIndex+1),修改后大于数组本身下标时则重
置为0并记录元素个数(count—-),同时唤醒notFull线程
LinkedBlockingQueue:链表、阻塞、线程安全
结构:链表、线程安全
维护一个链表,初始化不指定大小则默认为Intrger.MAX_VALUE,与ArrayBlockingQueue主要的区别是,
LinkedBlockingQueue在插入数据和删除数据时分 别是由两个不同的lock(takeLock和putLock)来控制线程安全的,
也由这两个lock生成了两个对应的condition(notEmpty和notFull)来实现可阻塞的插入和删除数据
put():添加元素时
当添加元素时,添加至链表的头部,如果队列已满,则阻塞当前线程,将其移入等待队列。若队列满足插入数据的条
件,则通知被阻塞的生产者线程(notFull.signal();)
take():删除元素时
当删除元素时:若当前队列为空,则阻塞当前线程,将其移入到等待队列中,直至满足条件。否则移除对列头元素;
如果当前满足移除元素的条件,则通知被阻塞的消费者线程
ArrayBlockIngQueue和LinkedBlockingQueue比较:
相同点:ArrayBlockingQueue和LinkedBlockingQueue都是通过condition通知机制来实现可阻塞式插入和删除元素,并满
足线程安全的特性;
不同点:1、ArrayBlockingQueue底层是采用的数组进行实现,而LinkedBlockingQueue则是采用链表数据结构;
2、ArrayBlockingQueue插入和删除数据,只采用了一个lock,而LinkedBlockingQueue则是在插入和删除分别
采用了putLock和takeLock,这样可以降低线程由于线程无法获取到lock而进入WAITING状态的可能性,从而
提高了线程并发执行的效率。