Python|爬取网页图片流程及语法解释
转自:https://www.toutiao.com/a6584948674021818884/?tt_from=mobile_qq&utm_campaign=client_share×tamp=1533210652&app=news_article&utm_source=mobile_qq&iid=39055545733&utm_medium=toutiao_ios
爬取网页图片的基本流程是:
1 使用urllib.request模板请求返回网页文本;
2 从网页文本中使用正则表达式筛选出img src地址(返回一个全部src的列表);
3 图片文件逐一检索或复制;
代码:
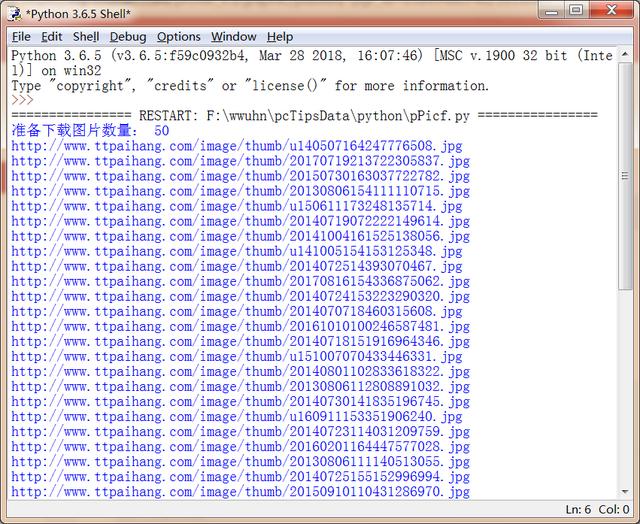
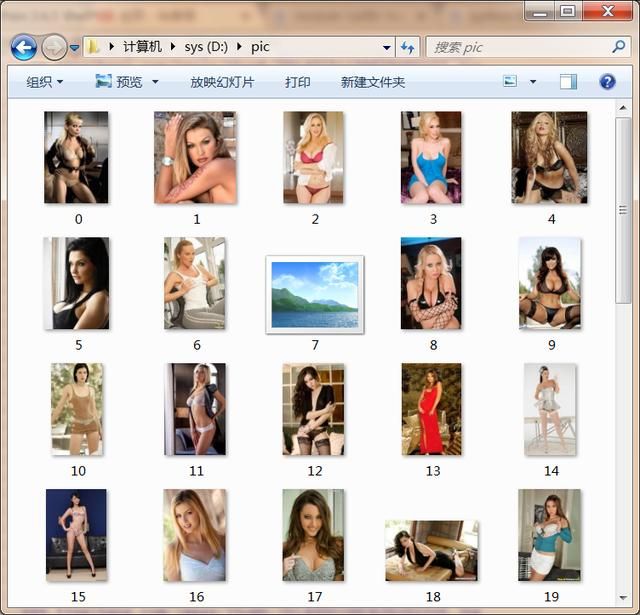
运行效果:
附代码1:
import re
import urllib.request
import os
#1 抓取网页
#url = 'http://www.kgc.cn/list'
url = 'http://www.ttpaihang.com/vote/rank.php?voteid=1410&page=2'
req = urllib.request.urlopen(url)
buf = req.read()
req.close()
#2 获取图片地址
i = url.find("/",9) # 本句及下面三句截取url的前半截
url2 = url
if i > 0 :
....url2 = url[:i]
#buf = buf.decode('UTF-8')
buf = buf.decode('gb2312')
#listurl = re.findall(r'http:.[^"]+.jpg',buf)
listurl = re.findall(r'img src=.[^"]+.jpg',buf)
for i in range(len(listurl)):.... # 把字符img src="去掉
....listurl[i]=listurl[i].replace('img src="',"")
....if not re.match("http",listurl[i]):
........listurl[i]=url2 + listurl[i]
....print(listurl[i])
#3 抓取图片并保存到本地
i = 0
fpath = "D:\pic2\"
if not os.path.isdir(fpath):
....os.mkdir(fpath)
for url in listurl:
....f=open(fpath + str(i)+'.jpg','wb')
....req = urllib.request.urlopen(url)
....buf = req.read()
....f.write(buf)
....f.close()
....i+=1
........
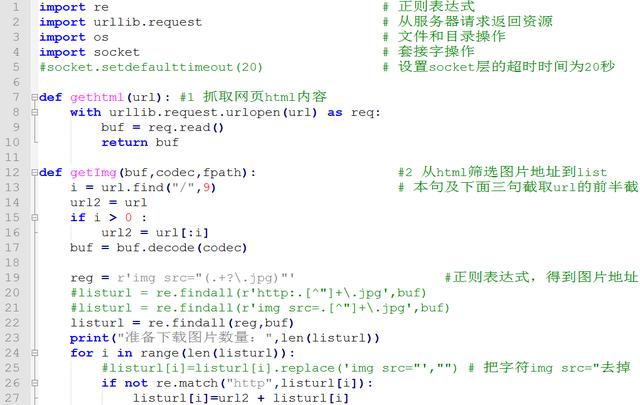
附代码2(写成函数的形式)
import re .... .... .... .... # 正则表达式
import urllib.request .... .... # 从服务器请求返回资源
import os .... .... .... .... # 文件和目录操作
import socket .... .... .... .... # 套接字操作
#socket.setdefaulttimeout(20)....................# 设置socket层的超时时间为20秒
def gethtml(url): #1 抓取网页html内容
....with urllib.request.urlopen(url) as req:
........buf = req.read()
........return buf
def getImg(buf,codec,fpath): #2 从html筛选图片地址到list
....i = url.find("/",9)............................ # 本句及下面三句截取url的前半截
....url2 = url
....if i > 0 :
........url2 = url[:i]
....buf = buf.decode(codec)
....
....reg = r'img src="(.+?.jpg)"'....#正则表达式,得到图片地址
....#listurl = re.findall(r'http:.[^"]+.jpg',buf)
....#listurl = re.findall(r'img src=.[^"]+.jpg',buf)
....listurl = re.findall(reg,buf)
....print("准备下载图片数量:",len(listurl))
....for i in range(len(listurl)):................
........#listurl[i]=listurl[i].replace('img src="',"") # 把字符img src="去掉
........if not re.match("http",listurl[i]):
............listurl[i]=url2 + listurl[i]
........print(listurl[i])
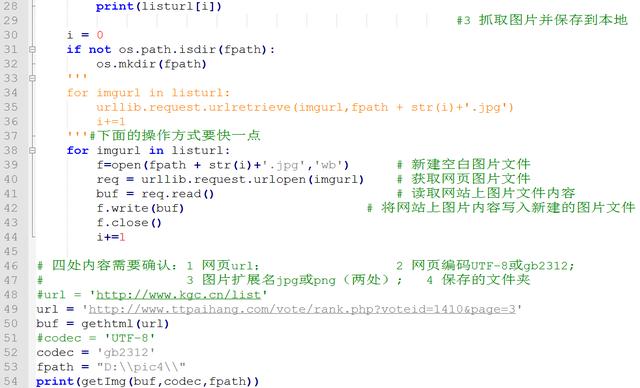
............#3 抓取图片并保存到本地
....i = 0
....
....if not os.path.isdir(fpath):
........os.mkdir(fpath)
....'''
....for imgurl in listurl:
........urllib.request.urlretrieve(imgurl,fpath + str(i)+'.jpg')
........i+=1
....'''#下面的操作方式要快一点
....for imgurl in listurl:
........f=open(fpath + str(i)+'.jpg','wb') # 新建空白图片文件
........req = urllib.request.urlopen(imgurl) # 获取网页图片文件
........buf = req.read().... .... .... # 读取网站上图片文件内容
........f.write(buf).... .... .... # 将网站上图片内容写入新建的图片文件
........f.close()
........i+=1
# 四处内容需要确认:1 网页url; .... ....2 网页编码UTF-8或gb2312;
#................ 3 图片扩展名jpg或png(两处); 4 保存的文件夹
#url = 'http://www.kgc.cn/list'
url = 'http://www.ttpaihang.com/vote/rank.php?voteid=1410&page=3'
buf = gethtml(url)
#codec = 'UTF-8'
codec = 'gb2312'
fpath = "D:\pic4\"
print(getImg(buf,codec,fpath))
-End-