数据分析岗前景分析-拉勾网爬虫
目的
近年来随着人工智能和大数据的发展,数据分析岗也越发火热;想了解目前市场上数据分析岗对人才的需求状况、行业薪资及未来发展前景等,爬取拉勾网数据分析相关岗位近2700条数据做了一次分析
写作步骤
- 数据采集
- 数据清洗
- 数据可视化
- 结论
数据采集
因为拉钩反爬严重,因此用了代理IP、加了请求头,并创建了session对象进行请求,直接附上代码
#调用相关模块,其中pymysql是为了将爬到的数据存到mysql
import requests
import time
import random
import pymysql
# 打开数据库连接
db = pymysql.connect('localhost','root','root','kkb')
# 获取cursor来操作数据库
cursor = db.cursor()
# 创建一张数据表(注:此操作也可在mysql完成)
sql = """create table la_gou(
company_name varchar(30),
company_short_name varchar(20),
city varchar(20),
district varchar(20),
company_size varchar(20),
company_field varchar(20),
company_stage varchar(20),
education varchar(20),
position_name varchar(20),
position_advantage varchar(30),
work_year varchar(20),
salary varchar(20),
position_id varchar(20))"""
# 使用 execute() 方法执行 SQL
cursor.execute(sql)
#创建session对象
session = requests.Session()
#在网上找的代理IP,防止IP被封爬取失败
proxie = [
"134.249.156.3:82",
"1.198.72.239:9999",
"103.26.245.190:43328"]
proxies = {'http':random.sample(proxie,1)}
#添加请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, image / webp, image / apng, * / *;q = 0.8, application / signed - exchange;v = b3',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88?labelWords=&fromSearch=true&suginput='}
url_start = 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88?labelWords=&fromSearch=true&suginput='
session.get(url_start,headers = headers,timeout = 5)
time.sleep(5)
n = 0
list_position = ['数据分析师','数据分析助理','数据分析专家','数据分析专员','数据分析主管','数据分析']
for i in list_position:
for j in range(1,31):
url_params = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
data = {
'irst': 'true',
'pn': str(j),
'kd':i
}
res_position = session.post(url_params,data = data,headers = headers,proxies = proxies,timeout = 5)
time.sleep(5)
json_position = res_position.json()
positions = json_position['content']['positionResult']['result']
time.sleep(5)
for position in positions:
company_name = position['companyFullName']
company_short_name = position['companyShortName']
city = position['city']
district = position['district']
company_size = position['companySize']
company_field = position['industryField']
company_stage = position['financeStage']
education = position['education']
position_id = position['positionId']
position_name = position['positionName']
position_advantage = position['positionAdvantage']
work_year = position['workYear']
salary = position['salary']
n = n + 1
print('正在抓取第' + str(n) + '条')
sql = 'insert into la_gou (company_name,company_short_name,city,district,company_size,company_field,company_stage,education,position_name,position_advantage,work_year,salary,position_id) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,(company_name,company_short_name,city,district,company_size,company_field,company_stage,education,position_name,position_advantage,work_year,salary,position_id))
db.commit()
print('数据插入成功')
except:
db.rollback()
print('数据插入错误')
db.close()
数据清洗
使用jupyter,调用python中的pymysql,pandas模块完成数据清洗,并将清洗后的数据存入mysql
#调用模块
import pymysql
import pandas as pd
# pandas读取mysql中的数据
#创建数据库连接
conn = pymysql.connect(host = 'localhost',port = 3306,user = 'root',password = 'root',db = 'kkb',charset = 'utf8')
sql = 'select company_short_name,city,district,company_size,company_field,company_stage,education,position_id,position_name,position_advantage,work_year,salary from la_gou'
df = pd.read_sql(sql,conn)
df.head()
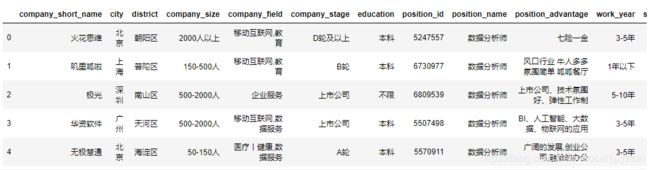
#查看数据概览
df.info()

通过查看数据,发现共有2679条数据,且无空值,接下来需要查看数据有无重复
# 根据position_id查看数据重复情况
pd.unique(df['position_id']).size
#删除重复数据
df.drop_duplicates('position_id',inplace=True)
查看去重后结果
df.count()

去重后只剩781条数据,数据重复情况还是比较严重的
# 根据岗位名称判断是否为数据分析相关岗位
word = '数据分析'
for x in df['position_name']:
df['result'] = word in x
print(df['result'].value_counts())
![]()
判断都是数据分析相关岗位,进行下一步
#薪资是一个区间,不方便后续分析,需要拆分后取平均值作为衡量标准,同时将单位去掉
df['low_salary'] = df['salary'].str.split('-',expand=True)[0]
df['low_salary'] = df['low_salary'].str.replace('k','').str.replace('K','')
df['high_salary'] = df['salary'].str.split('-',expand=True)[1]
df['high_salary'] = df['high_salary'].str.replace('k','').str.replace('K','')
#转换数据类型,将薪资从字符串转为整数
df['high_salary'] = df['high_salary'].astype('int')
df['low_salary'] = df['low_salary'].astype('int')
#计算平均薪资
df['average_salary'] = (df['high_salary']+df['low_salary'])/2

#公司所属行业这一列,先将所有的分隔符统一为逗号,然后对数据进行分列,并将分列后第一列数据命名为company_field_new
company_field_clean = df['company_field'].str.replace('丨',',').str.replace('、',',').str.replace(' ',',')
df['company_field_new'] = company_field_clean.str.split(',',expand = True)[0]
df['company_field_new'].value_counts()

#数据概览
df.info()

#将数据存入mysql
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:root@localhost:3306/kkb?charset=utf8")
con = engine.connect()
df.to_sql(name='lagou_cleans', con = con, if_exists='append', index=False)
至此数据无空值、重复、数据类型问题,数据清洗完成
数据可视化
使用tableau与mysql建立连接,将清洗后的数据读入tableau,并做可视化图表进行分析

从以下三个层面展开分析
-
岗位需求情况

从上图可以看到,北京的需求遥遥领先位居榜首,其次为上海、深圳、广州、杭州;如果想转行数据分析,优先考虑这几个城市,需求大机会多。

通过词云图可以看到,数据分析主要集中在移动互联网、电商、金融等领域;另外由于我们爬的是拉钩的招聘信息,而拉钩本身主要关注的就是互联网领域,所以数据不够全面,后续需要改进。
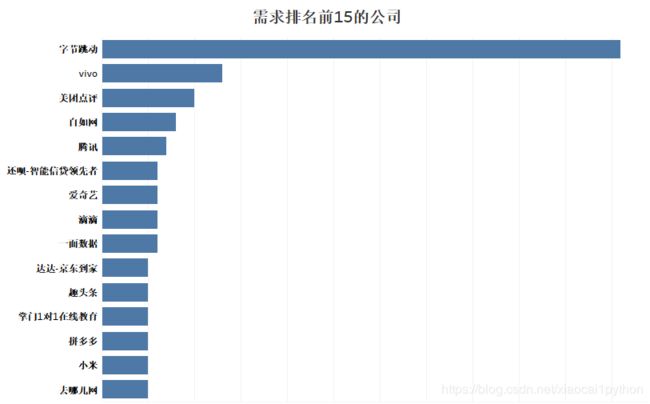
可以看到公司规模越大,对数据分析的需求也越大,其中上市公司和不需要融资的公司需求占到了近50%;同时由占比可以看出,随着公司规模扩大,需求也在快速增长;同时再看需求排名靠前的公司,都是如字节跳动、美团、腾讯这样的大型互联网公司。
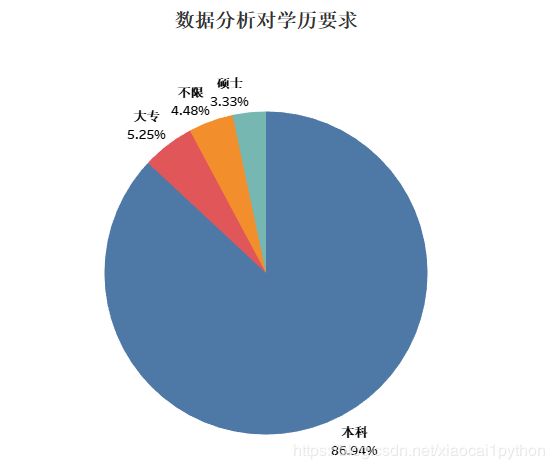

可以看到,数据分析对学历的要求并不高,大部分只要达到本科学历即可;工作经验方面,3-5年的分析师需求最大,1-3年的需求量也不小,所以想从事数据分析应该尽早入行积累经验。 -
行业薪资水平
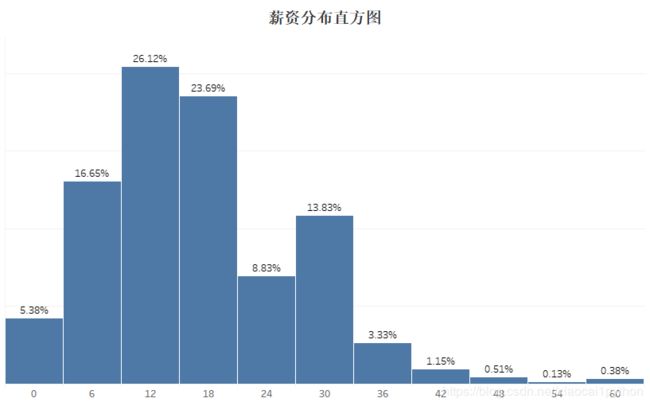
从直方图可以看到,数据分析岗月工资大部分集中在12-24k,占比达50%;6-12k占比次之,但36K以上占比极小(极少数人能拿到超高薪资),总体来说薪资待遇还不错。
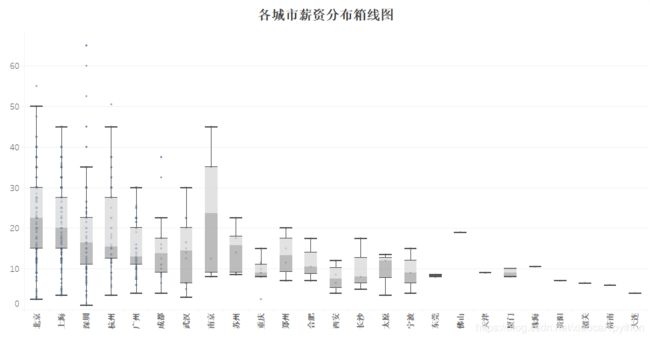
通过箱线图,发现南京的中位数略高于北京,通过核实数据发现南京的总数据只有6条,且有一条招聘薪资很高极大地拉高了中位数,因此南京的数据有些片面。抛开这个,可以看到北京市薪资分布的中位数略高于20k,居全国首位,其次是上海、深圳、杭州,约在15-20k之间,而广州略低,大概为13k左右,结合此前的城市岗位需求情况,综合来看,北京具有绝对优势。 -
薪资影响因素
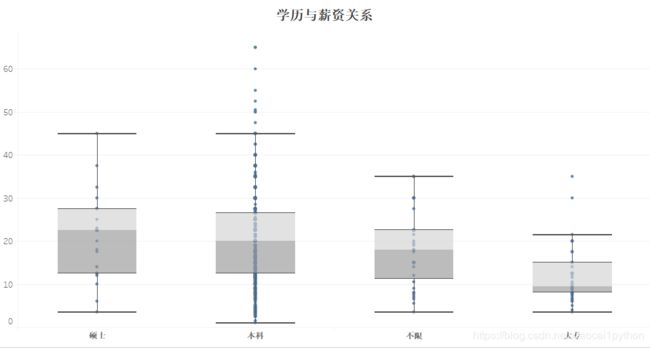
通过箱线图可以看到,硕士薪资中位数为22k,本科为20k,硕士略高于本科,但薪资最大、最小值等其他指标基本都差不多,而大专中位数只有9.5,相差较大。总的来说,学历与薪资成正比,学历越高薪资越高,但是本科和硕士薪资差距不大。
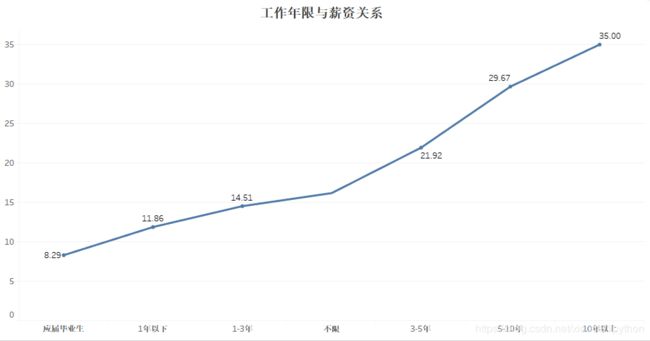
薪资随工作年限的增加,呈线性增长,但是增长速度不同;3年是一个分水岭,3年以下处在增长技能、积累经验的阶段,薪资增长缓慢,3年以上,薪资涨幅很大,完全上了一个层次;所以数据分析是一个比较看重经验的行业,需要静下心好好积累提升。

从行业平均薪资来看,硬件、人工智能、社交等领域工资偏高,旅游、医疗、广告营销等行业工资最低,移动互联网、金融、电商处在中等偏上的水平;结合前面行业岗位需求情况,可以说移动互联网、电商、金融依然是值得选择的行业。
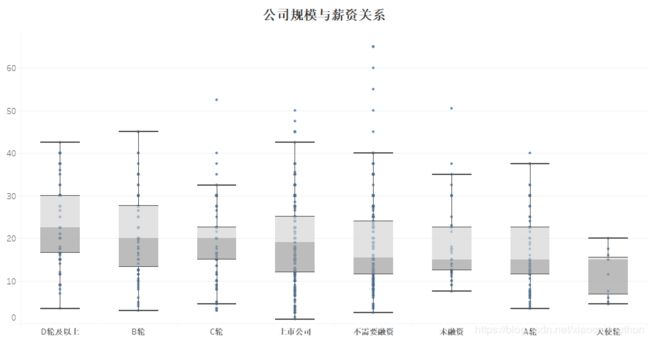
从公司规模来看,大公司平均薪资是具有一定优势的,薪资上升的空间很大;但是B轮、C轮公司的中位数和D轮、上市公司中位数差距不大,所以在进不了大厂的情况下,争取去一个中型企业也是不错的选择。
分析结论
1、从总体薪资来看,数据分析这一行业薪资普遍较高,大部分集中在12-24k,应届生平均薪资也能达到8k左右;同时随着工作经验的积累,薪资上升空间很大,3年是一个分水岭,3年以下处在增长技能、积累经验的阶段,薪资增长缓慢,3年以上,薪资涨幅很大,完全上了一个层次;所以数据分析是一个比较看重经验的行业,需要静下心好好积累提升。
2、数据分析对学历的要求不高比较看重经验,大部分达到本科学历即可;大概是因为数据分析主要是依托于业务解决业务中遇到的问题,所以比较看重经验。
3、城市选择上,在综合城市平均薪资和岗位需求的情况下,北上深广杭都是不错的城市,需求和薪资均居于前列,北京具有绝对优势。
4、行业选择上,移动互联网、电商、金融需求大,薪资也处于中上水平,可优先考虑。
5、最后在公司选择上,优先进大厂进不了的情况下优先选择中型企业,规模越大发展空间越大。