【python&爬虫】快速入门Scrapy框架
一.基本介绍
Scrapy是用纯Python实现的一个开源爬虫框架,是为了高效地爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛,可用于爬虫开发,数据挖掘,数据监测,自动化测试等领域。
二.Scrapy框架的架构
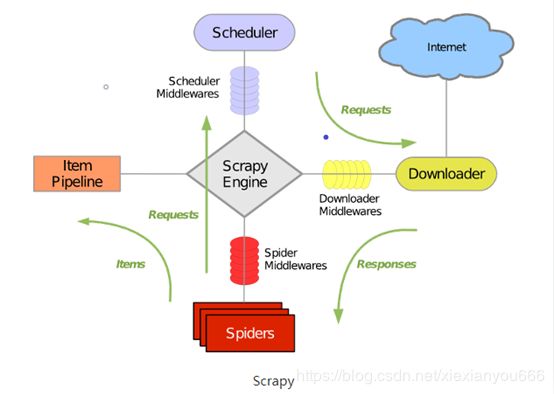
Scrapy框架包含以下组件
1.Scrapy Engine(引擎):负责Spider,Item Pipeline,DownLoader,Scheduler之间的通信,包括信号和数据的传递
2.Scheduler(调取器):负责接收引擎发送过来的Requests请求,并按照一定的方式进行整理排列和入队,当引擎需要时,交还给引擎
3.Downloader(下载器):负责下载Scrapy Engine发送过来的Requests请求;并将其获取到的Response(响应)交还给引擎,由引擎交给Spider处理
4.Spider(爬虫):负责处理所有的Response,从中提取分析数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler调取器
5.Item Pipeline(管道):负责处理Spider中获取的Item数据,并进行后期处理(详细分析,过滤,存储等)
6.Downloader Middlewares(下载中间件):是一个可以自定义扩展下载功能的组件
7.Spider Middlewares(Spider中间件):是一个自定义扩展的Scrapy Engine和Spiders中间通信的功能组件 (例如:进入Spider的Response和从Spider出去的Requests)
小结:Spider的这些组件通力合作,共同完成整个爬取任务。首先从URL开始,Scheduler调度器会将其交给Downloader进行下载,下载之后会交给Spiders进行分析。Spider分析出来的结果有两种:一种是需要进一步爬取的链接,例如之前分析“下一页”链接,这些URL会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline,这是对数据进行后期处理(详细分析,过滤,存储等)。另外,在数据流动通道里还可以安装各种中间件,进行必要的处理。
三.Scrapy安装
pip install scrapy
四.Scrapy基本操作
1.创建Scrapy项目
scrapy startproject 项目名称
2.在项目中创建爬虫
需要先进入scrapy项目中
scrapy genspider 爬虫名称 "爬取的域名"
3.Scrapy项目目录结构
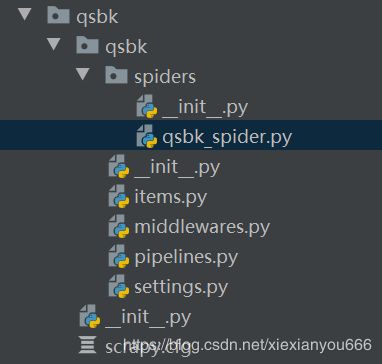
1.Items.py 用于存放爬取下来的数据模型
2.middlewares.py 用于存放各种中间件文件
3.pipelines.py 用于将items模型存放到本地磁盘
4.setting.py 本爬虫的一些配置信息(比如请求头,多久发一次请求,ip代理池等)
5.scrapy.cfg 项目配置文件
6.spiders包 以后的爬虫都是存放在这个文件里面
五.入门案例
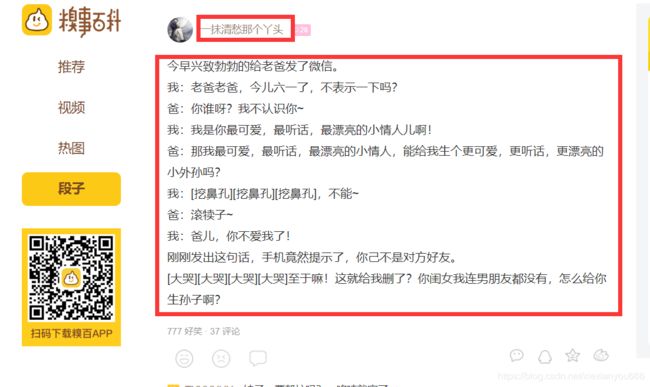
1.案例简介
爬取糗事百科段子中的标题的内容
2.代码演示
qsbk_spider.py (爬虫)
# -*- coding: utf-8 -*-
import scrapy
# 将QsbkItem导入过来,用于封装项目字段
from qsbk.items import QsbkItem
from scrapy.http.response.html import HtmlResponse
from scrapy.selector.unified import SelectorList
class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider'
# allowed_domains = ['aa.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# contents 的数据类型是SelectorList
contents = response.xpath('//div[@class="col1 old-style-col1"]/div')
for content in contents:
# content 类型:Selector
# get方法 序列化并返回单个unicode字符串中的匹配节点。未引用百分比编码内容。
# title 类型:List
title = content.xpath('./div[@class="author clearfix"]/a[2]/h2/text()').get().strip()
# getall()返回匹配的所有节点,并以列表的形式返回
detail = content.xpath('.//div[@class="content"]//text()').getall()
detail = "".join(detail).strip()
# 创建一个字典,用于返回爬取结果
item = QsbkItem(title = title,detail = detail)
# item = {"title":title,"detail":detail}
# yield可以将函数变成生成器,可以将结果一个一个的返回到爬虫引擎
yield item
# 找到下一页的url
next_url = response.xpath('//ul[@class="pagination"]/li[last()]/a/@href').get()
# 判断是否找到最后一页
if not next_url:
return
else:
# 拼接出完整的url链接
url1 = "https://www.qiushibaike.com" + next_url
# 请求下一页
yield scrapy.Request(url1,callback=self.parse)
item.py
import scrapy
class QsbkItem(scrapy.Item):
# 此处用于定义项目的字段,使得代码更加规范
# 固定写法
title = scrapy.Field()
detail = scrapy.Field()
pipelines.py (存储数据)
将爬取下来的数据保存成json文件格式有三种方式
方式一:直接存入json文件
import json
class QsbkPipeline(object):
def __init__(self):
# 构造方法用于打开一个文件,也可以在open_spider方法中打开文件
self.file = open("./糗事段子.json","w",encoding="utf-8")
def open_spider(self,spider):
# 爬虫开始时会执行这行代码
print("爬虫开始")
# 这个方法用于处理爬虫引擎返回过来的结果
def process_item(self, item, spider):
# 因为item被QsbkItem类包装,所有要先转换成字典,才能被dumps成json格式
# 将返回过来的数据 dumps成json格式
# ensure_ascii = False表示不适用ascii码,即可正常显示中文
item_json = json.dumps(dict(item),ensure_ascii=False)
self.file.write(item_json+"\n")
return item
def close_spider(self,spider):
# 爬虫结束时会执行这行代码
print("爬虫结束")
方式二:使用JsonItemExporter存储
# 数据先存储到内存中,爬虫结束后,统一存储到文件
from scrapy.exporters import JsonItemExporter
class QsbkPipeline(object):
def __init__(self):
# 构造方法用于打开一个文件,也可以在open_spider方法中打开文件
# 因为这个模块是以二进制的方式写入,所以文件需要用二进制的方式打开
self.file = open("./糗事段子.json","wb")
# 创建一个导出对象
self.exports = JsonItemExporter(self.file,ensure_ascii=False,encoding="utf-8")
# 打开到处对象
self.exports.start_exporting()
def open_spider(self,spider):
# 爬虫开始时会执行这行代码
print("爬虫开始")
# 这个方法用于处理爬虫引擎返回过来的结果
def process_item(self, item, spider):
# 将数据存入
# 用这种方式就不需要将item转换成字典了
# 存储格式为列表,列表中的每一项时字典
# 这种方式会先把数据统一存储导内存中,然后最后统一存储导磁盘,比较费内存
self.exports.export_item(item)
return item
def close_spider(self,spider):
# 关闭exporters对象
self.exports.finish_exporting()
# 爬虫结束时会执行这行代码
print("爬虫结束")
方式三:使用JsonLinesItemExporter存储
# 每行每行的写入文件,跟第一种方式存储方式一样
from scrapy.exporters import JsonLinesItemExporter
class QsbkPipeline(object):
def __init__(self):
# 构造方法用于打开一个文件,也可以在open_spider方法中打开文件
# 也需要使用二进制的方式打开
self.file = open("./糗事段子.json", "wb")
self.exporters = JsonLinesItemExporter(self.file, ensure_ascii=False, encoding="utf-8")
def open_spider(self, spider):
# 爬虫开始时会执行这行代码
print("爬虫开始")
# 这个方法用于处理爬虫引擎返回过来的结果
def process_item(self, item, spider):
# 写入数据
self.exporters.export_item(item)
return item
def close_spider(self, spider):
# 关闭文件
self.file.close()
# 爬虫结束时会执行这行代码
print("爬虫结束")
这三种存储方式小结:
1.打开文件,将item转换成json格式,然后一个一个写入到文件(常规方式)
2.使用scrapy自带类存储JsonItemExporter和JsonLinesItemExporters两种方式
(1)JsonItemExporters:这个是每次把数据添加到内存中,最后统一写入到磁盘。好处是:存储的是一个满足json规则的数据,坏处是,如果数据大时,比较耗内存
(2)JsonLinesItemExporters:这个是每次调用export_item时,就把这个item存储到磁盘中。坏处时每个字典就是一行,整个文件不是满足json格式的文件。好处是每次处理数据的时候就直接写入到了磁盘,不会耗内存,比较安全
六.案例小结
1.response是一个scrapy.http.response.html.HtmlResponse对象,可以执行xpath css语法来提取数据
2.提取出来的数据是一个Selector或者SelectorList对象,如果想获取其中的字符串,那么应该执行get或者getall方法
3.getall方法,用于获取selector中所有的文本,返回一个列表
4.get方法,获取Selector中第一个方法,返回一个str类型
5.如果数据解析回来,要传给pipeline处理,那么可以使用yield来返回,也可以搜集所有的item,最后存入列表统一用return返回
6.item 建议在Items.py中定义好模型,以后不要使用字典返回
7.pipeline,这个专门用于保存数据的,其中有三个方法比较常用:
(1)open_spider(self,spider) 爬虫被打开时会被调用
(2)process_spider(self,item,spider) 爬虫将item转过来时会被调用
(3)close_spider(self,spider) 爬虫结束时会被调用
注意:要使用pipeline, 需要在setting.py中激活pipeline,并设置ITEM_PIPELINES