在Dalvik虚拟机对dex的加载过程的基础上,我们来分析下面代码中的第三步。
/dalvik/vm/native/dalvik_system_DexFile.cpp
static void Dalvik_dalvik_system_DexFile_openDexFileNative(const u4* args,
JValue* pResult)
{
StringObject* sourceNameObj = (StringObject*) args[0];
StringObject* outputNameObj = (StringObject*) args[1];
DexOrJar* pDexOrJar = NULL;
JarFile* pJarFile;
RawDexFile* pRawDexFile;
char* sourceName;
char* outputName;
sourceName = dvmCreateCstrFromString(sourceNameObj);
if (outputNameObj != NULL)
outputName = dvmCreateCstrFromString(outputNameObj);
else
outputName = NULL;
// 1、尝试把它当做一个后缀为.dex的DEX文件进行打开,得到RawDexFile结构数据
// 2、如果打开失败,则把它当做一个包含有classes.dex文件的Zip文件进行打开,得到JarFile结构数据
if (hasDexExtension(sourceName)
&& dvmRawDexFileOpen(sourceName, outputName, &pRawDexFile, false) == 0) {
pDexOrJar = (DexOrJar*) malloc(sizeof(DexOrJar));
pDexOrJar->isDex = true;
pDexOrJar->pRawDexFile = pRawDexFile;
pDexOrJar->pDexMemory = NULL;
} else if (dvmJarFileOpen(sourceName, outputName, &pJarFile, false) == 0) {
ALOGV("Opening DEX file '%s' (Jar)", sourceName);
pDexOrJar = (DexOrJar*) malloc(sizeof(DexOrJar));
pDexOrJar->isDex = false;
pDexOrJar->pJarFile = pJarFile;
pDexOrJar->pDexMemory = NULL;
}
if (pDexOrJar != NULL) {
pDexOrJar->fileName = sourceName;
// 3、把pDexOrJar这个结构体中的内容加到gDvm中的userDexFile结构的hash表中,以便dalvik以后的查找
addToDexFileTable(pDexOrJar);
} else {
free(sourceName);
}
free(outputName);
RETURN_PTR(pDexOrJar);
}
可以看到DexOrJar文件最终添加到gDvm中的userDexFile结构的hash表中,下面我们来具体查看addToDexFileTable方法。
static void addToDexFileTable(DexOrJar* pDexOrJar) {
/*
* Later on, we will receive this pointer as an argument and need
* to find it in the hash table without knowing if it's valid or
* not, which means we can't compute a hash value from anything
* inside DexOrJar. We don't share DexOrJar structs when the same
* file is opened multiple times, so we can just use the low 32
* bits of the pointer as the hash.
*/
u4 hash = (u4) pDexOrJar;
void* result;
dvmHashTableLock(gDvm.userDexFiles);
result = dvmHashTableLookup(gDvm.userDexFiles, hash, pDexOrJar,
hashcmpDexOrJar, true);
dvmHashTableUnlock(gDvm.userDexFiles);
if (result != pDexOrJar) {
ALOGE("Pointer has already been added?");
dvmAbort();
}
pDexOrJar->okayToFree = true;
}
需要说明的是,gDvm是一个DvmGlobals结构的全局变量。在DvmGlobals结构中有一个成员HashTable* userDexFiles;
DvmGlobals在/dalvik/vm/Globals.h中
也就是说,userDexFiles是一个HashTabled的引用,HashTabled的结构为:
/dalvik/vm/Hash.h
struct HashTable {
int tableSize; /* must be power of 2 */
int numEntries; /* current #of "live" entries */
int numDeadEntries; /* current #of tombstone entries */
HashEntry* pEntries; /* array on heap */
HashFreeFunc freeFunc;
pthread_mutex_t lock;
};
HashEntry* pEntries指向一个HashEntry的数组,HashEntry结构体中的data变量存放的就是pDexOrJar。
/dalvik/vm/Hash.h
struct HashEntry {
u4 hashValue;
void* data; //DexOrJar *pDexOrJar
};
上面代码的关键就是dvmHashTableLookup方法,所以我们继续查看该方法。
/dalvik/vm/Hash.cpp
void* dvmHashTableLookup(HashTable* pHashTable, u4 itemHash, void* item,
HashCompareFunc cmpFunc, bool doAdd)
{
HashEntry* pEntry;
HashEntry* pEnd;
void* result = NULL;
assert(pHashTable->tableSize > 0);
assert(item != HASH_TOMBSTONE);
assert(item != NULL);
/* jump to the first entry and probe for a match */
pEntry = &pHashTable->pEntries[itemHash & (pHashTable->tableSize-1)];
pEnd = &pHashTable->pEntries[pHashTable->tableSize];
while (pEntry->data != NULL) {
if (pEntry->data != HASH_TOMBSTONE &&
pEntry->hashValue == itemHash &&
(*cmpFunc)(pEntry->data, item) == 0)
{
/* match */
//ALOGD("+++ match on entry %d", pEntry - pHashTable->pEntries);
break;
}
pEntry++;
if (pEntry == pEnd) { /* wrap around to start */
if (pHashTable->tableSize == 1)
break; /* edge case - single-entry table */
pEntry = pHashTable->pEntries;
}
//ALOGI("+++ look probing %d...", pEntry - pHashTable->pEntries);
}
if (pEntry->data == NULL) {
if (doAdd) {
pEntry->hashValue = itemHash;
pEntry->data = item;
pHashTable->numEntries++;
/*
* We've added an entry. See if this brings us too close to full.
*/
if ((pHashTable->numEntries+pHashTable->numDeadEntries) * LOAD_DENOM
> pHashTable->tableSize * LOAD_NUMER)
{
if (!resizeHash(pHashTable, pHashTable->tableSize * 2)) {
/* don't really have a way to indicate failure */
ALOGE("Dalvik hash resize failure");
dvmAbort();
}
/* note "pEntry" is now invalid */
} else {
//ALOGW("okay %d/%d/%d",
// pHashTable->numEntries, pHashTable->tableSize,
// (pHashTable->tableSize * LOAD_NUMER) / LOAD_DENOM);
}
/* full table is bad -- search for nonexistent never halts */
assert(pHashTable->numEntries < pHashTable->tableSize);
result = item;
} else {
assert(result == NULL);
}
} else {
result = pEntry->data;
}
return result;
}
上面的操作就是将pDexOrJar以及它对应的hashValue封装到一个HashEntry,然后将这个HashEntry存放到HashEntry* pEntries指向的HashEntry数组中去。
他们之间的整个引用过程如下图所示:
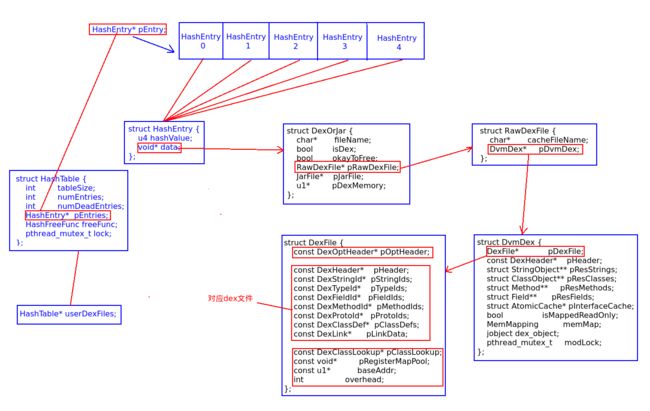
也就是说我们可以通过gDvm.userDexFiles找到具体DexOrJar的位置,然后通过DexOrJar的pRawDexFile定位到RawDexFile的位置,进而通过RawDexFile的pDvmDex找到DvmDex的位置,最终就可以通过DvmDex的pDexFile来定位到DexFile的位置,它就是内存中的.odex文件内容,它里面同时也包含了.dex的内容。
参考文章:
http://bbs.pediy.com/thread-207190.htm